算力服务行业研究报告
2026-07-03 12:48
算力服务行业研究报告
一、算力服务行业概述
(一)算力服务的方式
算力服务是伴随人工智能大模型爆发而快速崛起的新型服务业态。中国信息通信研究院在2026年发布的《智能算力服务研究报告(2026年)》中,首次构建了智能算力服务三层体系架构,将算力服务划分为三类核心服务形态:智能算力资源服务、智能算力互联互通服务和智能算力应用服务。云端算力服务是当前市场规模最大的形态,用户通过互联网按需租用算力资源,无需自行采购硬件设备。这种模式以阿里云、华为云、百度智能云等公有云服务商为代表,用户按使用量付费,弹性伸缩,适合需要灵活算力调度、不愿承担硬件采购成本的场景。本地化部署服务则面向对数据安全、合规性要求较高的政企客户,将算力设备部署在客户自有数据中心或专属机房内。这种模式下,客户一次性采购硬件设备,获得物理隔离的计算环境,数据不出域,满足金融、政务、医疗等行业对数据安全的高要求。混合部署服务介于两者之间,将核心敏感数据在本地处理,非敏感计算任务上云,兼顾安全性与灵活性。从服务层级来看,算力服务还可以分为IaaS(基础设施即服务,提供裸算力资源)、PaaS(平台即服务,提供AI开发平台和工具链)和MaaS(模型即服务,提供预训练大模型的API调用)三个层次。随着大模型从训练阶段走向应用阶段,MaaS的市场占比正在快速提升。(二)算力服务行业的发展背景
算力服务行业的爆发式增长,源于几个相互叠加的结构性因素。第一,AI大模型训练与推理需求的指数级增长。根据中国信通院数据,2026年一季度国内AI算力需求同比暴涨417%,而供给增速仅为128%。供需缺口持续扩大,成为推动算力服务市场量价齐升的核心驱动力。德勤研报显示,2026年推理任务将占据全球AI总计算负载的三分之二。从Token消耗量来看,根据全球头部AI聚合平台OpenRouter的统计数据,国内AI大模型周Token调用量已连续七周稳居全球第一,达14.19万亿Token,环比增长27.49%。第二,数据隐私保护与合规要求推动本地化部署需求。政府、金融、医疗等行业对数据安全有严格要求,数据不出域是基本底线。这些行业无法将核心数据上传至公有云进行处理,必须采用本地化部署方案。随着《数据安全法》《个人信息保护法》等法规的落地实施,本地化部署算力服务的需求持续增长。第三,企业从“买设备”到“买服务”的模式转变。对于大多数中小企业而言,自行采购GPU服务器、搭建算力基础设施不仅资金门槛高,还需要配备专业的运维团队。算力租赁和服务化交付模式大幅降低了企业使用AI的门槛,使得算力从“资本性支出”转变为“运营性支出”。第四,国产算力替代的政策驱动。在高端GPU芯片出口管制的背景下,国产算力芯片(如华为昇腾、寒武纪、海光等)正在快速替代进口产品。2025年国产算力芯片在政务、金融领域的渗透率预计超过40%。国产算力生态的成熟,为算力服务行业提供了多样化的硬件选择。(三)算力服务行业的规模与增长
从智能算力规模来看,根据IDC和浪潮信息联合发布的报告,2025年中国智能算力规模预计达1037.3EFLOPS,较2024年增长43%;2026年将达1460.3EFLOPS,为2024年的两倍。2023年至2028年中国智能算力规模的五年年复合增长率预计达46.2%。2025年中国人工智能算力市场规模达到259亿美元,较2024年增长36.2%。从算力租赁市场规模来看,据科智咨询数据,中国智能算力租赁市场规模(以EFLOPS计)从2024年的377EFLOPS增长到2025年的632EFLOPS,2026年预计达984EFLOPS。从价值量看,中国算力租赁市场规模从2024年的约1480亿元增长到2025年的约2116亿元,预计2026年能达到2600亿元上下。据中国信通院测算,2025年我国智能算力服务市场规模已突破1300亿元。从供需关系来看,供给紧张态势仍在持续。英伟达H100/B200等高端芯片在全球范围内持续供不应求。根据SemiAnalysis发布的H100一年期租赁合约价格指数,H100的租赁价格从2025年10月每GPU小时1.70美元的低点,已飙升至2026年3月的每GPU小时2.35美元,涨幅接近40%。国内市场上,H100月租站稳5.5至6.0万元区间,新签合同的交付排期普遍延至2027年上半年。即便近期价格持续上涨,已锁定按需实例的用户也不愿将产能释放回市场,部分2至3年前签署的H100租赁合约正以原价完成续约,甚至直接续签至2028年。二、算力服务提供商的主要类型与代表企业
算力服务提供商的阵营正在快速分化,根据服务模式和业务重心的不同,可以划分为三大类型:公有云算力服务商、本地化部署算力服务商和算力一体机提供商。三类企业在服务形态、客户群体和商业模式上各有侧重。(一)公有云算力服务商
公有云算力服务商依托大规模的数据中心和云计算基础设施,向用户提供按需付费的算力租赁服务。其核心优势在于资源池化、弹性伸缩和全栈服务能力。1.阿里云
