算力芯片行业报告:大模型驱动算力变革,国产算力迎增量机遇!
2026-07-02 17:21
算力芯片行业报告:大模型驱动算力变革,国产算力迎增量机遇!
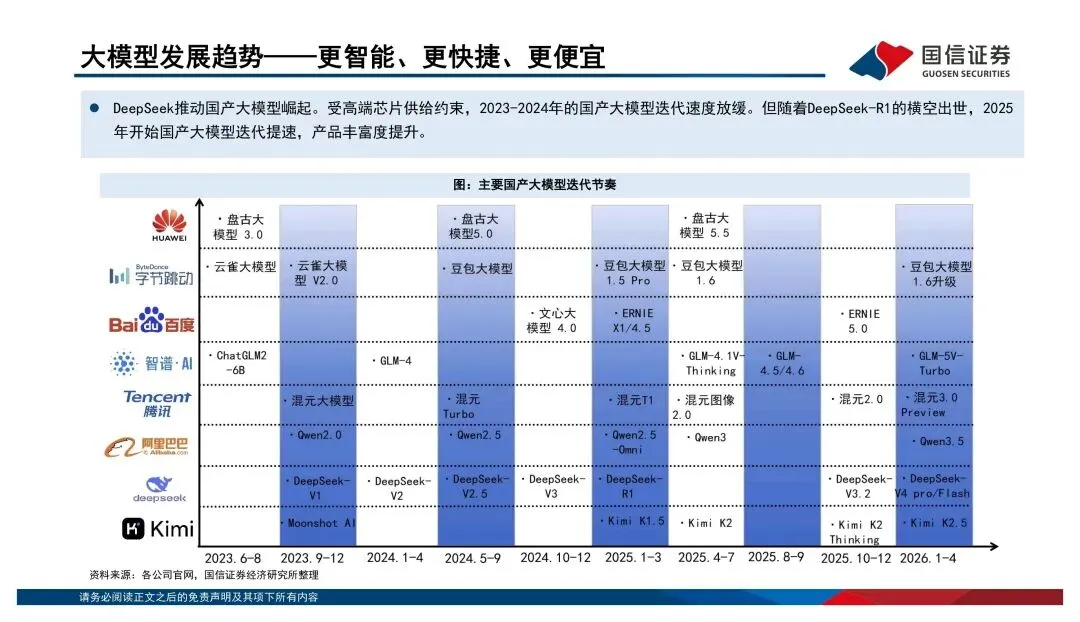
 大模型驱动算力变革,国产算力迎来了增量机会最近看了一份国信证券关于算力芯片的行业报告,把大模型和算力之间的关系梳理得挺清楚。核心逻辑其实就一句话:大模型还在狂奔,但算力的玩法变了,国产芯片的机会来了。下面说下我的理解。
