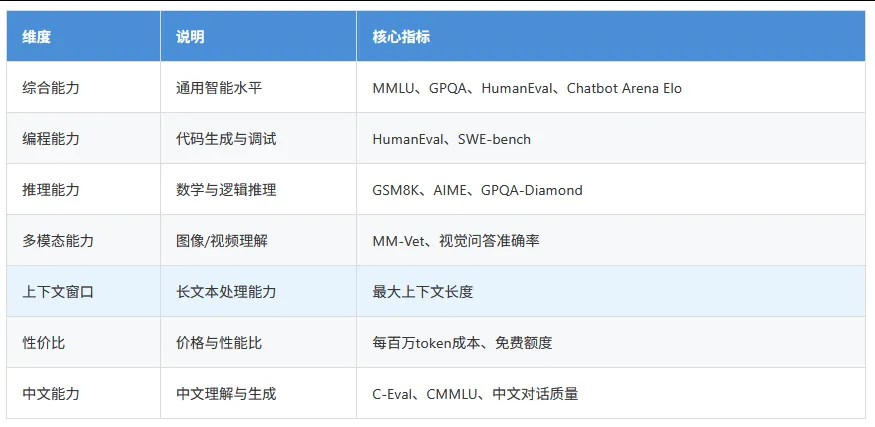
评估框架说明
本报告从以下 7个维度 对主流大模型进行评估:
主流模型一览
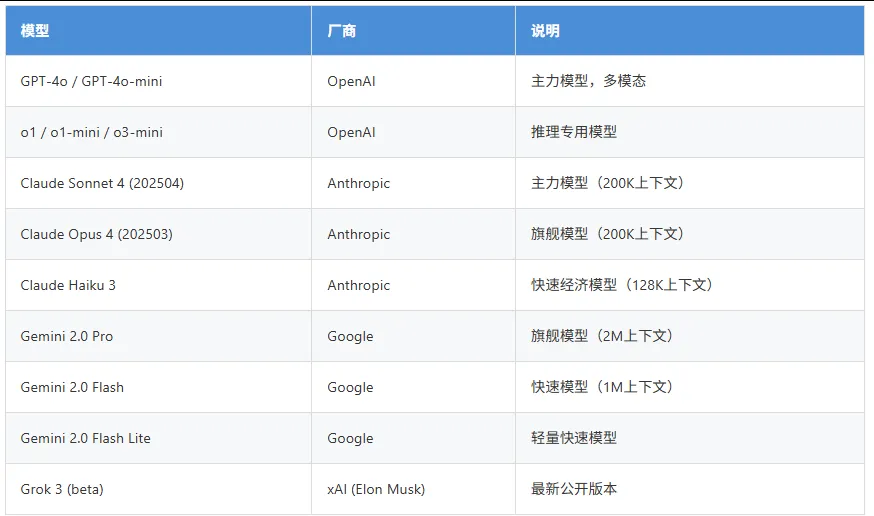
2.1 闭源模型(API调用)
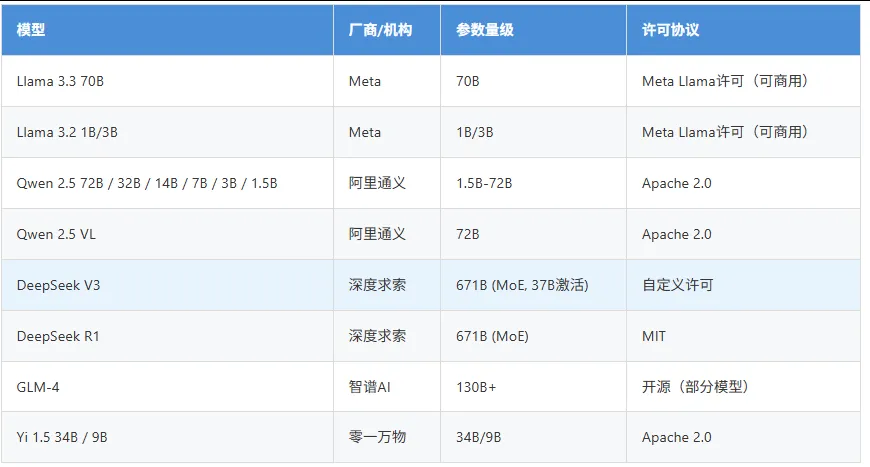
2.2 开源/可商用模型
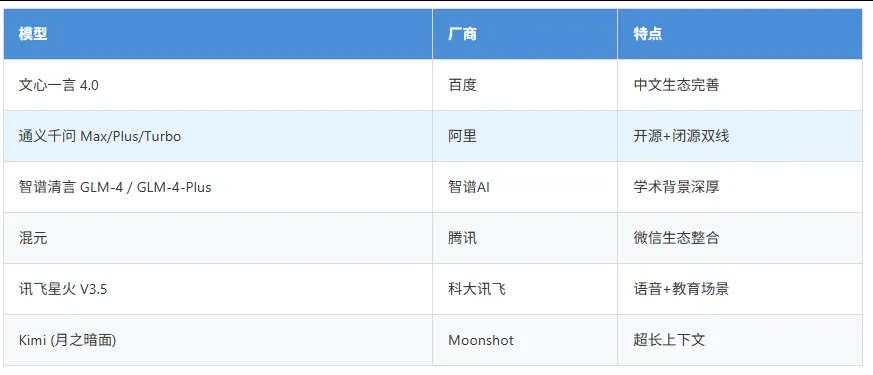
2.3 中国厂商模型(API/平台)
三基准测试数据对比
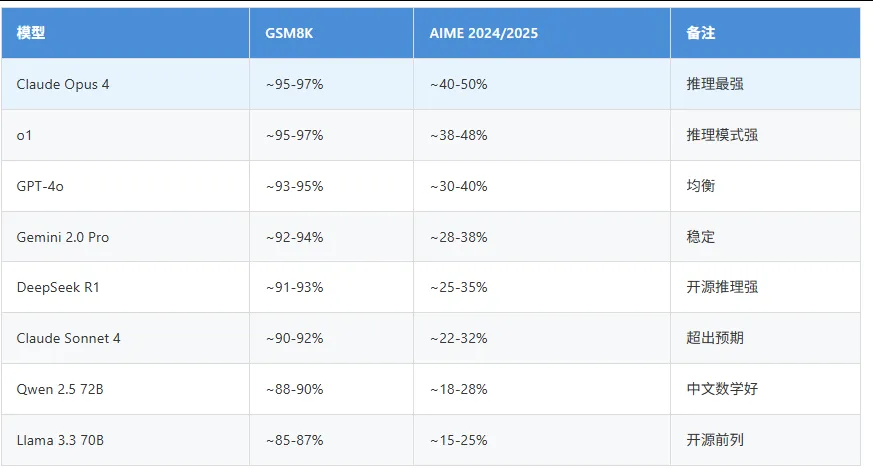
3.1 通用能力(MMLU / MMLU-Pro)