阿里云是中国AI云市场的绝对领导者。据Omdia发布的《中国AI云市场份额2025》报告,2025年中国AI云整体市场规模约为567亿元人民币,其中IaaS占比约69%。阿里云在AI云上的收入超过216亿元,市场份额达38.1%,位列第一,超过第二至第四名总和。阿里云的核心技术能力体现在其全栈算力服务体系上。在底层硬件层面,阿里云拥有自研AI芯片“含光”系列,并深度适配英伟达、AMD等主流GPU;在平台层面,阿里云提供PAI(人工智能平台)一站式AI开发平台,覆盖数据处理、模型训练、模型部署的全流程;在模型层面,阿里云通义大模型系列已迭代多个版本,提供MaaS服务。阿里云还构建了“百炼”模型服务平台,聚合了数十个主流大模型,用户可以通过API调用各类模型能力。从财务表现来看,2025年阿里云全年营收达1466亿元,同比增长28.6%,经调整EBITA利润率达8.8%。2026财年第二季度(对应2025年第三自然季),阿里云单季度营收达398亿元,同比增长34%,AI相关产品收入连续9个季度实现三位数同比增长。阿里巴巴在过去四个季度对AI+云基础设施的资本开支约1200亿元。高盛预测阿里云在2026财年和2027财年的收入增速将分别提升至23%和25%。2.华为云
华为云是中国第二大云服务商,其核心竞争力在于“昇腾+鲲鹏”的全栈自主算力体系。据Canalys数据,2025年第一季度华为云实现18%的营收同比增长,市场份额提升至18%。在AI云市场,华为云以13.1%的市场份额位居第三。华为云的技术差异化在于从芯片到应用的全栈自研能力。底层昇腾AI处理器是国内性能最强的AI芯片之一,已承建超过20个国家级智算中心;中层CANN(ComputeArchitectureforNeuralNetworks)软件栈已全面开源,正在构建独立的AI计算生态;上层盘古大模型已迭代至5.5版本,覆盖自然语言处理、计算机视觉、多模态学习、预测分析与科学计算五大核心领域,推理效率提升达8倍。为进一步壮大生态,华为云还发布了1.5亿元的生态激励计划,聚焦昇腾AI服务、GaussDB数据库等方向。3.百度智能云
百度智能云在大模型和AI云服务领域具有显著的技术先发优势。2025年全年,百度智能云基础设施收入约为200亿元,同比增长34%。其中,AI高性能计算设施收入的订阅收入在第四季度同比增长143%。从更宽口径看,百度AI云业务2025年全年营收达300亿元。百度智能云的核心竞争力在于其“芯片-框架-模型-应用”的四层全栈AI架构。底层昆仑芯AI芯片已规划M100(2026年上市,针对大规模推理场景)和M300(2027年上市,面向超大规模多模态模型训练推理)两代产品【昆仑芯信息】;中层飞桨(PaddlePaddle)深度学习框架是国内使用最广泛的AI开发框架;上层文心大模型系列已迭代多个版本。在市场竞争中,百度智能云在2025年全年大模型相关招标项目中,中标项目数及中标金额均居行业首位,连续两年蝉联该领域的“标王”。4.市场格局总结
中国AI云市场格局已趋于固化。2025年,阿里云以35.8%的份额位居第一,火山引擎、华为云、腾讯云分别占14.8%、13.1%、7%,前四强合计占据超过四分之三的市场份额。这一格局意味着中小云服务商在通用算力服务领域难以突破头部企业的规模效应和生态壁垒,只能寻求细分场景的差异化突围。(二)本地化部署算力服务商
本地化部署算力服务商主要为政企客户提供物理部署的算力设备和服务。根据技术路线和生态归属的不同,可以进一步细分为通用算力平台提供商和华为生态算力服务商两大阵营。1.通用算力平台提供商
(1)浪潮信息:规模驱动的行业龙头
浪潮信息是全球领先的算力基础设施提供商,也是中国AI服务器市场的绝对龙头。据Gartner和IDC数据,2025年第一季度,浪潮信息服务器全球排名第二、中国排名第一;存储装机容量全球前三、中国第一;液冷服务器和边缘服务器均为中国第一。2025年,浪潮信息实现营业收入1647.82亿元,同比增长43.25%,连续两年保持40%以上的高速增长。其中,上半年服务器销售额同比增长99.50%,达到752.86亿元,占总收入的93.88%。公司归母净利润24.13亿元,同比增长仅5.20%——营收增速与利润增速之间的巨大“剪刀差”,折射出服务器集成商在产业链中的尴尬地位。浪潮信息的核心优势在于规模效应和供应链整合能力。1647亿元的营收规模使其拥有行业最强的供应链议价能力和大规模集群交付能力。其AI服务器国内市占率超过50%,连续多年稳居第一,是字节跳动、阿里巴巴、腾讯等互联网大厂以及三大运营商算力采购的核心供应商。然而,高市占率并未转化为高利润率——2025年浪潮信息毛利率约为4.88%,净利率仅为1.46%,远低于同行业水平。