大模型驱动算力变革,国产算力迎来了增量机会最近看了一份国信证券关于算力芯片的行业报告,把大模型和算力之间的关系梳理得挺清楚。核心逻辑其实就一句话:大模型还在狂奔,但算力的玩法变了,国产芯片的机会来了。下面说下我的理解。算力需求正从训练侧向推理侧外溢
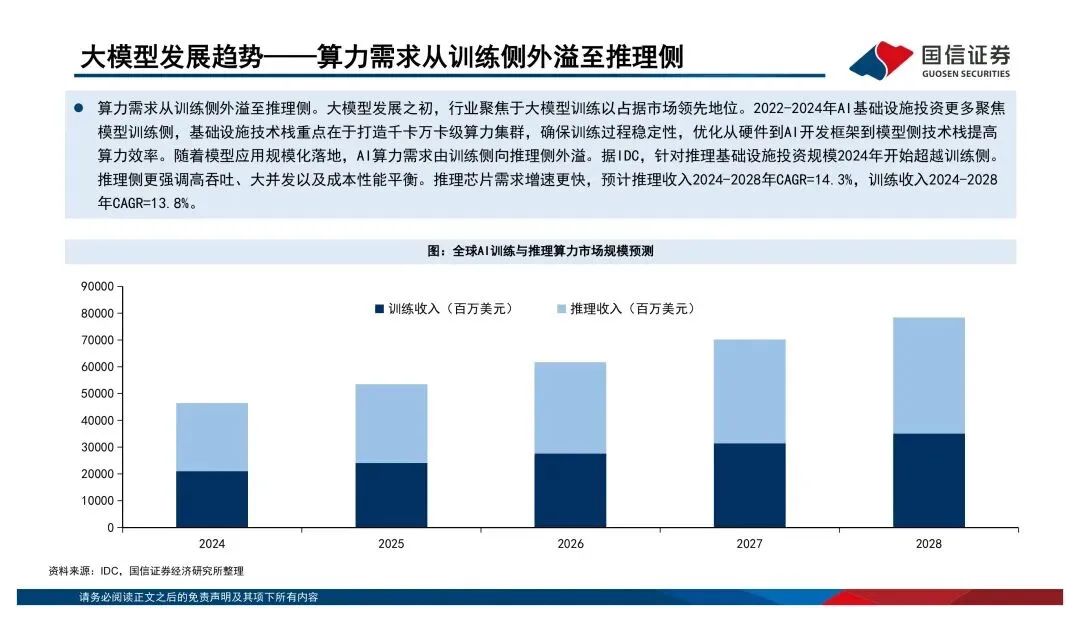
前两年行业都在抢着训练大模型,谁卡多谁牛,基础设施投资基本都砸在训练集群上。但到了现在这个阶段,模型开始规模化落地了,推理的需求起来了。报告里有个数据,2024年推理基础设施的投资规模已经超过了训练侧,而且预计到2028年推理收入的年复合增长率是14.3%,略高于训练的13.8%。