
AI科普馆部分垂类内容转移至?
【长三角人工智能联盟】公众号,快点进去瞧瞧!
AI数据治理研究院发布的《DCMM专项报告:数据认责体系建设白皮书》用39页篇幅拆解了一个事实:岗位表上的认责人和流程里的认责体系是两回事。前者是文档管理,后者是运营机制。白皮书的判断很直接——数据认责体系的完善程度,已经成为企业数据管理水平的试金石。
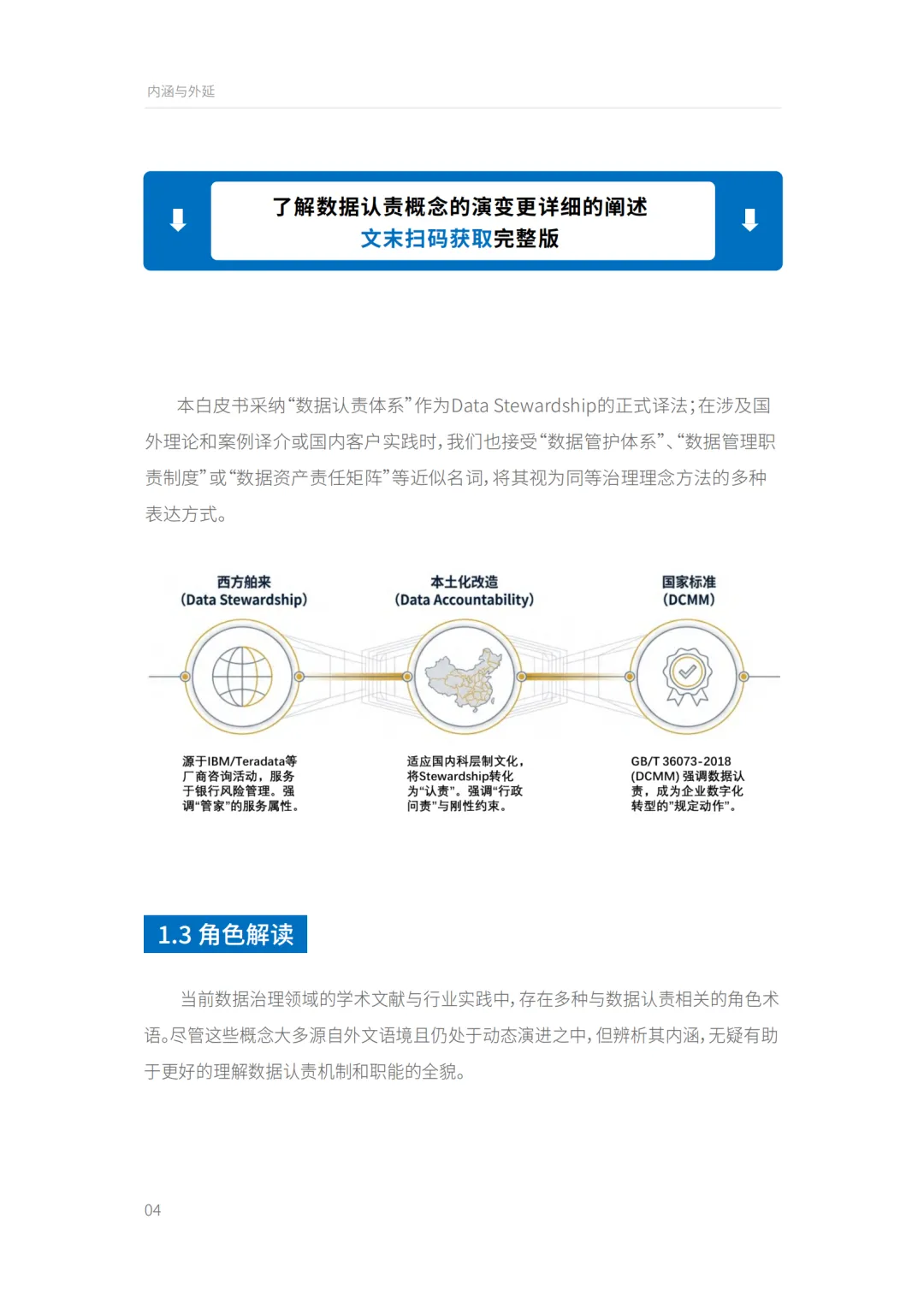
认责不是确权,Accountability也不是Responsibility
白皮书开篇做了一组概念辨析,值得先厘清。
数据认责(Data Stewardship)聚焦组织内部的管理授权与责任承担,回答"谁对这份数据的质量、安全、价值负责"。数据确权聚焦法律层面的所有权确认,回答"这份数据归谁所有"。两者不互替。
更关键的一组区分在RACI模型里:Accountability(当责)是"对结果负责",拥有最终裁决权,通常由业务部门负责人承担;Responsibility(职责)是"对过程负责",承担具体执行动作。混淆这两者,直接后果就是业务部门签字画押却不做决策,技术部门跑断腿却无权拍板——责任在纸面上闭环了,在业务里没有。
三类角色、四种行业,路径完全不同
白皮书梳理了四个核心角色:数据主人(Owner)对结果负最终责任;数据管家(Steward)负责将治理策略转化为日常业务规则;数据策管人(Curator)面向应用场景做数据融合共享;数据保管人(Custodian)负责技术运维。
不同行业落地时走出了截然不同的路径。金融行业以强监管驱动,设高管领衔的治理委员会+三级角色体系,认责矩阵直接嵌入系统开发和需求变更流程。电信行业以资产化为目标,利用大数据平台将认责流程集成进元数据管理,质量问题的工单能追溯到具体操作人。能源行业建了网-省-地-县四级协同体系,数万员工的认责工作靠平台自动化工单流转维持实时有效。制造业的核心难题是打破数据孤岛,将认责贯穿研发到售后的全价值链。
四个"不足"直接命中了落地死穴
白皮书将当前困境归纳为四类:设计与实践脱节、范围与粒度失衡、业务参与和感知不足、缺乏可持续性。
其中前两个是结构性问题。角色设计本地化不足,意味着通用的"数据主人"概念在不同组织架构中会产生真实的权责冲突。认责矩阵要么过粗导致责任真空,要么过细导致运维成本压倒管理收益。
