模型网关产品与技术架构调研:六大开源方案横向拆解
对 NVIDIA Dynamo、llm-d、vLLM production-stack、AIBrix、KServe、Envoy AI Gateway 六个开源项目的产品定位、技术架构与设计取舍做横向剖析,提炼对自研模型网关的设计启示。资料截至 2026-06。
〇、一句话定位
这六个项目不在同一层。把它们硬放进一张"网关"对比表会失真——真正有用的拆法是三层心智模型:接入网关层、编排/控制面层、推理引擎层。它们大多解决的是"把单实例已经很强的 vLLM/SGLang,在数据中心规模下高效编排起来"这件事,差别在于切入的层次、对 Kubernetes 的依赖程度,以及谁来背书。
| NVIDIA Dynamo | |
| llm-d | |
| vLLM production-stack | |
| AIBrix | |
| KServe | |
| Envoy AI Gateway |
一、它们在共同对抗什么问题
2025 年初到年中,五个由大厂背书的"生成式 AI 规模化"框架集中出现。它们之所以同时诞生,是因为 vLLM 这类引擎把单实例推理做到了极致,但把上百个实例、跨节点、跨地域地稳定跑起来暴露出一批通用引擎/通用网关解决不好的新问题:
1. 请求长度高度可变——输入/输出 token 数从几个到几万不等,QPS/并发这类传统指标无法刻画负载,轮询路由会造成热点与延迟尖刺。 2. 有状态执行(KV cache)——prefill 产生的 KV cache 决定了后续吞吐,路由必须感知"哪个实例已缓存了这段前缀",否则重复计算昂贵。 3. Prefill / Decode 特性相反——prefill 计算密集、decode 访存密集且长尾。混跑互相拖累,于是出现 PD 分离——但 KV 要在两类 worker 间高速搬运。 4. 巨模型必须多节点——Llama-3.1-405B、DeepSeek-R1 671B 单机放不下,需要 TP/PP 跨节点编排、滚动升级、故障自愈——vLLM 本身不管这些。 5. 自动扩缩很难——DCGM 指标有限、扩缩呈非线性、冷启动慢(几十 GB 权重)。HPA 那套基于 CPU/QPS 的弹性几乎失效。 6. 异构 + 多租户 + 成本——混合 GPU 型号、多模型/多 LoRA 共享、SLO 与配额、按 token 计费与治理——这是"省钱"的真正战场。
六个项目就是从不同层次、用不同取舍来回答这六个问题。
二、逐个剖析
2.1 NVIDIA Dynamo
编排层 · NVIDIA · Apache-2.0 · 发布 GTC 2025-03 · 自研 Rust 代理 · K8s 可选 · 引擎 vLLM/SGLang/TRT-LLM
解决的核心问题:站在 GPU 卖方视角,把"每美元 token 产出"在数据中心尺度做到最大。它不假设你用 K8s,而是提供一套从路由、PD 分离到多级 KV 管理、动态 GPU 调度的完整自洽栈,引擎可插拔。
技术架构 · 四个关键件:
• Smart Router(Rust)——KV-aware 路由,按目标 worker 的 KV cache 命中重叠度打分选择,最大化前缀复用,而非轮询。用 Rust 写以压低代理本身的延迟。 • Disaggregated Serving——prefill 与 decode 拆成独立 worker 池,各自按特性配比与扩缩。 • KV Block Manager + NIXL——KV cache 跨 GPU/CPU/SSD/对象存储多级卸载;NIXL(NVIDIA Inference Xfer Library)是底层低延迟传输库,负责在 worker 与层级之间搬 KV。 • Planner——SLO 感知的动态 GPU 规划器,按负载实时调整 prefill/decode worker 数量。控制面用 etcd + NATS。
产品形态:可裸跑,也提供 Dynamo Operator + DynamoGraphDeployment CRD 跑在 K8s 上。多节点推理(PP)原生支持,是少数显式处理多节点的方案之一。