这个趋势挺明确的——算力的主战场正在从"把模型训出来"转向"把模型持续服务出去",后者对延迟、并发和成本的要求完全不一样。芯片竞争的逻辑变了
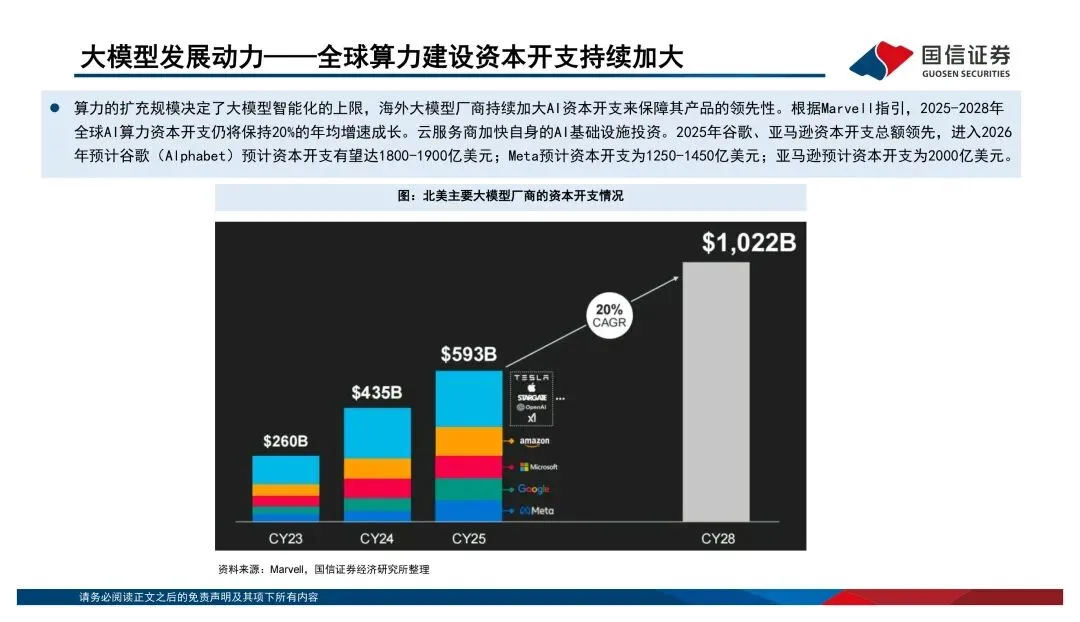
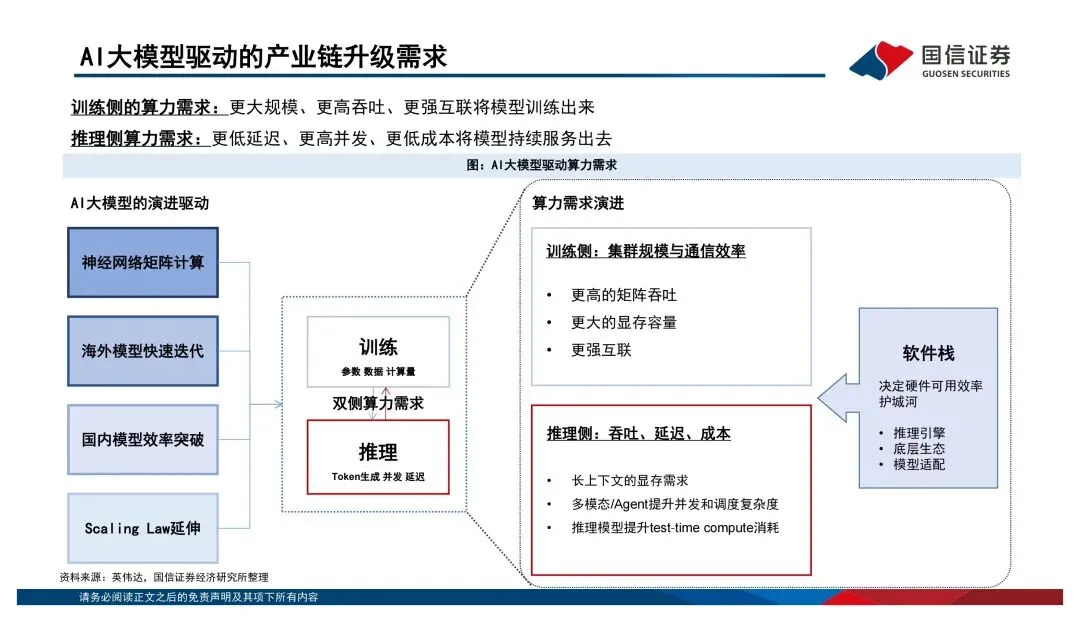
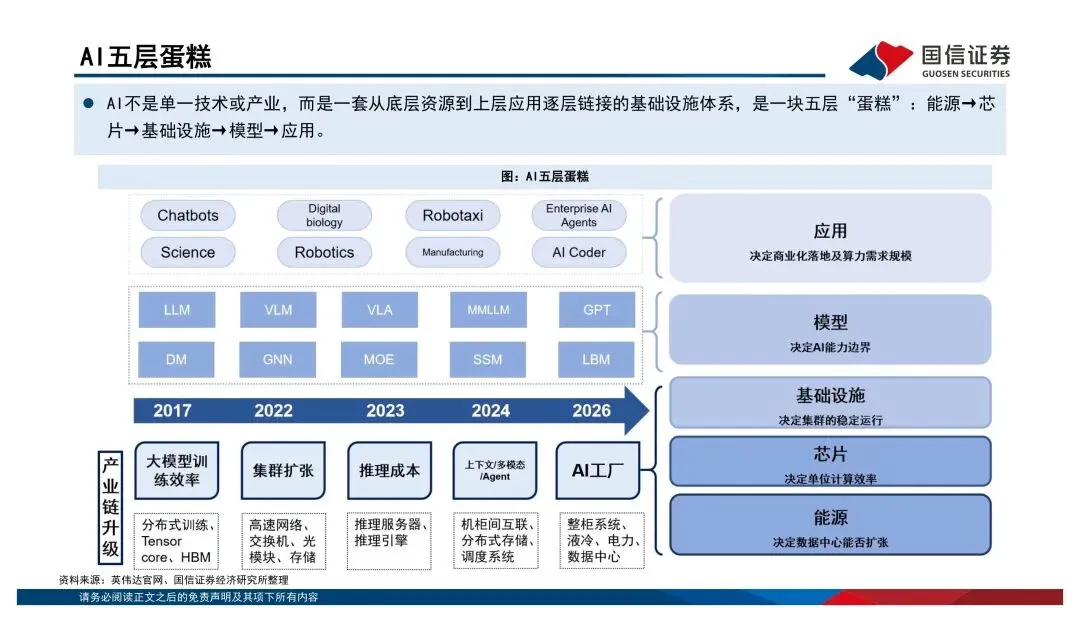
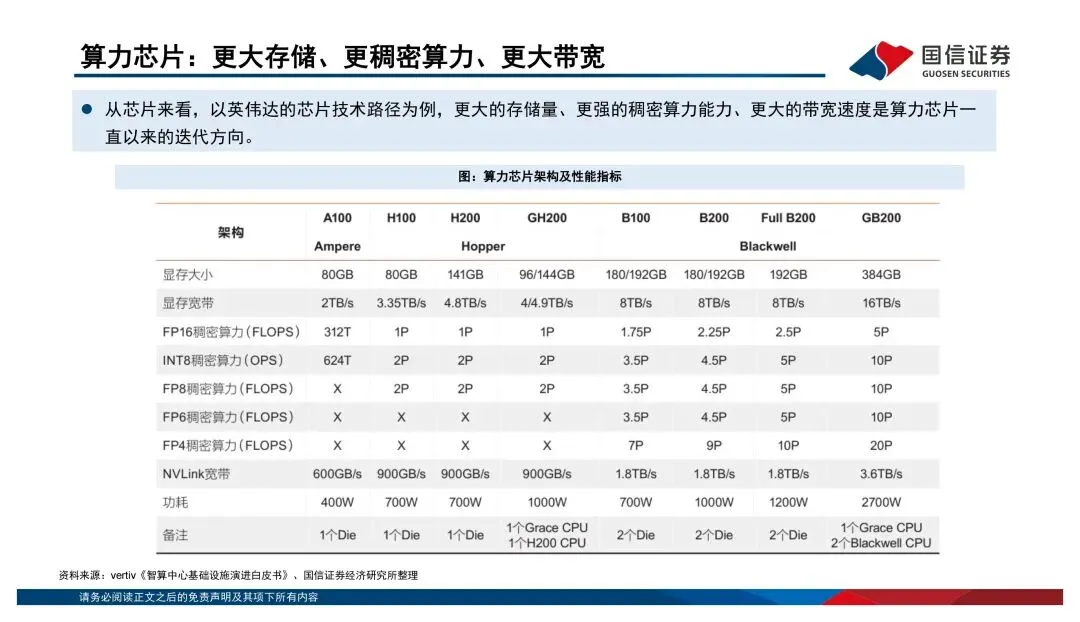