MMLU: Massive Multitask Language Understanding,涵盖57个学科的选择题测试
MMLU-Pro: MMLU的增强版,增加推理步骤要求
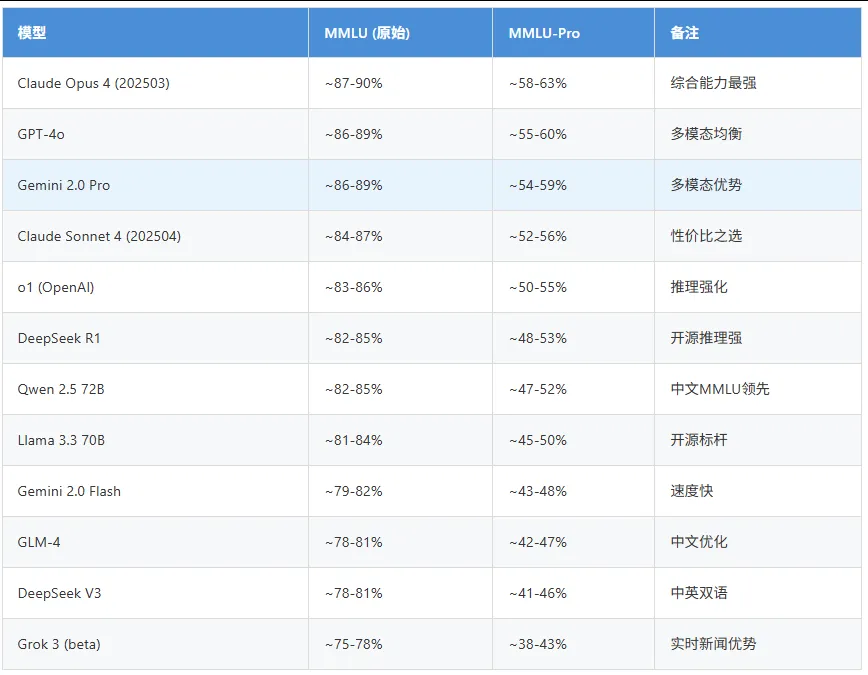
3.2 研究生级知识(GPQA-Diamond)
GPQA-Diamond:由领域专家编写的694道高难度科学问题(物理/化学/生物),通过率极低
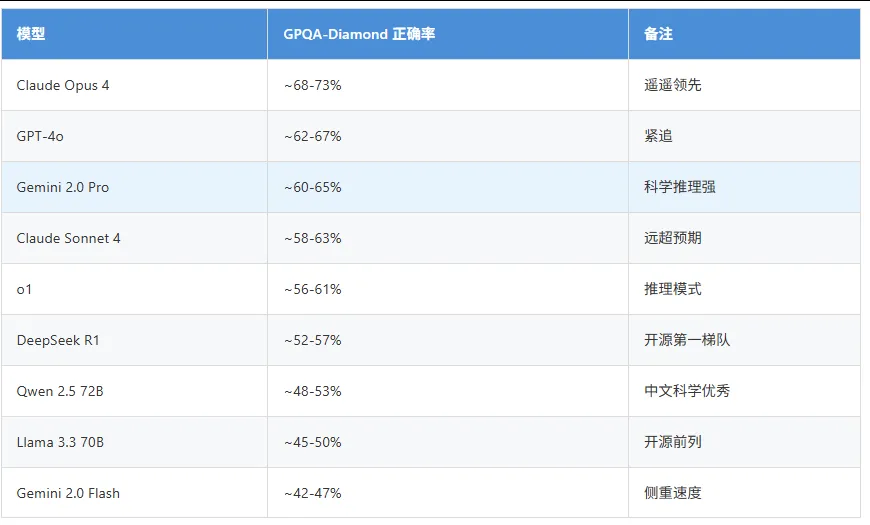
3.3 编程能力(HumanEval / SWE-bench)
HumanEval: Python编程问题解决(164道题)