取舍:自带 Rust 代理而非复用 Envoy,性能上限高、但脱离 K8s/Envoy 生态,治理类能力(鉴权、配额、多厂商)需自行补齐。单公司(NVIDIA)主导,且对 NVIDIA 硬件栈最友好。适合:自有大规模 GPU 集群、追求极致单位成本、愿意采纳完整栈的团队。
2.2 llm-d
编排层 · Red Hat / IBM / Google · Apache-2.0 · 发布 2025-05 · Envoy + GIE · K8s 原生 · vLLM 优先
解决的核心问题:把 Dynamo 类的高级能力(PD 分离、KV 路由、前缀感知)标准化进 Kubernetes 生态,用社区中立的 Gateway API 而非私有代理。核心理念是"well-lit paths"——给出经过验证的推荐部署路径。
技术架构:
• Inference Gateway(IGW)——构建在 Gateway API Inference Extension(GIE)+ Envoy 之上。• Endpoint Picker(EPP)——推理感知调度器,做前缀缓存感知、负载感知的端点选择。这是 llm-d 的"大脑",也是 GIE 标准的参考实现。 • PD 分离——基于 vLLM + NIXL 做 KV 传输;KV 卸载复用 LMCache。 • 多节点——用 K8s 原生的 LeaderWorkerSet 编排,而非引入 Ray。
实测收益(社区/Tesla 案例):开启前缀缓存感知路由后,输出 token/s 提升约 3×、TTFT 降低约 2×。
取舍:押注标准(GIE)和多方治理是最大优势,也是最大风险——标准仍在演进、组件较新。强 K8s 绑定。NVIDIA 既是创始成员、又继续单干 Dynamo,存在路线博弈。适合:已 all-in K8s、看重生态中立与可移植、愿意跟随上游标准演进的团队。
2.3 vLLM production-stack
编排层 · UChicago LMCache · Apache-2.0 · Python Router · Helm · LMCache KV 卸载 · 轻量易上手
解决的核心问题:给 vLLM 用户一个开箱即用、逐块可替换的生产参考实现,门槛低。与 LMCache 同源,把 KV cache 跨实例共享/卸载(CPU、磁盘、远端)作为一等能力。它不追求大而全,而是"从零搭、每个积木在社区反馈下迭代"。
技术架构:Router 用 Python 实现(开发友好、但高并发下是潜在瓶颈),支持前缀感知路由、会话粘连路由。集成 LMCache 做分层 KV。自带 Grafana/Prometheus 观测面板与 Helm chart。也开始接入 Semantic Router、Envoy AI Gateway 做语义路由。
取舍:最容易理解和落地,但能力深度与大规模成熟度不及 AIBrix/Dynamo;Python 网关在极高吞吐场景需评估。适合:vLLM 单一引擎、中小规模、想要清晰参考实现并逐步扩展的团队。可作为自研网关的"读源码学习"首选。
2.4 AIBrix
编排层 · ByteDance → vLLM project · Apache-2.0 · 扩展 Envoy · K8s + Ray 混合 · 最新 v0.6.0/2026-03 · 引擎 vLLM/SGLang/Dynamo
解决的核心问题:字节在内部生产打磨 6+ 个月后开源,目标是企业级规模下的成本效率。核心论点:引擎层优化重要,但系统级编排(调度、扩缩、缓存感知路由、异构、跨集群)才是真正省钱的地方。宣称低流量场景 4.7× 降本、高负载 1.5× 降本。是六者中最成熟的单公司开源方案。
产品架构 · 控制面 / 数据面分离:
• 控制面——一组 K8s 自定义控制器:LoRA adapter 控制器、LLM-app 专用 autoscaler(PodAutoscaler)、冷启动管理、SLO 驱动的 GPU optimizer。 • 数据面——推理引擎(vLLM/SGLang/xLLM)+ 统一 AI Runtime sidecar:抽象厂商 API、标准化指标、模型下载与管理,是控制面与引擎之间的桥。 • LLM-aware 网关——扩展 Envoy,支持实例级路由、前缀缓存感知、最小 GPU 显存优先、SLO-aware router。通过 KV event 同步在 vLLM 实例与网关间共享 KV 状态以提升前缀命中。