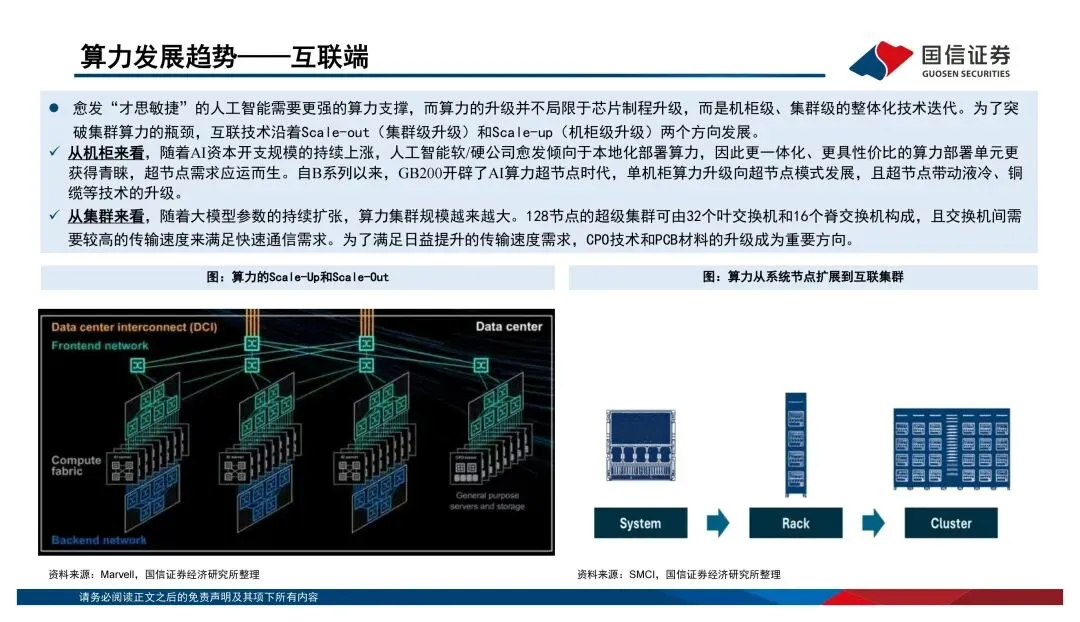
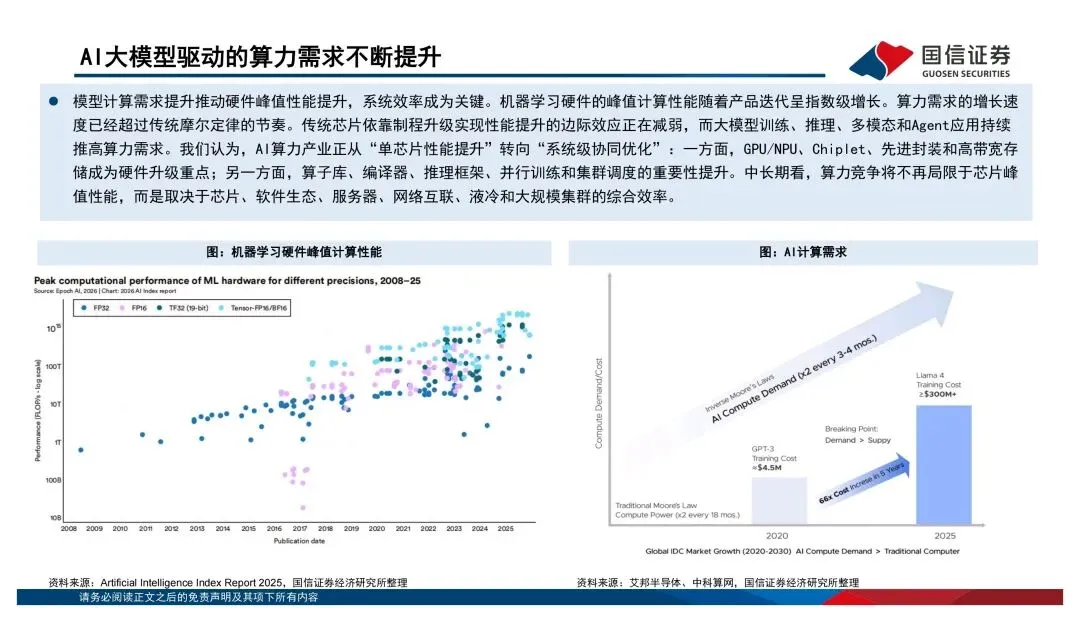
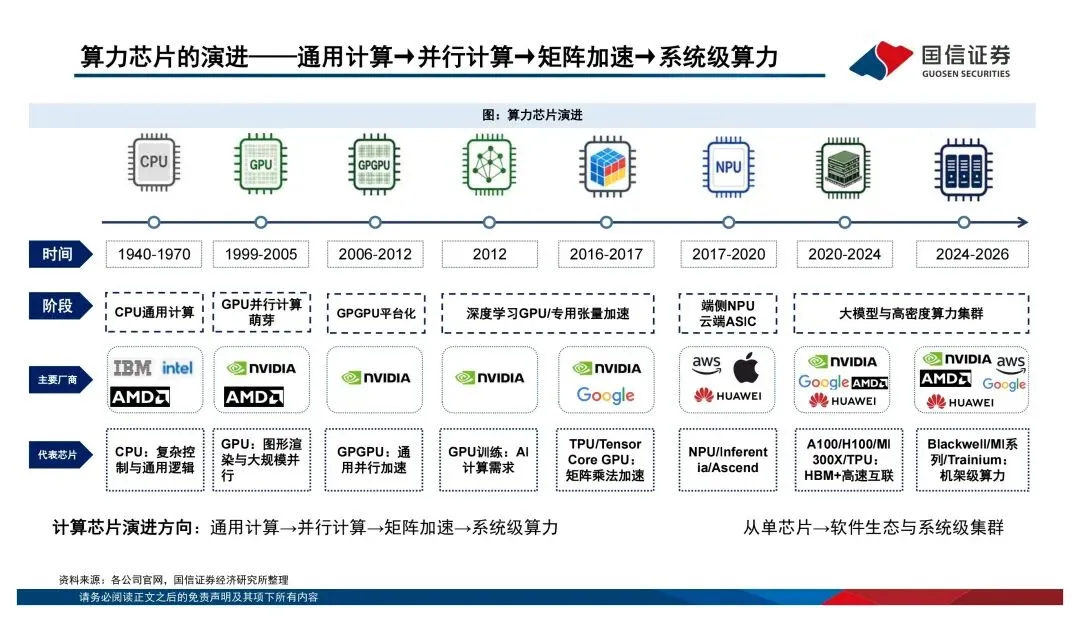
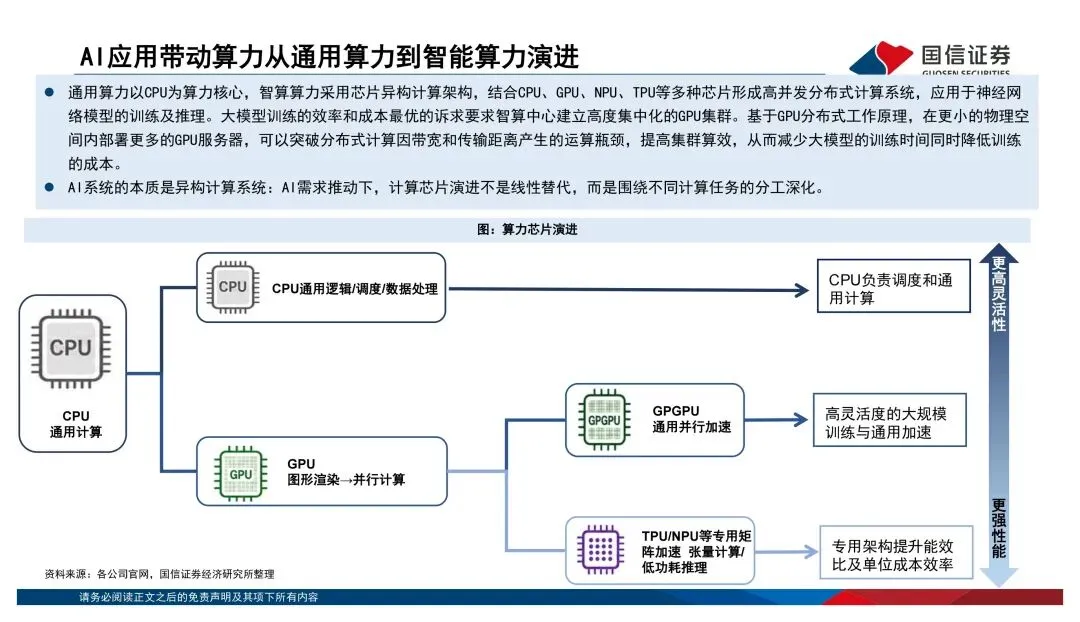
过去大家习惯看单芯片的算力跑分,比如FP16稠密算力多少T、显存带宽多少TB/s。但报告里反复强调一个观点:传统摩尔定律的边际效应在减弱,算力竞争已经从"单芯片峰值性能"转向了"系统级协同优化"。