SWE-bench: 真实GitHub issue修复(工程级测试)
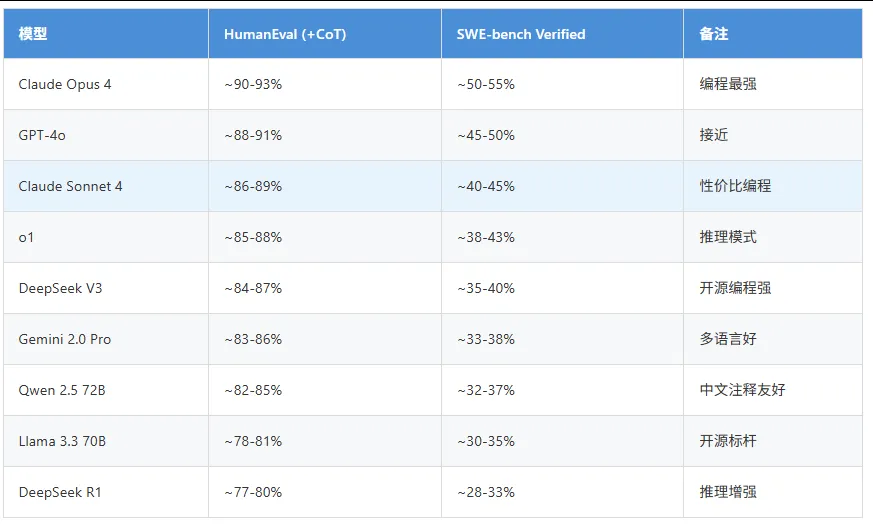
3.4 数学推理(GSM8K / AIME)
GSM8K: 小学到初中数学题(8.5K道)
AIME: 美国数学邀请赛(高中竞赛级)
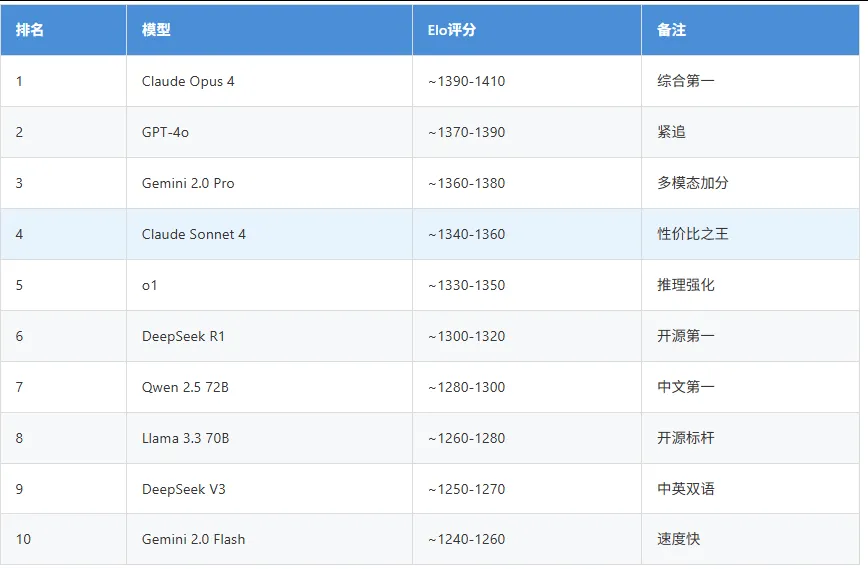
3.5 Chatbot Arena Elo排名(LMSYS)
Chatbot Arena: 双盲随机对比测试,基于用户投票的Elo评级(越高越好)截至2026年中数据(近似值,持续波动)
价格对比
4.1 闭源模型价格(每百万token美元计价)
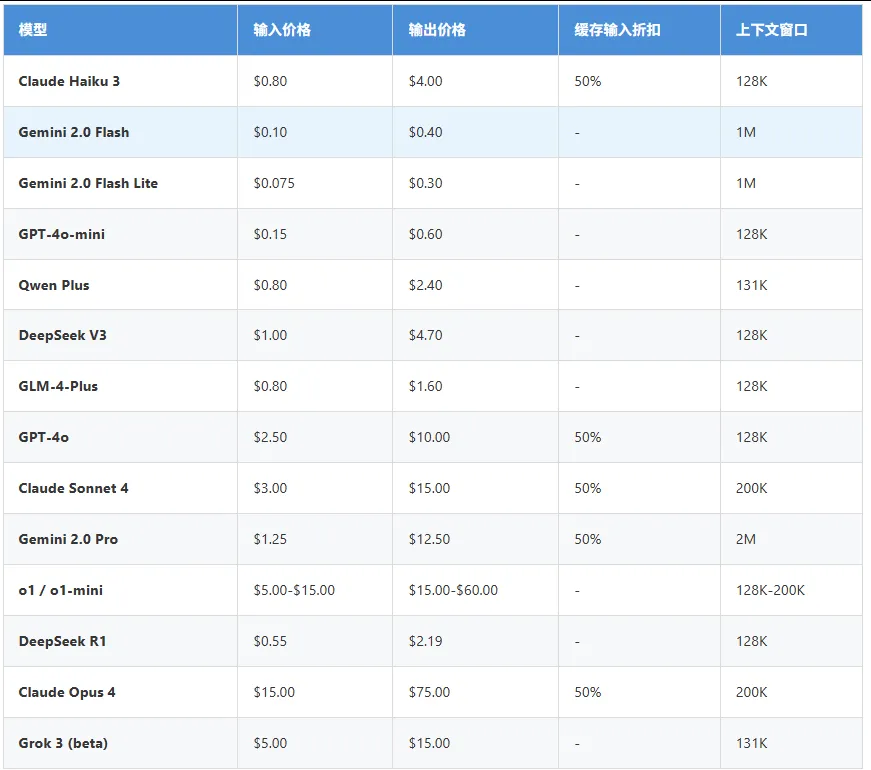
