系列导读训练只是 AI 故事的"上半场"。模型上线那一刻,问题陡然变多:用户在哪?模型部在哪?多模型怎么分发?API Key 怎么管?跨地域调用怎么不绕一圈地球?推理网络,是 AI 工程化最容易翻车的一环。这是系列的最后一篇,专门讲它。
一、推理网络的真实痛:流量模型变了,传统负载均衡失效
大模型推理和传统Web服务的流量长得完全不一样:
"输入短、输出长":用户一句话提问,模型可能吐10KB 文本回来;
流量非对称、突发性强:流式输出导致带宽利用极不均匀;
不同请求消耗资源差异巨大:一个简单问候可能 100ms 出结果,一个深度思考占满GPU几十秒;
新协议涌入:MCP、A2A 等智能体协议高频交互、小包密集,传统TCP/UDP负载均衡器根本读不懂。
结论:老一套的"按连接数 / 请求数做轮询"在 AI 推理面前彻底失效。
要解,必须重新设计推理网络的"四层架构"。
二、推理网络的四层架构
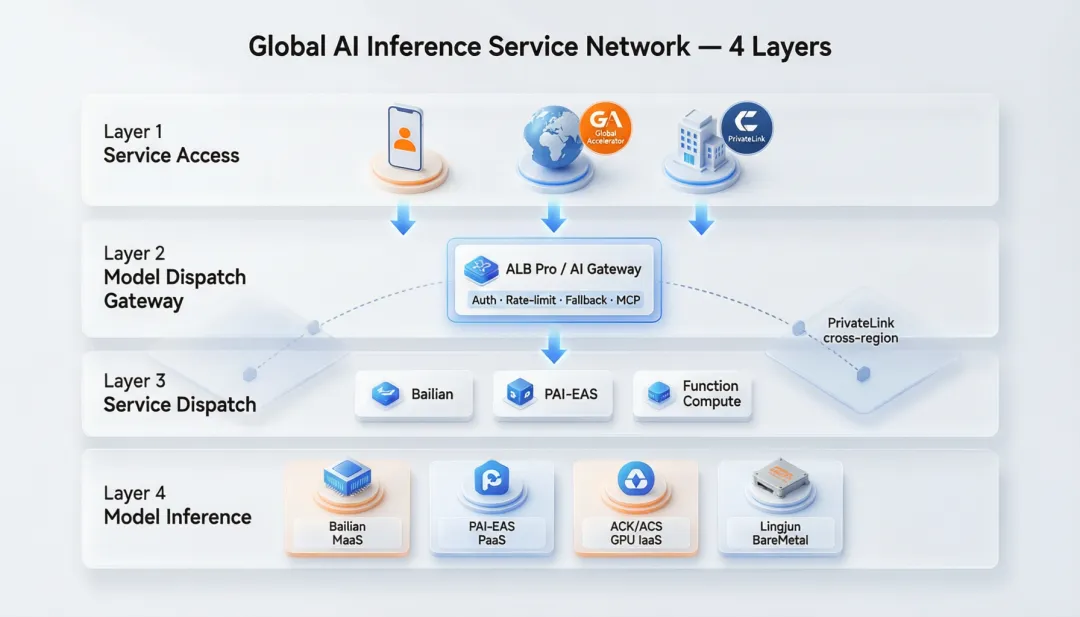
从网络视角自上而下看大模型推理,可以分成 4 层:
| 服务接入层 | ||
| 模型分发层 | ||
| 服务分发层 | ||
| 模型推理层 |
下面逐层拆。
三、模型推理层:四种部署形态,各有适用场景
模型部哪里,决定了网络怎么搭。
① 百炼(MaaS 化)
模型托管在百炼账号里,公网默认走dashscope.aliyuncs.com;
想走私网?用PrivateLink打通用户 VPC 和百炼,调私网域名。
适合:直接调通义、DeepSeek 等模型;不想运维。
② PAI-EAS(PaaS 化)
应用型专属网关直接生成在用户 VPC 内,用户VPC可以直接私网调用;
共享网关/全托管专属网关托管在 PAI 平台,需要把EAS实例关联到用户VPC才能私网调;
支持自动扩缩容、灰度发布、一键压测。
适合:已经在PAI训练好的模型一键上线推理。
③ Function Compute GPU(PaaS化 - Serverless)
容器镜像作为函数的交付物;
用ALB或API网关做触发器,请求过来才拉起 GPU 实例。
适合:Stable Diffusion、ComfyUI、RAG 等"按需调用、波峰波谷明显"的场景。
④ 灵骏 /EGS/ACK/ACS(IaaS 化)
用户自己拉GPU、自己部署模型;
用ALB扩展版挂载GPU集群,做推理任务分配和调度。
适合:自训自有模型、有强定制要求。
四、模型分发层:ALB扩展版 = AI时代的"智能路由器"
这一层是整套架构里最值得展开的——它是 AI 推理的"灵魂"。
① 做推理入口网关 / 多模型分发网关
ALB 扩展版直接是一个AI 网关,开箱即用:
入向身份认证:JWT / API Key
出向身份认证:API Key 池管理、多 Key 轮转
模型代理:原生支持百炼、OpenAI 等
服务调度:按模型名称选择不同后端
Fallback:主模型限流/出错时,自动降级到次优模型
Token 限速:按请求 / 响应 / 总 Token 数限速,支持 Header / Query / Cookie / IP 多维匹配
划重点:这些不是 4 层 LB 能干的事,必须是懂 AI 协议的应用层网关。
② 做自建模型的负载分担网关
传统 LB 用连接数判负载,对 AI 不适用。
ALB 扩展版的做法:基于反馈机制的流量调度——
后端 GPU 实时上报队列长度、KV Cache 占用等指标;
网关根据指标判断"忙不忙",把新请求路由到最闲的实例。