说白了,光靠制程升级已经不够了,得看芯片、先进封装、HBM、编译框架、液冷、大规模集群的综合效率。AI系统本质上是个异构计算体系——CPU负责调度,GPU干并行加速的活,TPU/NPU这类ASIC芯片则在特定场景下发挥效率和成本优势。不是谁替代谁,而是分工共存。海外巨头都在打"平台战"
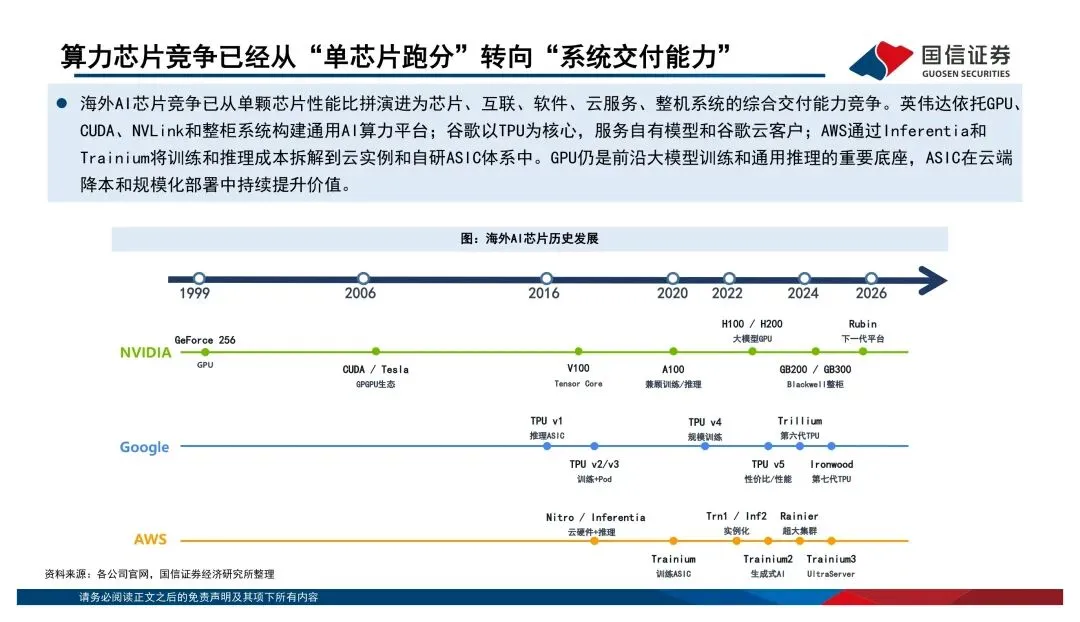
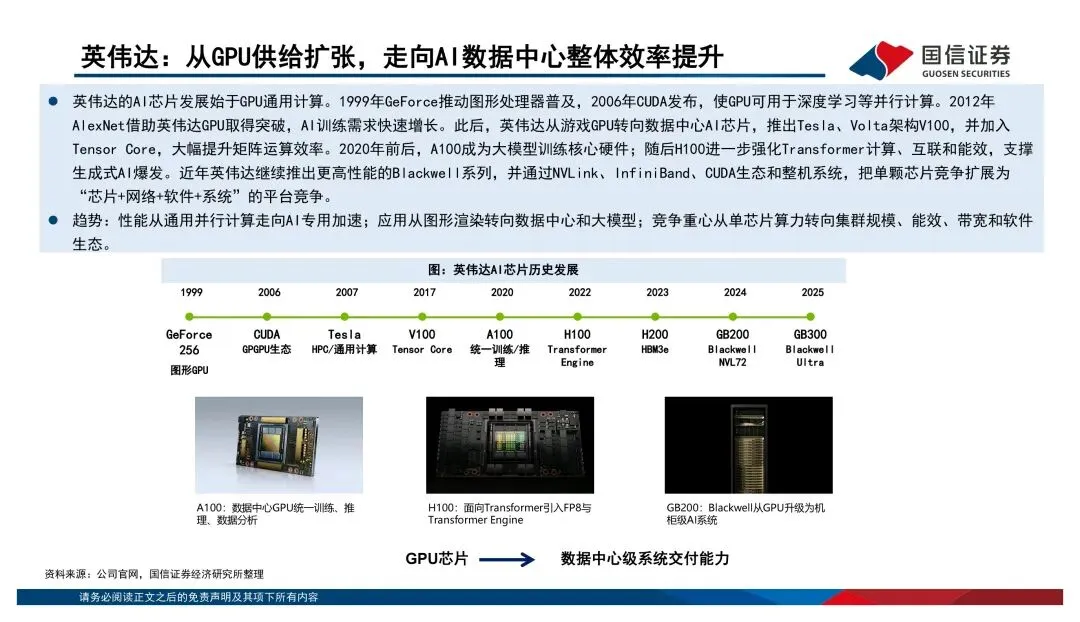