盈利承压的核心原因在于:产品结构向大规模集群系统集成倾斜,互联网客户订单占比高、议价能力强,上游GPU、HBM等核心元器件价格居高不下,行业竞争日趋激烈。在产品和技术层面,浪潮信息已形成“服务器+存储+网络”的全栈布局。其液冷服务器全球市占率超过35%,连续多年蝉联国内第一,全栈液冷产品可实现单机柜功率密度突破100kW。在推理服务器赛道,浪潮信息推出了超节点AI服务器“元脑SD200”,单机可运行超万亿参数大模型。在国产替代方面,浪潮信息实现了“国际+国产”双供应链布局,与英伟达、英特尔保持长期合作,同时深度绑定海光、寒武纪、华为昇腾等国产芯片厂商,并在工行国产芯片服务器采购项目中独家中标。集邦咨询预估2026年全球AI芯片液冷渗透率将进一步提升至47%,浪潮信息的液冷服务器毛利率超过40%,有望成为未来盈利修复的关键。(2)中科曙光:算力基础设施的全栈玩家
中科曙光是中国算力基础设施领域的重要玩家,聚焦“硬件+平台+服务+运营”的算力服务模式。2025年,公司实现营业收入149.64亿元,同比增长13.81%;归母净利润21.76亿元,同比增长13.87%。其中IT设备收入125.03亿元,占比约83.6%。中科曙光最值得关注的是其高附加值服务业务的快速增长。2025年,公司软件开发、系统集成及技术服务收入实现24.46亿元,同比增长75.34%,占营业总收入比重从2024年的约10.6%提升至约16.3%。该业务板块的毛利率显著高于公司整体水平,成为拉动整体毛利率提升的核心变量。在产品创新方面,中科曙光成功推出单机柜级超节点产品ScaleX640,并以此为基础构建了ScaleX万卡超集群系统,通过高速专用网络连接多个超节点组成大规模“算力集群”,实现上万块计算核心的同时工作。公司的ScaleX万卡超集群已在国家超算互联网核心节点实现同步建设、同步上线、同步对外提供服务,标志着公司已形成从单机系统、集群互联到数据中心级基础设施的全栈能力体系。同时,依托曙光AI超集群国产算力,公司发布了国内首个科学大模型一站式开发平台OneScience。研发方面,2025年公司研发费用达16.71亿元,同比增长29.33%。2.华为生态算力服务商
(1)华鲲振宇:昇腾服务器的出货冠军
华鲲振宇是华为“鲲鹏+昇腾”双战略级伙伴,也是昇腾服务器出货量国内第一的厂商,市占率约50%。这家诞生在成都的企业交出了一份令人瞩目的成绩单:第一年营收6200万元,2021年增长超十倍,2024年突破百亿。2025年,华鲲振宇营收预计突破100亿元。华鲲振宇的核心优势在于深度绑定华为生态。公司是四川长虹的控股子公司(持股70%),在金融、运营商领域的昇腾服务器订单持续爆发。2025年,公司中标80亿智算中心大单,与字节跳动、运营商深度绑定,已出货3.2万台昇腾服务器。公司年产能达50万台,是字节跳动2026年12至13万张昇腾950芯片采购计划的核心供应商。(2)拓维信息:软硬双轮驱动的华为生态伙伴
拓维信息是华为全方位的合作伙伴——覆盖“鲲鹏/昇腾AI/海思+云/大模型+开源鸿蒙”的全栈生态。公司旗下“兆瀚”系列AI服务器基于华为昇腾AI芯片,涵盖训练、推理、边缘计算等全场景。从业务结构来看,拓维信息形成了“软件服务+智能计算”的双轮驱动模式。2025年上半年,公司软件云服务收入9.50亿元,毛利率13.18%;国产自主品牌(兆瀚)服务器及PC收入2.84亿元,毛利率16.94%。国产智能计算业务营收占比约65%,毛利率约12%-15%。2025年第三季度,公司营收7.72亿元,净利润2604.32万元,同比增长239.19%。在算力服务运营方面,拓维信息不仅销售硬件,还运营“兆瀚”AI算力中心,提供公有云和私有云算力租赁服务,2025年一季度该业务毛利率高达65%。2025年,公司昇腾服务器配套软件收入达4.2亿元,占比达68%,中标移动5.5亿元昇腾相关集采,产品覆盖全国30多个智算中心。3.公有云与本地化部署的竞争态势
公有云算力服务与本地化部署算力服务并非简单的替代关系,而是面向不同客户需求的分层供给。从市场规模来看,公有云算力服务(AI云市场)2025年规模约567亿元,而算力租赁市场(含公有云和私有云)规模约2116亿元——后者涵盖了更广泛的算力服务形态。从客户选择逻辑来看,大型互联网企业和科技公司倾向于使用公有云算力服务,因为其具有弹性伸缩、按需付费、无需操心运维的优势;而政府、金融、医疗等对数据安全有严格要求的行业,则更倾向于本地化部署方案。头部云厂商凭借规模效应和全栈能力占据公有云市场主导地位,而本地化部署市场则相对分散,各厂商通过差异化竞争寻找生存空间。从发展趋势来看,两种模式的边界正在模糊。公有云服务商开始推出“专属云”“本地云”等混合部署方案,满足政企客户数据不出域的需求;而本地化部署服务商也在探索“算力租赁”“算力服务”等运营模式,从卖设备向卖服务转型。三、国产算力服务的三个规模层次