技术架构亮点:
• 高密度 LoRA 管理——动态调度大量 LoRA adapter,混合负载下显著降本。 • 分布式 KV cache(自研)——跨节点 token 复用,论文称 +50% 吞吐、-70% 延迟。 • StormService——生产级 PD 编排原语(PodSet/RoleSet/PodGroup),支持按 role 独立扩缩、PD/拓扑感知路由、安全滚动升级。 • 混合编排——K8s 粗粒度资源管理 + Ray 细粒度执行;GPU 故障诊断与自愈。
取舍:功能最全、最贴近 vLLM、生产验证最充分,但组件多、运维心智负担重,且引入 Ray("编排器中的编排器")增加复杂度。单公司基因明显。适合:大规模、多模型/多 LoRA、强成本诉求、有专门平台团队的场景——也是自研网关在能力广度上最值得对标的范本。
2.5 KServe
通用模型服务 · CNCF · Apache-2.0 · InferenceService CRD · Knative 弹性 · LLMInferenceService + llm-d
解决的核心问题:早于 LLM 时代,目标是所有类型模型在 K8s 上的标准化服务:统一 CRD、版本管理、按需弹性(含缩到零)、灰度发布、predictor/transformer/explainer 流水线、Open Inference Protocol。它本来不为 LLM 而生——缺少 KV 协调、批调度、GPU 感知调度等 LLM 专属优化。
向 LLM 的演进:KServe 没有自己重造 LLM 轮子,而是整合 llm-d:新增 LLMInferenceService / LLMInferenceConfig CRD,底层用 Envoy + Envoy AI Gateway + Gateway API Inference Extension 做前缀缓存感知路由。Red Hat 在 llm-d 与 KServe 双边都有贡献者,两者组件互通(Tesla 生产案例即 KServe + llm-d + vLLM)。
取舍:最成熟的标准化外壳、CNCF 中立、生态最广(不止 LLM),但 LLM 能力靠 llm-d 嫁接、栈较重(Knative 等依赖)。适合:已有 KServe 平台、需要统一服务传统模型与 LLM、看重标准与多框架统一接口的组织。把它看作"服务平台底座 + llm-d 引擎"的组合,而非独立 LLM 网关。
2.6 Envoy AI Gateway
接入网关层 · Envoy / CNCF · Apache-2.0 · 基座 Envoy Gateway · 背书 Tetrate · Bloomberg · 前门/治理
解决的核心问题:这是唯一一个真正"网关"语义的项目,但它管的是接入与治理,不是 GPU 编排。把对内(自建 vLLM)与对外(OpenAI、Bedrock、Azure、Anthropic 等)的多种后端,统一成一套 OpenAI 兼容 API,并提供企业治理能力。
关键能力:
• 统一 API + 多厂商抽象——一个端点接多家上游,含上游凭据/鉴权管理与故障转移。 • 按 token 限流——以 LLM token 用量(而非请求数)为单位做限流与配额,贴合 LLM 计费模型。 • 接入 GIE——对自建后端可叠加 Gateway API Inference Extension,获得推理感知路由能力,与 llm-d/KServe 同一套底层。
取舍:它和上面五个不是竞争关系,而是互补——通常摆在它们前面做统一前门。本身不提供 PD 分离、分布式 KV 等引擎编排能力。适合:需要统一多模型/多供应商入口、做鉴权配额成本治理的场景。对自研网关而言,这是"接入/治理层"最直接的对标对象。
三、关键洞察:三层心智模型
把六个项目放回各自的层,混乱立刻消失。设计自研网关前,第一个决策是:你做的是哪一层,或哪几层?
