Stata 双重机器学习--百科全书


写在前面:做实证研究的你,是不是也被"高维控制变量"折磨过?传统回归 control 二三十个变量,结果稳健性一塌糊涂。今天介绍一个神器——双重机器学习(DML),配合 Stata 的
ddml命令,几行代码就能轻松完成一篇顶刊级别的因果推断。
一、什么是双重机器学习?一句话说清楚
想象你要研究"数字化转型(D)对企业创新(Y)的影响"。
问题是你不可能观察到所有影响创新的因素。如果控制变量太少,遗漏变量偏差会让你高估或低估真实效应;如果控制变量太多(比如四五十个),传统 OLS 又会过拟合——模型在样本内拟合得极好,样本外预测一塌糊涂。
双重机器学习的核心逻辑就两步:
把复杂留给机器学习——用随机森林、Lasso 等算法灵活估计 D 和 Y 对高维控制变量 X 的依赖关系 把干净留给因果推断——对残差化后的变量做简单回归,得到无偏的因果效应估计
更妙的是,DML 通过交叉拟合(cross-fitting)解决了机器学习过拟合的问题:每个样本的预测值都来自"从未见过该样本"的模型,彻底消除了正则化偏差。
二、Stata 核心代码拆解
这是 DML 的完整最小可运行代码:
* 第1步:定义变量global Y Citedglobal D Dataglobal X Size Lev Roa Cash IAR Age Board i.id i.year* 第2步:初始化 + 交叉拟合 + 估计ddml init partial, kfolds(5)ddml E[D|X]: pystacked $D $X, type(reg) method(rf)ddml E[Y|X]: pystacked $Y $X, type(reg) method(rf)ddml crossfitddml estimate, robust六行命令,各司其职:
global | ||
ddml init partial | ||
kfolds(5) | ||
pystacked ... method(rf) | ||
ddml crossfit | ||
ddml estimate, robust |
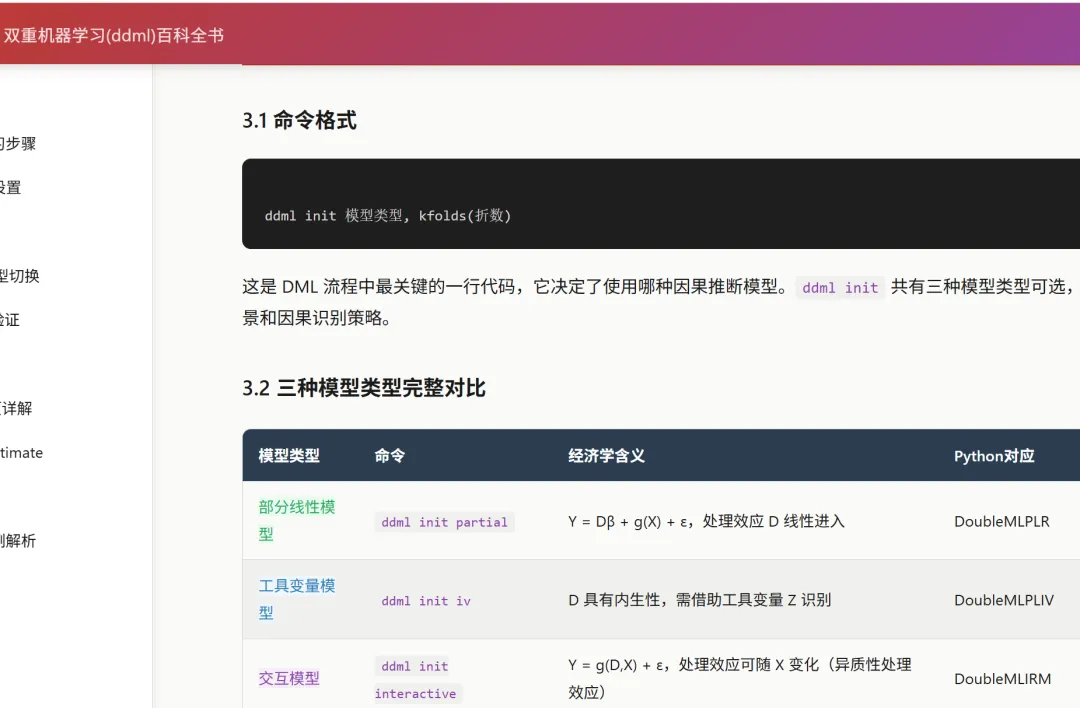
三、ddml init 三种模型,怎么选?
很多初学者卡在这一步:partial、iv、interactive 到底有什么区别?
模型一:partial(最常用)
适合场景:处理变量 D 没有内生性问题,你想估计一个"平均处理效应"。
ddml init partial, kfolds(5)这是 90% 论文的基准模型选择。
模型二:iv(工具变量)
适合场景:D 有内生性(比如遗漏变量、反向因果),需要工具变量 Z 来帮忙。
global Z IV // 定义工具变量ddml init iv, kfolds(5)ddml E[Z|X]: pystacked $Z $X, type(reg) method(rf) // 多这一行相比 partial 模型,iv 模型多了一个 E[Z|X] 学习器——工具变量在 DML 框架下也需要交叉拟合。
模型三:interactive(交互模型)
ddml init interactive, kfolds(5)ddml E[Y|X,D]: pystacked $Y $X $D, type(reg) method(rf) // 注意:变量里加了 $D关键变化:E[Y|X] 变成了 E[Y|X,D],允许 Y 对 D 的依赖关系随 X 变化。
interactive 模型可以估计 ATE(平均处理效应)和 ATTE(处理组平均处理效应)。
四、method(rf) 可以换成什么?
method() 选项指定具体的机器学习算法。pystacked 支持的方法非常多,论文中最常用的是这三个(当然这里method(nnet)没写上):
| 随机森林 | method(rf) |
| Lasso CV | method(lassocv) |
| 梯度提升 | method(gradboost) |
稳健性检验的标准操作:
基准回归用 method(rf),然后在稳健性检验中分别换成 method(lassocv) 和 method(gradboost)。如果三种方法结论一致,审稿人基本不会再质疑你的机器学习设定。
五、kfolds(5) 到底是啥?
常见取值:
kfolds(3):样本量较小时用kfolds(5):最常用,偏差与方差的最佳平衡kfolds(8):样本量充足时的稳健性检验
论文中的标准做法:基准用 kfolds(5),稳健性检验分别试 kfolds(3) 和 kfolds(8),验证结果不随折数变化。
注意:目前来说中文核心期刊上,kfolds(n)的取值有很多,一般先做一个,然后再变换。
六、实战
双重机器学习DDML专题--2025Stata寒假班--精彩回顾
直播回顾--机器学习基本原理、机器学习与双重差分、断点回归应用等
2024年8月Stata暑期班回顾丨因果推断&机器学习应用&异质性DID前沿&双重机器学习专题回顾


七、写在最后
双重机器学习不是"黑箱",而是一个把机器学习的长板(灵活拟合高维关系)和因果推断的长板(正交化消除偏差)结合起来的精密工具。
在 Stata 中,ddml + pystacked 的组合让这一切变得异常简单。你不需要写 Python,不需要调复杂的超参数,几行核心代码就能跑完一篇顶刊级别的 DML 分析。
当然,工具只是手段,好的实证研究仍然需要扎实的理论基础和可靠的数据。但掌握 DML,至少让你在处理高维控制变量时,多了一把锋利的刀。