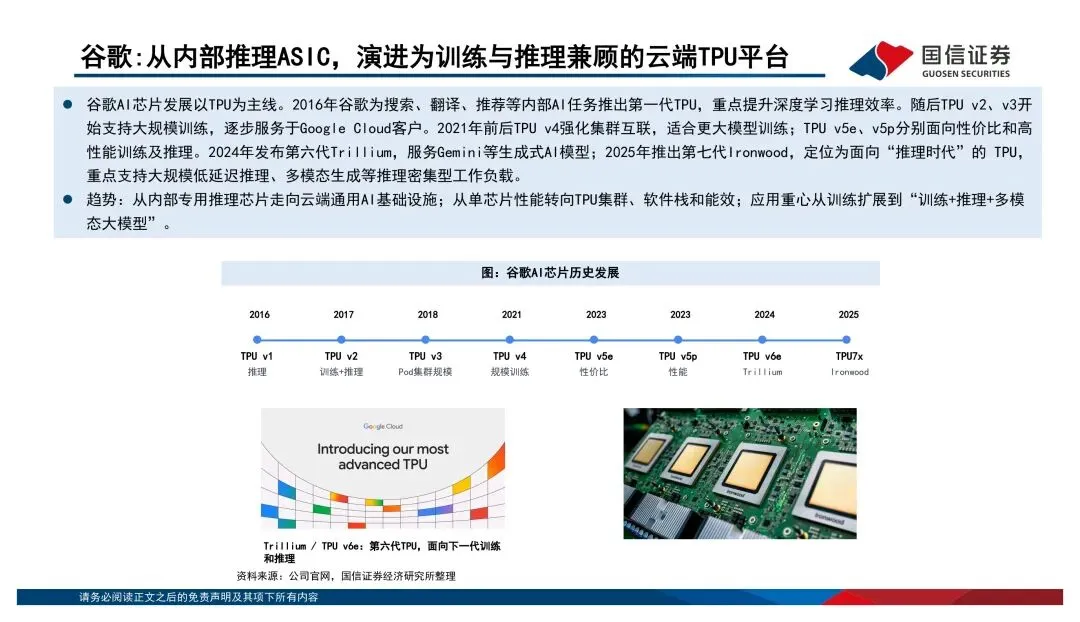
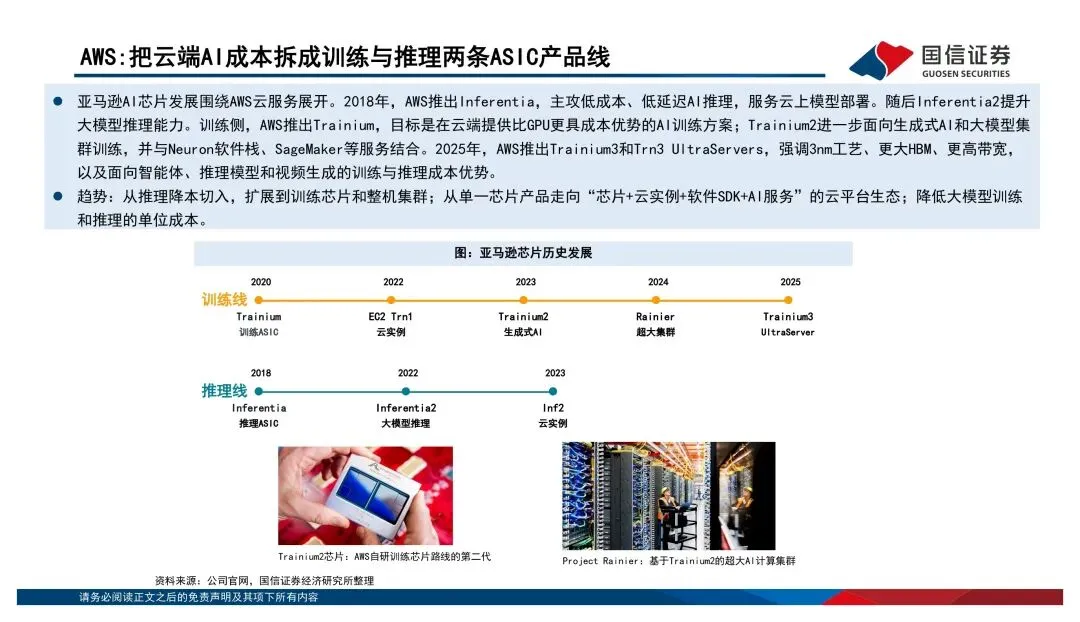
英伟达早就不是在卖单颗芯片了,GPU+CUDA+NVLink+整柜系统,卖的是整体算力解决方案。谷歌的TPU走的是内部推理到云端训练推理兼顾的路线,亚马逊的Inferentia和Trainium则是从云服务降本的角度切入。这三家的路径都不一样,但共同点是——竞争已经从单点性能升级到了平台级的交付能力。国产算力最值得关注的信号
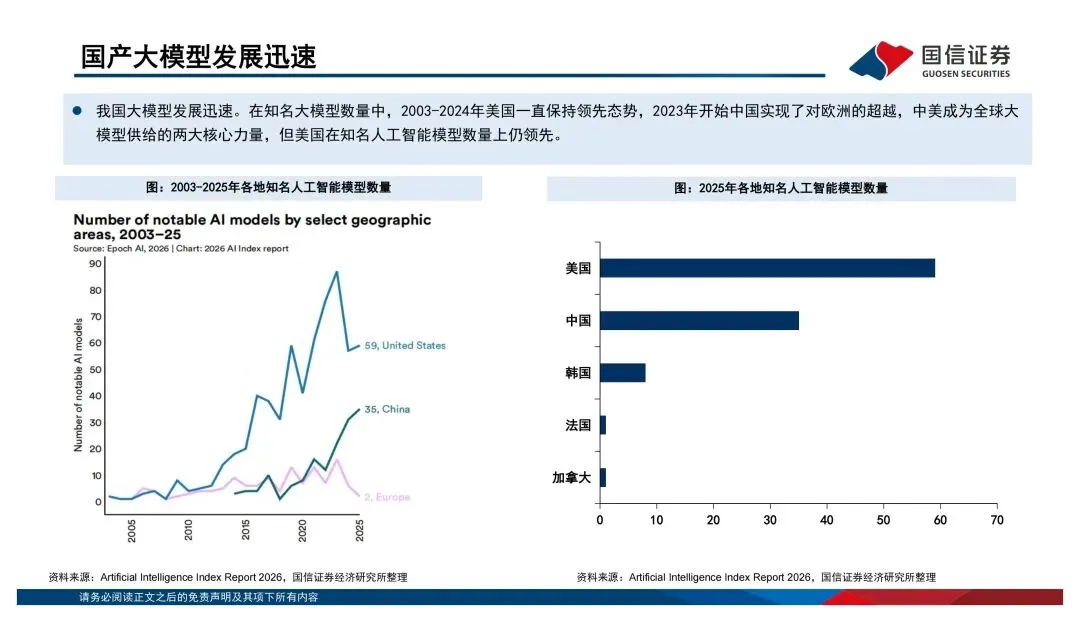