┌─────────────────────────────────────────────────────────────┐│ LAYER 3 · 接入 / 治理 ││ 统一 API、多厂商、鉴权、按 token 限流、成本与配额 ││ → Envoy AI Gateway │├─────────────────────────────────────────────────────────────┤│ LAYER 2 · 编排 / 控制面 ││ KV 感知路由、PD 分离、分布式 KV、自动扩缩、多节点 ││ → Dynamo · llm-d · AIBrix · production-stack · KServe │├─────────────────────────────────────────────────────────────┤│ LAYER 1 · 推理引擎 ││ 单实例吞吐、KV cache、连续批处理、并行 ││ → vLLM · SGLang · TensorRT-LLM │└─────────────────────────────────────────────────────────────┘还有一条贯穿性的"共享地基"值得单独记住:Gateway API Inference Extension(GIE) + Envoy 正在成为 Layer 2/3 的事实标准——llm-d、KServe、AIBrix、Envoy AI Gateway 都在用;LMCache 是 KV 卸载的共享组件(production-stack、llm-d);NIXL 是 KV 传输的共享组件(Dynamo、llm-d)。只有 Dynamo 用自研 Rust 代理走了另一条路。
四、架构图谱(分层 × 组件矩阵)
五个逻辑层的职责固定如下,下表对比各产品在每层放了什么组件。"借助 X" = 能力来自所集成组件;"—" = 该层缺失或交由上游/下层。
各层职责
Dynamo
llm-d
vLLM production-stack
AIBrix
KServe
Envoy AI Gateway
五、进程视图(运行时进程边界)
同样的分层职责,运行时究竟跑在一个进程里,还是拆成多个进程跨网络协作?这直接决定性能、故障域、可独立扩缩性与部署复杂度。
贯穿性结论
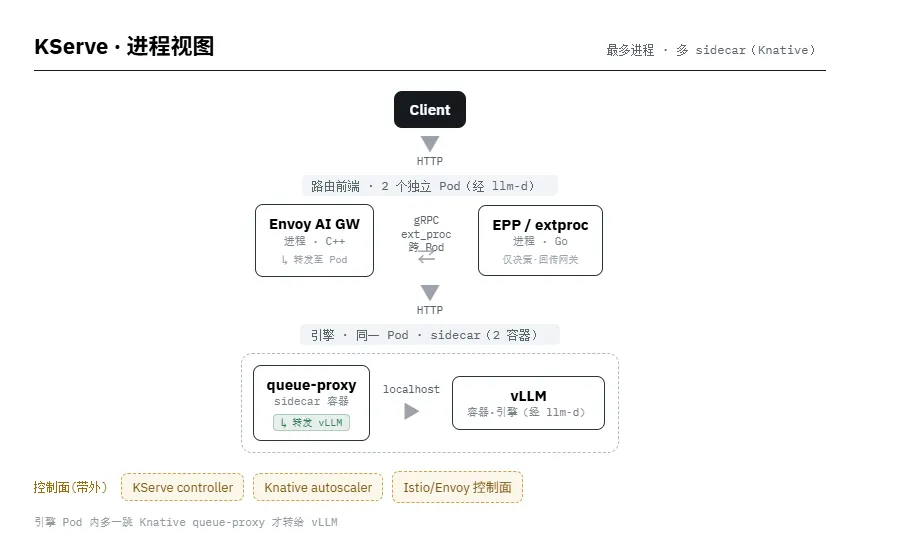