后两个才是真正的深渊。业务部门把认责视为IT部门"摊派的行政任务",规则制定和质量稽核堆在技术端,认责变成了数据管理部门自说自话。运动式推进的后果是:一阵风过后,认责矩阵回到文件柜,一切归零。
四项原则、四步路径、三个常见误区
白皮书给的解法有明确的实操锚点。
四项核心原则:一是业务主导,IT部门无法定义数据的业务规则和质量标准,主责必须落在业务口;二是人人有责,从录入员到决策者,每个环节都承责;三是滚动推进,先挑经营分析、监管报送等影响大的"关键数据要素"做认责,再逐步扩展;四是权责利对等,不能只定责不授权。
四步实施路径:先划定关键数据要素范围(基于影响度、共享性、重要性三维判定),再借助RACI模型编制认责矩阵(明确每项数据的当责者、执行者、咨询者、知情者),然后在高痛点领域试点落地并固化为SOP,最后转入常态化运营监控,建立发现-分发-整改-预防的闭环。
白皮书特别点了三个最容易犯的错误:把数据岗位职责等同于数据认责(忽略了"横向治理权"需要有独立制衡机制);追求全量数据一次性确权(沟通成本极高、缺乏显性收益,必然半途而废);认为必须组建庞大专职队伍才能启动(正确做法是专职负责体系设计、兼职负责执行落地)。
AI时代:数据认责面临"黑箱压力"
白皮书在趋势章节指出了一个现实挑战:当数据消费对象从人变为AI智能体,数据需要从"人可读"进化为"机器可理解"。这意味着治理对象将从结构化数据扩大到非结构化数据,治理工具需要应对实时、异构、分布式的数据生态。
但AI本身也是解题工具。生成式AI可以自动化处理分类归识、异常检测、血缘补全等繁琐任务,通过自然语言接口缩短治理价值的实现周期。白皮书判断,未来的数据认责将从"静态的人治"转向"人机协同的智治"。
白皮书结语给出了一句判断:成功的数据认责最终不会显性地存在于制度文件中,而是内化为每位员工的日常行为自觉。这恰恰是当前大多数组织距离最远的状态——认责体系仍是一摞纸,不是一种工作方式。
本文基于AI数据治理研究院《DCMM专项报告:数据认责体系建设白皮书》撰写,详细内容请查阅原文。
以下是内容节选↓↓↓ 文末点击链接免费下载pdf,扫二维码加入交流群

















AI科普馆:打开AI世界之窗