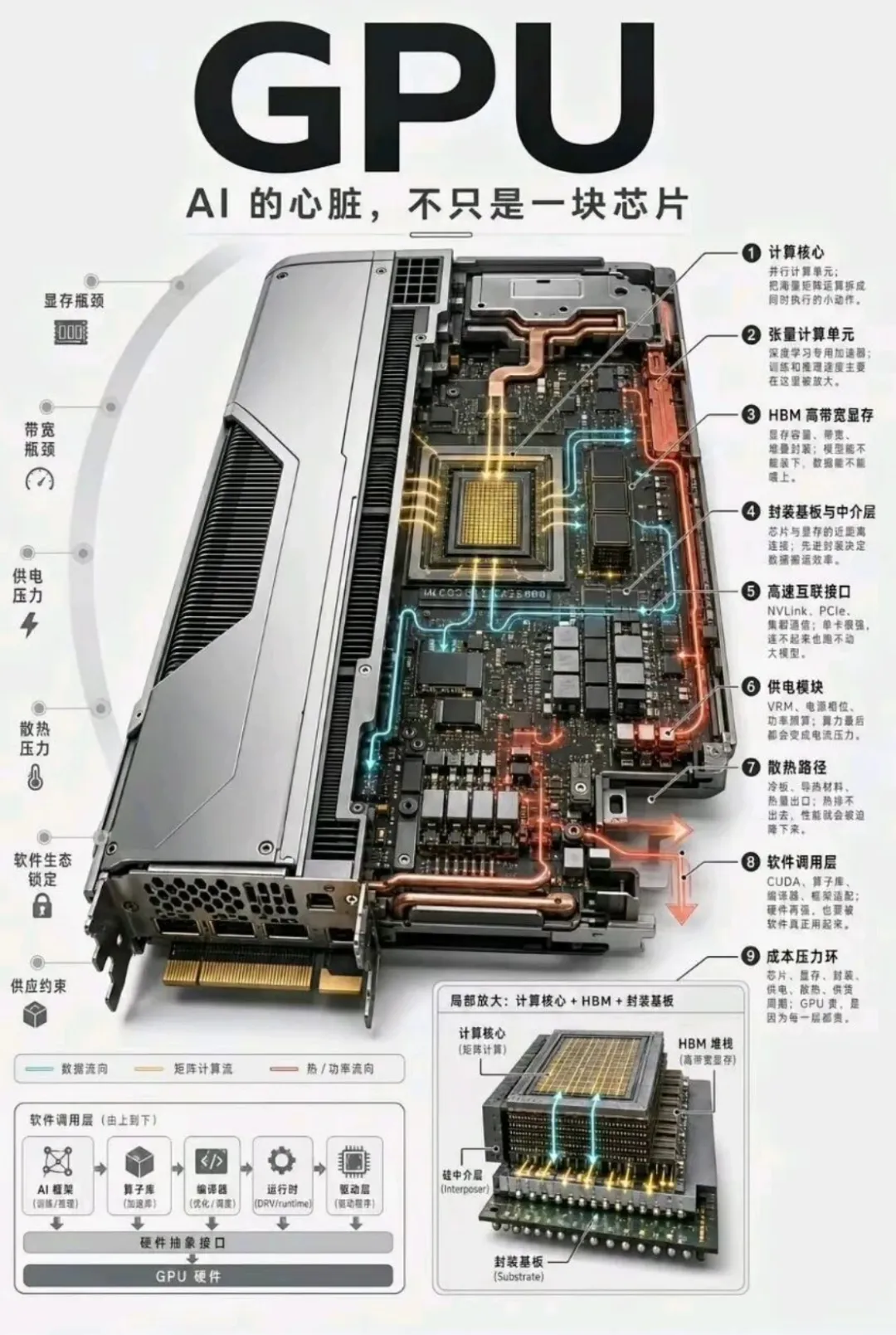
算力一体机、超节点和集群算力构成了国产算力服务从“单机”到“机柜”再到“数据中心”的三个技术层次。(一)算力一体机
算力一体机是算力服务私有化部署的最小单元,也是当前国产算力服务增长最快的产品形态之一。它将计算硬件、AI平台、预训练模型和行业应用打包成一个标准化产品,让客户“开箱即用”。1.硬件层的技术原理与难点
(1)异构计算架构
算力一体机的硬件层采用“通用CPU+专用AI加速卡”的异构计算架构。通用CPU负责操作系统运行、任务调度和逻辑控制;AI加速卡(GPU/NPU)承担矩阵乘法、卷积等密集型计算任务。以典型的4U机架式一体机为例,其集成16块国产GPU卡,通过PCIe 4.0总线实现低延迟互联。计算架构包含三个核心部分:通用计算单元负责模型参数加载与梯度计算;张量核心针对矩阵乘法进行硬件加速,性能较CPU提升20倍;动态内存池通过内存复用技术将大模型显存占用从1.2TB压缩至800GB。(2)硬件兼容性困境
这是国产算力一体机面临的最核心硬件难题。国产CPU与AI加速卡的架构差异导致多重问题:指令集不兼容:某国产加速卡采用自研指令集,与主流深度学习框架存在适配层缺失。这意味着PyTorch等框架无法直接在国产芯片上运行,需要额外的“翻译层”将框架指令转换为芯片能识别的指令,这种转换会带来显著的性能损耗。内存墙问题:国产处理器的内存带宽限制影响大模型推理效率。训练芯片需要极高带宽的HBM来供应数据,而国产芯片在HBM的容量和带宽上与英伟达仍有差距,导致计算单元在等待数据时处于空转状态。拓扑复杂性:多卡互联时PCIe通道分配需要特殊优化。一体机内多张加速卡通过PCIe Switch实现互联,但不同国产芯片的PCIe通道配置和拓扑结构各不相同,需要针对每款芯片进行单独的通道分配优化。(3)散热与功耗挑战
一体机在有限的空间内集成多张高功耗加速卡,散热成为严峻的工程挑战。高功耗部件需要采用全液冷散热方案,风液比可达80%,才能有效突破高功耗芯片的散热瓶颈。液冷方案的引入不仅增加了硬件成本,还对机箱设计、管路布局和运维流程提出了更高要求。2.软件层的技术原理与难点
(1)软件生态碎片化
国产化环境的软件生态碎片化是比硬件更难以解决的问题:框架版本滞后:开源社区的最新特性与国产编译环境存在3至6个月的延迟。当PyTorch发布新版本时,国产芯片需要额外的时间来完成适配和验证。依赖库缺失:cuDNN等专用加速库在国产平台上没有直接替代方案。cuDNN是英伟达深度优化的深度学习算子库,经过十多年的迭代已极其成熟。国产芯片如果要达到相近的性能,需要从零开始开发功能对等的算子库——这是一项极其耗时的工作。性能调优困难:缺乏针对国产硬件的优化工具链。开发者无法像在CUDA生态中那样使用NVIDIA Nsight等专业性能分析工具来定位和优化瓶颈。(2)异构任务调度
一体机的软件层需要解决CPU与加速卡之间的任务调度问题。工作流程大致为:CPU将张量数据分片,通过DMA传输至加速卡显存;加速卡执行矩阵乘法与激活函数计算,输出概率分布;CPU合并结果并执行后处理。这种CPU与加速卡的频繁数据交换对调度算法提出了极高要求——调度不当会导致CPU和加速卡交替等待,造成资源浪费。(3)模型轻量化技术
为了解决国产芯片在算力和显存上的短板,一体机软件层普遍采用模型轻量化技术。量化感知训练通过模拟INT8量化过程调整权重,在精度损失小于1%的前提下将模型体积压缩至FP32的四分之一。分层存储策略将模型参数划分为热数据(当前层权重)与冷数据(其他层权重),分别存储于GPU显存与主机内存。流水线并行将模型按层切分为多个阶段,每个阶段由多块GPU并行处理。(二)超节点
超节点是算力一体机向更大规模扩展的中间形态。它将数十乃至上百张GPU通过高速互联整合为一个“超级计算机”,是对传统“服务器堆叠”架构的系统级重构。1.超节点的技术原理
理解超节点的价值,首先要理解传统集群架构的根本缺陷。在传统集群中,每一块GPU都是一座“孤岛”,拥有自己独立的HBM显存,需要访问其他GPU的数据时必须走一套繁琐的流程:数据从发送端HBM拷贝到系统内存,封装成网络报文,经过交换机路由,接收端解析报文,最后写入目标内存。这个过程存在几毫秒的延迟——在处理网页请求时尚可接受,但在大模型训练中,模型被切分成成千上万块,每一层神经网络的计算都需要在芯片间进行极高频次的同步。通信墙:在大模型训练场景中,通信频次随模型层数和并行度呈指数级增长,微秒级的协议栈延迟在万亿次迭代中累积,导致计算单元长期处于等待状态。功耗与散热墙:为了减少延迟,工程师不得不在一个机柜里塞更多计算单元,代价是恐怖的散热压力和供电挑战。复杂度墙:集群规模从千卡推向万卡乃至十万卡,运维复杂度同步提升,大模型训练过程中每隔几个小时就要处理一次故障。超节点的核心思路是:通过高速互联将多张GPU“焊接”成一个逻辑上的整体,消除“序列化-网络传输-反序列化”的开销。超节点的三个硬性指标是——大带宽、低时延、内存统一编址。其中“内存统一编址”是最核心也最难实现的:目标是构建一个全局唯一的虚拟地址空间,集群内所有芯片的内存资源被映射成一张巨大的地图,计算单元可以直接“伸手”拿数据,而不需要“打电话”。2.硬件层的技术原理与壁垒