• 代理 ≠ 路由大脑,普遍是两个进程:Envoy(C++ 数据面)+ 外部处理器(ext_proc,gRPC 调用),让高性能代理与策略逻辑(Go/Python)解耦、各自独立扩缩。 • 控制面恒为独立进程、且"带外":扩缩/LoRA/编排控制器不在请求路径上,通过 K8s API/CRD 异步生效。 • KV cache 库内嵌在引擎进程;只有跨实例 / 分布式 KV 才是独立服务进程。PD 分离 = 不同进程,通常跨 Pod/节点,KV 经 NIXL 在进程间搬运。 • 到底哪个进程调用底层引擎实例? 在 Envoy+ext_proc 模型里,ext_proc/EPP 只做"选哪个实例"的决策并把结果回给 Envoy,真正建立连接、把请求发给引擎实例的是 Envoy 数据面进程本身,不是路由大脑。例外:production-stack 由 Router(Python) 直接调用;Dynamo 由 Router 经 NATS 派发给 Worker;KServe 在引擎 Pod 内还要多一跳 Knative queue-proxy 才转给 vLLM。 • 部署形态标注: [ ]= 独立 Pod(跨 Pod 网络调用);{ }= 同一 Pod 内 sidecar(2 容器,localhost);↳= 发起对引擎实例调用的进程。
Dynamo — 多进程 · 自研分布式运行时(NATS/etcd)
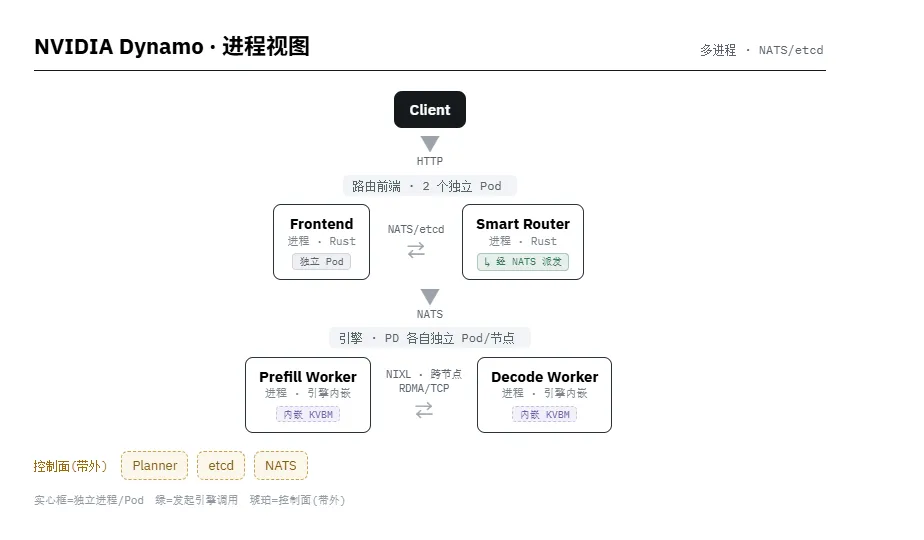
llm-d — 多进程 · Envoy + ext_proc 经典拆分
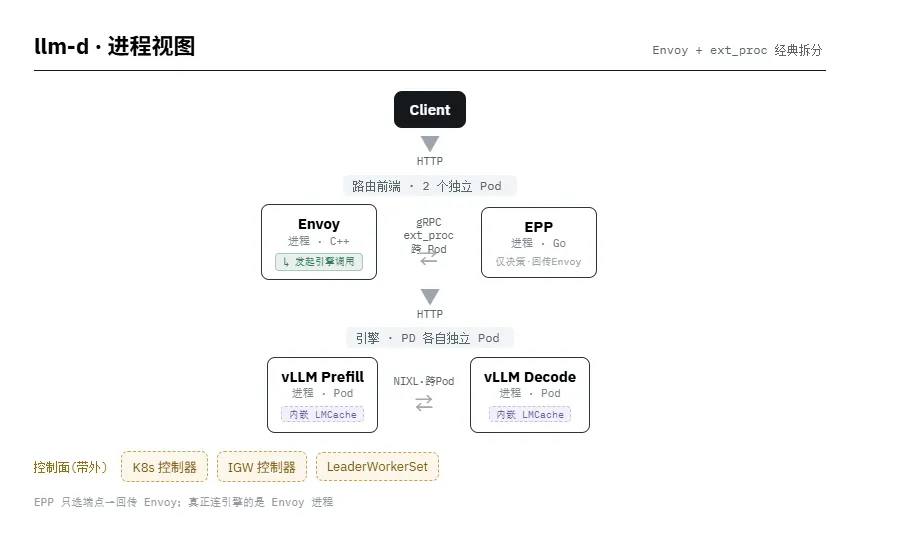
vLLM production-stack — 少进程 · 代理+路由同进程
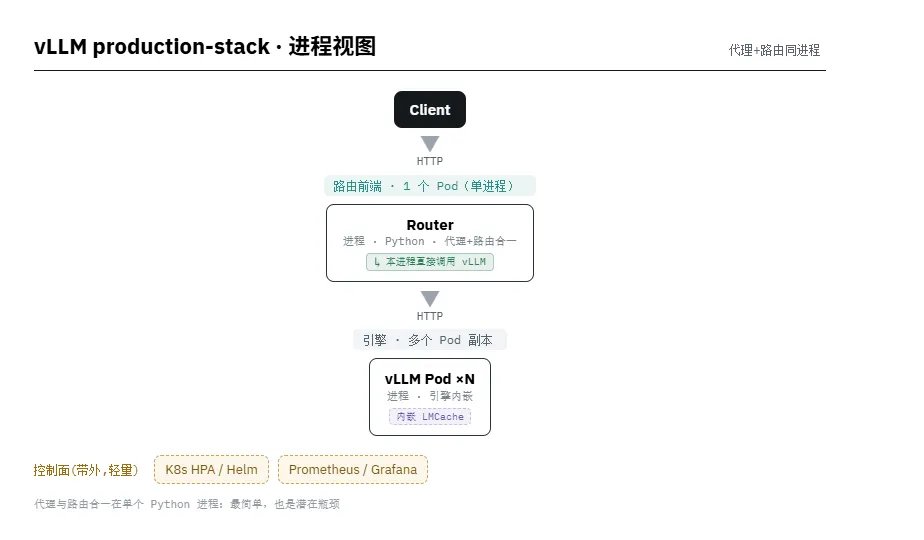
AIBrix — 多进程 · Envoy+plugins + 引擎 sidecar
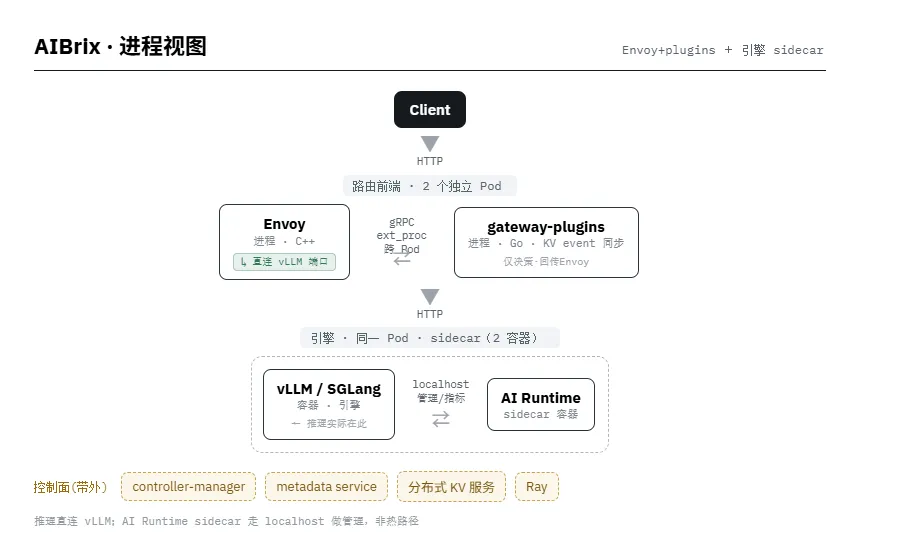
KServe — 最多进程 · 多 sidecar(Knative)
Envoy AI Gateway — 2 进程 · 无本地引擎/KV 进程
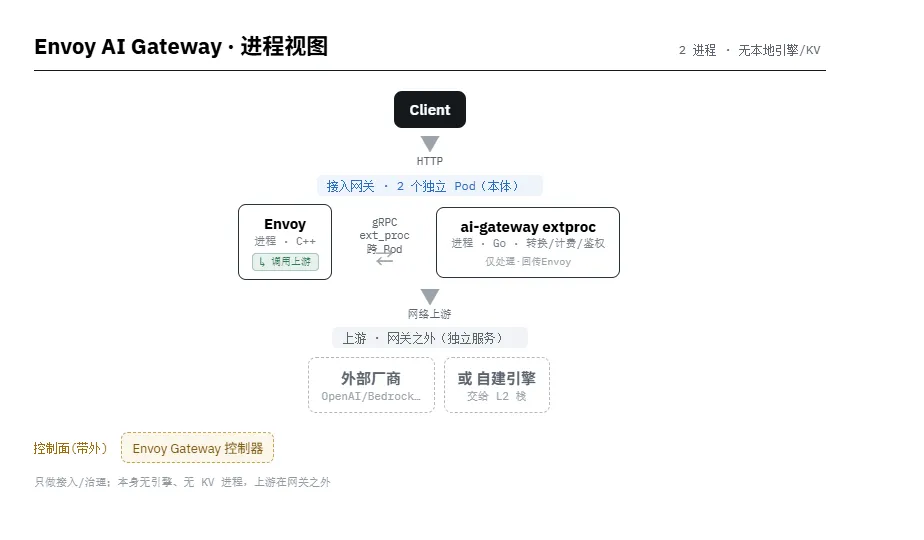