这才是 AI 推理该有的负载均衡。
③ 做 MCP 分发网关
MCP(Model Context Protocol)让 Agent 能调用各种外部工具。但工具数量一旦多起来,Agent 就被各种 API 协议淹没。
ALB 扩展版能做的事:
API 协议转换为 MCP:让存量 API 服务直接接入 Agent;
统一身份权限管理:后端服务接入更安全;
工具聚合 + 查找优化:扩展 Agent 能调用的工具数量与效率。
一句话:MCP 网关是 Agent 时代的"南北货港口",ALB 扩展版顺势成了它的承载产品。
五、服务接入层:用户在哪,网络就铺到哪
用户分三类,网络方案完全不同:
① 本地互联网用户
直接用模型分发网关的公网域名就行。
② 异地互联网用户(含海外)
用全球加速GA,在用户就近的接入点接进阿里云全球骨干网,再回到模型所在 Region。
GA 还有两个 AI 特性值得点名:
同一个 HTTP(s) 监听支持多地域源站——可做异地多活、灰度发布、流量调配;
HTTP(s) 流量支持按规则跨地域流量镜像——把推理请求镜像到另一地域的训练集群"喂"训练。
③ 阿里云上的企业用户
同 Region:用CEN打通 VPC,调私网域名;
跨 Region:用PrivateLink 跨地域连接,直接挂载推理模型。
PrivateLink 跨地域是个被低估的能力:让推理服务提供方"一处部署、全球私网就近开放",使用方不用搞复杂中转网络,直接挑近的接入点连。这对跨地域推理调用的运维复杂度是降维打击。
六、规划落地:4 个标准动作
最后一篇了,来个最实用的清单。任何企业上线 AI 推理服务,都跑不掉这 4 步:
Step 1|分清你的"用户在哪"
本地用户 → 公网;异地用户 → GA;云上企业用户 → CEN / PrivateLink。先回答这个问题,再选产品。
Step 2|模型部署形态选定
怎么选?看团队能力和成本敏感度:
不想运维 → 百炼
自有模型 + 弹性 → PAI-EAS / FC GPU
强定制 + 长期跑 → 灵骏 / ACK + ALB 扩展版
Step 3|把模型分发层"立起来"
强烈建议:哪怕只有一个模型,也部一个 ALB 扩展版做分发层。原因有三:
后续加模型零成本;
API Key 管理与限速天然需要;
Fallback 是大模型 SLA 的命门。
Step 4|跨地域用 PrivateLink 跨地域 + GA 流量镜像
推理就近接入用 GA;
跨 Region 调用模型用 PrivateLink 跨地域连接;
想做训推一体?用 GA 流量镜像,把线上推理流量"喂"回训练集群。
七、写在最后:网络是 AI 时代的"水电煤"
回看这一系列三篇文章:
第一篇
讲数据怎么从全球漂流回来——靠的是 EIP 池 / NAT / PrivateLink 代理 / CEN+TR;
第二篇
讲训练算力怎么池化——靠的是 200Gbps RDMA / 400Gbps 专线 / 倒换组 / Tbps 骨干 / ZooRoute;
第三篇
讲推理服务怎么落地——靠的是 ALB 扩展版 / GA / PrivateLink 跨地域 / 4 层架构。
它们指向同一个判断:
算力是新型生产力,但算力的效率,由网络决定。"算网协同"和"以网增算",是 AI 基础设施的下一个十年。
如果你正在搭建企业 AI 平台,把这三篇当作入门检查清单。
如果你已经踩过坑,希望这三篇至少帮你定位了"自己卡在哪一层"。