(1)Scale-Up互联:超节点的核心
超节点的本质是通过Scale-Up网络将大量GPU卡连成一个可以内存共享的超级计算机。Scale-Up和Scale-Out不是替代关系——做了超节点同样需要Scale-Out网络来扩展到更大集群。Scale-Up网络目前多为私有协议,满足更多数量卡间的张量并行、专家并行、序列并行通信带宽及延时要求。英伟达的NVLink 6.0实现了双向3.6TB/s的极速互联,领先传统PCIe 6.0十数倍。跨节点网络降维至机柜内总线直连,单跳时延实现微秒至纳秒级的跨越。(2)国产超节点的硬件壁垒
国产超节点面临的核心硬件壁垒在于互联技术。华泰证券研报指出,超节点最核心的增量在于支撑超大规模节点内部高效互联的Scale-Up环节,具体包括交换芯片、交换机和铜连接。2028年国内Scale-Up交换芯片市场规模预计达172亿元。对于绝大多数国产芯片厂商而言,超节点赛道已明显超出其能力边界。这类企业普遍缺乏chip-to-chip互联技术的积累,而算力体系向Scale-Up深度演进的过程中,对网络能力与系统架构的要求持续抬升。互联协议的不统一是另一个重大障碍——不同厂商的芯片使用不同的互联协议,难以在同一个超节点内协同工作。在散热方面,超节点机柜功耗大幅提升,液冷从“可选”变为“刚需”。以新华三UniPoD S80000超节点为例,单机柜最高支持128卡,PUE可控制在1.04以下。联想问天超节点单节点可搭载40张GPU,访存总带宽超过80TB/s,芯片间P2P通信时延达到百纳秒级。(3)国产超节点的探索与实践
2026年被业界视为国产超节点元年。国内已有多家企业发布了超节点方案:中兴通讯OEX超节点:采用首创的“正交电交换”架构,单机柜可支持128个GPU,通过自研机内互联交换芯片兼容主流高速互联协议,实现百纳秒级低时延。新华三UniPoD S80000:单机柜最高支持128卡,覆盖32卡至1024卡全系列,可灵活扩展至16384卡规模。联想问天超节点:单节点可搭载40张GPU,FP8算力超过28 PFLOPS。光跃超节点:基于曦智科技硅光OCS光交换芯片,连接128个壁仞GPU液冷模组,实现跨机柜GPU万卡级弹性扩展。3.软件层的技术原理与壁垒
(1)内存统一编址的实现难度
超节点最核心的软件技术是“内存统一编址”——将集群内所有芯片的内存资源映射为一个全局唯一的虚拟地址空间。实现这一目标需要操作系统、驱动、编译器、运行时等多层软件的深度改造:操作系统层:需要支持跨节点的内存管理,将物理上分散的显存抽象为统一的地址空间。驱动层:需要实现跨卡的数据直接访问(GPU Direct RDMA),让一张GPU可以直接读写另一张GPU的显存,而不经过CPU的中转。编译器层:需要将并行计算任务自动映射到统一地址空间中的不同计算单元,实现负载的自动均衡。运行时层:需要处理跨节点内存访问的一致性和同步问题,确保多个计算单元同时访问同一内存地址时数据不出错。(2)国产超节点的软件壁垒
国产超节点在软件层面面临比硬件更严峻的挑战。倘若无法实现“内存统一编址”,所谓的“超节点”本质上仍是传统服务器的堆叠架构。国内多家企业推出的“超节点”中,部分只是把几十台服务器塞进一个机柜、用光纤连接在一起就贴上“超节点”标签——这种“李鬼冒充李逵”的做法掩盖了内存统一编址这一核心技术的缺失。各厂商软件栈的不兼容是另一个重大障碍。倘若各家的软件栈无法兼容,开发者就需要为不同平台重复开发,这不仅增加了开发成本,也阻碍了AI应用的跨平台部署和生态共享。(三)集群算力
集群算力是超节点通过Scale-Out网络扩展后的最终形态,也是大模型预训练对算力的核心需求形态。1.大规模集群的技术挑战
(1)大规模集群服务能力有待提升
国产算力目前主要应用于推理和微调场景,在千卡、万卡级别的预训练集群方面仍需突破多重瓶颈。具体而言:单卡性能:国产AI芯片在峰值算力上仍与国际领先水平存在差距,导致达到同等总算力需要更多卡数,进而推高集群规模和互联复杂度。互联带宽:国产芯片间的互联带宽和延迟与国际先进水平仍有差距,在万卡集群中这一差距会被放大——通信效率的微小不足在数万张卡的规模下会累积为显著的训练效率损失。软件生态:主流框架、算子库深度绑定CUDA生态,模型向国产算力迁移流程复杂、开发成本高、周期长。大规模运维:万卡集群的故障率极高——在大模型训练过程中,每隔几个小时就要处理一次故障。国产算力在集群稳定性、故障自动恢复等方面仍需积累经验。(2)训练效率与成本倒挂