读图要点:请求路径上的进程越多,单跳延迟越多但可独立扩缩/隔离故障;production-stack 进程最少(1 个路由进程)最简单;KServe 进程最多(含 Knative queue-proxy 等 sidecar)最重;Envoy 系普遍采用「数据面 + ext_proc」两进程模型——其中 ext_proc 只决策,由 Envoy 数据面进程真正发起对引擎实例的调用。
六、横向对比
表 A · 定位与生态
表 B · 技术能力
注:LWS = LeaderWorkerSet;GIE = Gateway API Inference Extension;EPP = Endpoint Picker。"经 llm-d / GIE" 指能力来自所集成的下层组件而非自身实现。
七、对自研模型网关的启示与建议
① 先定层,再定边界不要做一个"什么都管"的网关。明确你的"网关"是 Layer 3 接入治理(对标 Envoy AI Gateway),还是 Layer 2 编排控制面(对标 AIBrix/llm-d),抑或两层都要、但内部清晰分层。最常见且健康的形态是:Layer 3 做前门(统一 API / 鉴权 / 限流 / 多后端),Layer 2 做 KV 感知路由与编排,两层通过标准接口解耦。
② 路由必须"推理感知",轮询是基线之耻六个项目的最大公约数就是抛弃轮询。最低限度要做前缀缓存感知路由(把同前缀请求送到已缓存该前缀的实例),收益是 token/s 3× 量级。进阶维度:负载感知、最小 GPU 显存优先、SLO 感知、会话粘连。强烈建议直接采纳 Gateway API Inference Extension(GIE)+ Envoy 作为路由地基,而不是自研代理——除非你有 NVIDIA 级别的性能诉求和团队。
③ KV cache 是一等公民,需要全局视图路由质量取决于网关能否看到各实例的 KV 状态。借鉴 AIBrix 的 KV event 同步(实例向网关上报 KV 状态)与 LMCache 的跨实例 KV 卸载/复用。是否引入 PD 分离取决于规模——它收益大但显著增加 KV 搬运与编排复杂度,中等规模可以先不做,但路由与缓存层要预留演进空间。
④ 复用标准与开源组件,避免自研全栈生态已收敛到 Envoy + GIE(路由)、LMCache(KV 卸载)、NIXL(KV 传输)。站在这些之上把精力投到差异化(你的调度策略、成本模型、多租户治理),比重造代理/KV 层划算得多。Dynamo 的全自研路线只在极致性能 + 强团队时才成立。