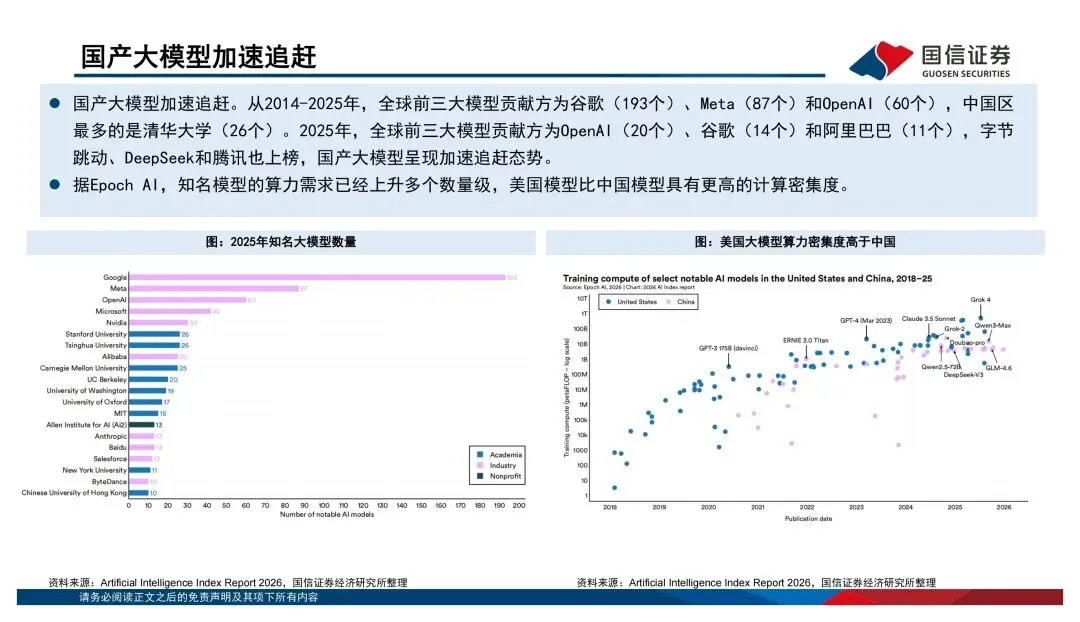
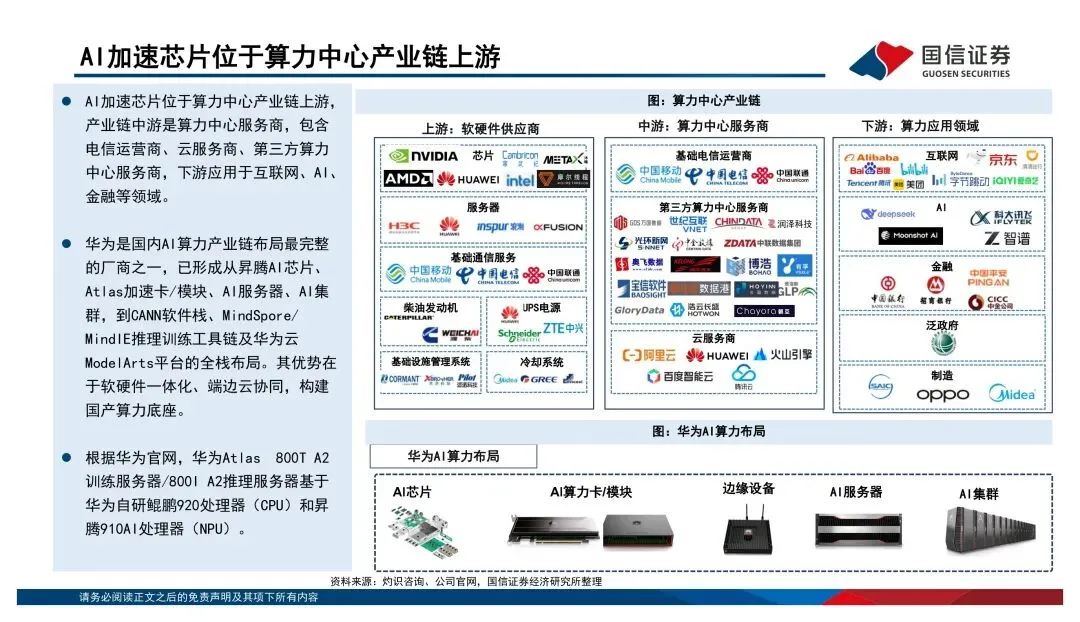
这份报告我觉得最有价值的部分,是对国产算力现状的梳理。2026年5月,国家首次在安全可靠测评里专门设立了AI芯片品类,华为海思昇腾310/910、平头哥真武M530/M890、壁仞壁砺166、海光DCU-3G等9款芯片通过了1级认证,正式纳入了信创体系。这是个标志性事件——信创从过去的通用算力国产替代,开始向智能算力基础设施升级了。再看市场份额,2025年中国AI加速卡总出货量约400万张,英伟达占55.2%,但华为已经占了20.4%,平头哥6.4%,寒武纪3.0%。国产厂商的份额在持续扩大,而且未来随着运营商和云计算厂商的需求释放,空间还很大。但要注意一点,国产算力的竞争焦点不应该是单卡峰值算力,而是全栈效率——芯片、HBM、互联、服务器、编译器、推理引擎、模型适配,缺一不可。谁能在这些环节上打通,谁才能真正吃到这波增量红利。
孔敏 女士
电话:15949179096
Email:kongmin@heliexpo.cn