由于调度效率与互联效率仍存在短板,国产算力在大规模训练中的综合成本并未同步下降。从集群维度看,实际使用成本反而可能高出20%至30%,出现成本倒挂。这意味着即便国产芯片的单卡采购成本更低,但在大规模集群中,由于效率损失和运维成本增加,总体拥有成本反而更高。(3)系统工程的复杂度
实现十万卡级别的国产算力集群面临“三重门”:大规模可靠性、与应用的深度协同、以及极高的软件系统调优门槛。这三个挑战都不是单纯增加硬件投入可以解决的——它们需要系统级的工程能力和长期的实战积累。万卡集群中数据IO瓶颈导致GPU空等时间占比可达40%以上——这意味着昂贵的算力芯片有近一半时间在等待数据搬运。网络层面的拥塞和丢包则让跨节点通信效率大打折扣。2.国产算力集群的实践进展
尽管挑战重重,国产算力集群仍在快速推进。深圳河套学院AI训练平台项目团队联合哈尔滨工业大学、深圳市大数据研究院、华为及深智城AI算力平台,基于昇腾910C国产AI算力集群,成功完成了1.6万亿参数DeepSeek-V4-Pro大模型的全参数后训练。这是业界首个由第三方机构基于国产算力集群完成的大规模训练工程实践,标志着国产AI基础设施从推理部署迈向全参数后训练的新阶段。稻盛云(武威)智算中心项目设计可承载总浮点算力达14400P,是延河西走廊段首个国产AI算力芯片万卡集群。“黄埔一号”智算集群1期项目已于2025年10月完成项目终验并正式投入商业化运营。太初元碁已在全国多地落地智算中心项目,郑州、盐城、延安等多个算力节点建成投运,总算力规模达数千PFlops。公司千卡集群能力已追平国际水平,万卡、十万卡集群技术正加速突破。3.异构算力调度的软件技术
在国产算力集群中,异构算力调度是软件层面最核心的技术难题。多芯片共存已成为中国AI生态的结构性现实。企业面临资源池割裂、模型重复适配、调度效率不足、服务性能波动和运维成本上升等多重挑战。(1)异构算力统一纳管
异构算力调度平台的核心价值在于通过标准化、调度、优化和稳定化四个环节,帮助企业把不同厂商、不同架构、不同位置的GPU资源抽象为统一、可分配、可编排的算力单元。以“密瓜智能”的HAMi开源项目为例,其实现了对NVIDIA、华为昇腾、沐曦、摩尔线程、寒武纪、海光、燧原等9种以上芯片的适配。技术能力包括细粒度切分与显存超卖(支持将单枚GPU的显存与算力进行精度达十分之一甚至更小的切分)、跨厂商异构统一适配与动态MIG、自动弹性扩缩容与优先级机制等。中国移动“芯合”异构混训系统实现了6家芯片混合训练,处于业界领先水平。平台已适配瀚博、天数等9家国产芯片,模型推理吞吐及并发性能提升96.5%。(2)算力的系统级编排
沙利文在《2026年AI基础设施管理平台白皮书》中指出,AI基础设施正从“单芯片性能竞争”迈向“系统级协同编排”的新阶段。随着推理负载具备持续在线、高并发、强实时和跨节点分布等特征,GPU集群不再只是硬件资源堆叠,而是需要围绕资源利用率、延迟稳定性、模型执行一致性与SLA保障进行统一调度和运营。AI基础设施正在从“硬件管理”迈向“算力经济学”与“业务结果交付”。这意味着算力服务的竞争不再是“谁有更多芯片”,而是“谁能以更低的成本、更高的效率、更稳定的质量交付算力服务”。四、算力一体机解析
算力一体机是算力服务本地化部署的核心产品形态,也是当前算力服务市场增长最快的细分领域之一。它将计算硬件、AI平台、预训练模型和行业应用打包成一个“开箱即用”的标准化产品,大幅降低了企业部署AI能力的门槛。(一)一体机的定义与市场定位
算力一体机是算力服务私有化部署的最小单元,也是当前国产算力服务增长最快的产品形态之一。它将GPU/AI加速卡、CPU、存储、网络等硬件设备,与操作系统、AI框架、推理引擎、管理平台等软件系统,以及预训练的大模型进行深度整合,形成一个标准化产品,让客户“开箱即用”。一体机的核心价值定位是“企业AI入门的即插即用方案”和“大模型应用落地的最后一公里”。对于缺乏AI技术团队的传统企业而言,自行采购GPU服务器、安装配置软件栈、适配优化模型,不仅周期长、成本高,而且技术门槛极高。一体机将这一复杂的工程过程封装在设备内部,客户通电、联网即可开始使用大模型能力。从市场空间来看,浙商证券预测,2025年至2027年一体机需求量将分别达到15万台、39万台和72万台,对应市场空间分别为1236亿元、2937亿元和5208亿元。这一增长趋势反映了AI技术对算力需求的强劲推动,以及市场对一体化解决方案的高度认可。(二)一体机的构成与工作原理
一台标准的算力一体机由硬件层、软件层和服务层三个层次构成,三者协同工作,形成一个完整的AI算力交付单元。1.硬件层