⑤ 控制面 / 数据面分离 + Runtime sidecarAIBrix 的架构最值得抄:控制面(控制器:扩缩、LoRA、冷启动、GPU 优化)与数据面(引擎 + 统一 Runtime sidecar)解耦。Runtime sidecar 抽象不同引擎的 API 与指标,让你能多引擎(vLLM/SGLang/Dynamo)共存、平滑替换,是工程上的关键解耦点。
⑥ 扩缩与可观测要 LLM 专用不要用 QPS/CPU 驱动 HPA。采集 LLM 专用指标(队列深度、running/waiting 序列、KV 利用率、TTFT/TPOT),用 SLO 驱动扩缩,并正视冷启动(权重几十 GB)——预热、本地缓存、缩到零的取舍要早做。把这些指标统一标准化是 Runtime sidecar 的职责。
一句话建议:以 Envoy + Gateway API Inference Extension 为路由地基,参照 AIBrix 的控制面/数据面分层与 Runtime sidecar 抽象,把 前缀缓存感知路由 + LLM 专用扩缩 + KV 全局视图 作为第一版必做能力;PD 分离、分布式 KV、多节点按规模分阶段引入。差异化投在调度策略、成本/SLO 模型与多租户治理上。
参考来源
• github.com/ai-dynamo/dynamo · NVIDIA Dynamo 文档 • llm-d.ai · "Production-Grade LLM Inference at Scale with KServe, llm-d, and vLLM" • docs.vllm.ai/projects/production-stack · vLLM Production Stack 文档 • github.com/vllm-project/aibrix · 发布说明 · arxiv 2504.03648 · blog.vllm.ai (2025-02) • kserve.github.io · LLMInferenceService 文档 • aigateway.envoyproxy.io · Envoy AI Gateway 文档 • neureality.ai · 框架横向评述(2025-12)