一体机的硬件层是其计算能力的物理承载。核心组件包括:计算单元是一体机的心脏,通常由多颗GPU或AI加速卡组成。目前市场上主流的方案包括英伟达(H100、A100、4090等)、华为昇腾(910B、910C等)、寒武纪(思元系列)、海光(深算系列)、沐曦等。不同厂商的一体机在芯片选择上各有侧重——华为生态的一体机通常采用昇腾芯片,通用型一体机则可能兼容多种芯片。CPU是一体机的“大脑”,负责运行操作系统、调度任务和控制外设。主流方案包括x86架构(Intel、AMD)和ARM架构(华为鲲鹏)。CPU的选择直接影响一体机的软件生态兼容性——x86架构兼容性更广,ARM架构在国产化要求下更具优势。内存与存储包括高带宽内存(HBM或DDR)和大容量SSD存储。HBM的容量和带宽直接影响大模型的部署能力——显存越大,可承载的模型参数越多。网络与互联包括交换机、高速互联总线等,用于实现多卡之间的高速数据交换和对外网络连接。散热系统是保障一体机稳定运行的关键。随着GPU功耗持续攀升(单卡功耗已突破1000W),风冷已难以满足需求,液冷正在成为标配方案。液冷方案的PUE(电源使用效率)可低至1.1,而风冷通常在1.5以上。2.软件层
软件层是一体机算力的智能调度,决定了硬件性能能否被充分释放。主要包括:操作系统通常采用Linux发行版(如Ubuntu、麒麟等),提供基础的运行环境。AI框架包括PyTorch、TensorFlow等主流深度学习框架,是开发和运行AI模型的基础工具。推理引擎如vLLM、Triton等加速框架,负责将训练好的模型高效地部署到硬件上运行。推理引擎的优化水平直接影响模型的推理速度和并发能力。管理平台提供集群管理、算力调度、运维监控等功能,是用户与一体机交互的主要界面。一个好的管理平台可以大幅降低运维难度——预装管理软件可降低30%以上的运维人力投入。预置模型是一体机的重要卖点。厂商通常会在出厂时预装DeepSeek、千问等主流大模型,客户开机即可使用,无需自行下载和配置。3.服务层
服务层包括部署实施、技术培训和售后运维等服务。质保期通常为1至3年,部分厂商还提供年度运维服务(通常为设备价格的15%至20%)。(三)一体机的成本结构
一体机的成本结构可以从初始采购成本和运营成本两个维度来理解。1.初始采购成本
硬件设备是最主要的成本项,其中GPU/AI加速卡占比最高。以一台配置8卡GPU的一体机为例,GPU的成本可能占到总硬件成本的60%至80%。CPU、内存、存储、网络设备等构成剩余部分。软件授权包括操作系统、AI框架、管理软件等的授权费用。对于采用开源软件方案的厂商,这部分成本相对较低;对于采用商业软件方案的厂商,软件授权可能是一笔不小的开支。集成服务费用包括硬件组装、软件安装调试、模型优化适配等服务的费用。从市场价格来看,一体机的报价差异较大。据创业黑马披露,其与华为云合作销售的一体机报价在300万至500万元一台。中国电信在2025年的全光组网接入算力一体机集采中,主设备(FTTR-B+通用服务器)不含税单价最高限价为9900元/台,AI算力卡不含税单价最高限价为55元/TOPS——这一定价模式反映了运营商集采对成本的极致压缩。2.运营成本(TCO)
运营成本是企业在设备全生命周期内需要持续投入的费用,主要包括:电力成本是一体机运营的最大变动成本。液冷机型的PUE可低至1.1,而风冷通常在1.5以上。以1000TOPS算力需求为例,华为方案5年TCO比戴尔低23%。散热成本与电力成本密切相关,液冷方案虽然初始投资较高,但长期运营成本更低。运维人力成本是另一项重要支出。预装管理软件可以降低运维难度和人力需求。硬件折旧按5年周期计算,是TCO核算中的固定成本项。(四)一体机的定价模式
一体机的定价模式正在从单一的一次性买断向多元化方向发展。一次性买断模式是最传统的定价方式。客户一次性支付设备全款,获得硬件所有权和永久软件使用权。典型价格区间在180万至500万元/台,含3年硬件质保。这种模式适合资金充裕、希望一次性完成资产购置的大型企业。订阅/租赁模式正在成为新的趋势。客户按年或按月支付费用,获得算力设备的使用权,无需承担一次性大额采购成本。这种模式降低了中小企业的进入门槛,企业可以根据业务波动动态调整算力规模。运维服务费是持续性的收入来源,通常为设备价格的15%至20%/年,覆盖硬件维保、软件更新、技术支持等服务。中国电信的智算一体机采用“3年服务期价格=一体机规格标准资费×数量+机柜标准资费+一体机规格维保标资费×数量”的计费模式,后续扩容时仅对新增服务器节点独立收费。(五)一体机的销售模式
一体机的销售渠道正在从单一的直销向多元化渠道拓展。直销模式主要面向大型企业、政府客户,通过厂商自己的销售团队进行直接销售。这种模式适合定制化程度高、配置复杂的大型项目,厂商可以直接了解客户需求并提供针对性的解决方案。渠道分销模式通过与各地的系统集成商(SI)、独立软件开发商(ISV)合作,将产品销售给更广泛的客户群体。这种模式尤其适合向地市、区县级市场下沉。创业黑马即采用这种模式,与华为云合作向全国各个地市、区县推广一体机。生态合作模式是与云服务商、大模型厂商等生态伙伴合作,将一体机嵌入更广泛的解决方案中进行组合销售。例如,富通科技与百度文心联合推出“富通智核文心大模型一体机”,集算力、模型、平台与应用于一体。阡视科技推出的WYLON卧龙大模型一体机基于国产超级智算系统和操作系统,配备多种国产GPU算力,实现DeepSeek、千问、书生等大模型在国产CPU+GPU上开箱即用。(六)一体机的行业难点
技术难点主要体现在多厂商芯片的异构适配与优化、大模型推理的实时性与并发能力、以及软硬件的深度协同优化上。不同厂商的GPU在指令集、内存架构、软件栈上存在差异,要在同一台一体机上实现多种芯片的协同工作,需要投入大量的适配和优化工作。市场难点在于客户需求的多样性与产品标准化的矛盾。不同行业、不同规模的客户对算力、模型、安全性的需求差异很大,如何在标准化产品和定制化服务之间找到平衡,是所有一体机厂商面临的共同挑战。同时,市场参与者众多——IDC统计市场上已有近百家厂商推出AI一体机产品——竞争日趋激烈,价格战风险正在上升。据市场观察,一体机市场每季度价格波动约8%。交付难点在于从下单到交付的周期控制。早期一体机的部署周期通常需要一个多月,经过行业优化后已缩短至一到两周。但对于大规模集群项目,交付周期仍然较长。此外,售后服务的响应速度与覆盖能力也是一体机厂商需要持续提升的能力。五、算力服务行业现状与趋势
(一)行业现状
1.需求端:从概念验证走向生产部署
当前算力服务行业最显著的变化是需求端正在从“概念验证”走向“生产环境部署”。早期企业对AI算力的需求主要是为了验证技术可行性、做小规模实验;而现在,越来越多的企业开始将AI能力嵌入核心业务流程,对算力的需求从“有就行”升级为“稳定、高效、低成本”。据行业观察,大模型备案数量已超过300款,但能稳定运行的不足15%——这意味着大量企业仍处于从“能用”到“好用”的过渡阶段。2.供给端:百花齐放与同质化并存
近百家厂商推出AI一体机产品,市场供给极为丰富。但从产品层面看,同质化趋势正在显现——多数一体机在硬件配置、软件栈、预置模型上差异不大,真正的差异化更多体现在行业Know-How、服务能力和生态整合上。头部厂商正在向“标准化”模式演进,通过规模化生产降低成本、提升交付效率。3.竞争格局:分层竞争格局清晰
算力服务市场的竞争格局呈现明显的分层特征。公有云算力服务市场由阿里云、华为云、百度智能云等头部厂商主导,CR4超过75%。本地化部署市场相对分散,浪潮信息在通用服务器领域占据绝对优势,华鲲振宇、拓维信息等在华为生态中占据重要位置,中小厂商则在细分行业和区域市场寻找生存空间。头部企业正在通过资本整合与战略分化强化资源壁垒,服务商整体从“重资产投建”转向“平台化服务+生态协同”的重经营模式。(二)发展趋势
1.从卖硬件向卖服务转型
算力服务行业的商业模式正在发生深刻变化。传统上,算力服务商主要通过销售硬件设备(服务器、一体机)获取收入;而现在,越来越多的厂商开始提供算力租赁、算力运营、模型即服务(MaaS)等增值服务。这种转型的逻辑在于:硬件销售的毛利率持续走低(浪潮信息毛利率仅约4.88%),而服务的毛利率远高于硬件。拓维信息“兆瀚”AI算力中心运营业务的毛利率高达65%,充分说明了服务化转型的价值。2.训推一体机成为主流形态
早期的一体机产品要么侧重训练、要么侧重推理,功能相对单一。随着大模型从训练阶段走向应用阶段,同时支持训练和推理的“训推一体机”正在成为主流。这种产品形态使得企业可以用一台设备完成从模型开发、微调到部署上线的全流程,避免了训练设备和推理设备分别采购的重复投资。3.液冷方案加速普及
随着GPU功耗持续攀升,液冷正在从“可选”变为“必选”。集邦咨询预估2026年全球AI芯片液冷渗透率将进一步提升至47%。液冷方案虽然初始投资较高,但可以显著降低PUE和运营成本。浪潮信息的液冷服务器毛利率超过40%,远高于传统风冷服务器。液冷技术的普及将重塑算力基础设施的成本结构——运营成本占比下降,初始投资占比上升,对客户的财务模型将产生深远影响。4.下沉市场成为新增长点
一线城市和头部企业的算力基础设施建设已进入相对成熟阶段,而地市、区县级市场的需求正在快速释放。创业黑马与华为云合作的一体机正在向全国各个地市、区县推广。这一趋势背后的驱动力是政务、教育、医疗等公共服务领域的数字化转型需求——地方政府需要AI能力来提升治理效率和服务质量,但缺乏自建算力设施的技术和资金实力,一体机恰好提供了低成本、低门槛的解决方案。5.垂直行业定制化加速
通用型算力服务难以满足所有行业的需求。政务、金融、医疗、制造、能源等行业的AI应用场景差异巨大,对算力的需求也各不相同。越来越多的算力服务商开始推出行业定制化的一体机和解决方案——面向政务的“政务大模型一体机”、面向医疗的“医疗AI一体机”、面向制造的“工业质检一体机”等。这种垂直化趋势将推动算力服务从“卖盒子”向“卖解决方案”演进,也意味着那些具备行业Know-How的服务商将获得更大的差异化优势。