中文平台: 阿里云百炼、智谱开放平台、百度千帆等常有免费额度或更优惠定价
4.2 开源模型自部署成本
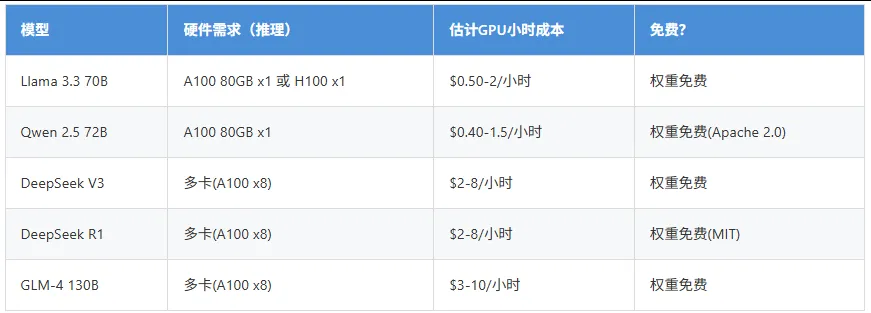
免费额度参考:
Qwen: 免费API调用额度充足(阿里云百炼) DeepSeek: 每月免费额度 Llama系列: 完全免费(需自备硬件或使用HuggingFace Spaces) GLM-4: 智谱开放平台有免费额度
各模型详细分析
5.1 Claude Opus 4 (Anthropic)

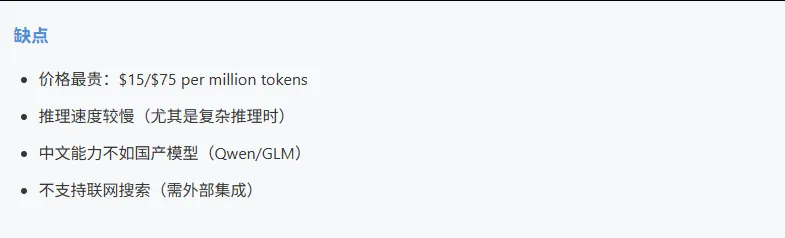
适合: 科研分析、复杂编码、法律/金融等专业领域、需要最高质量的场景
不适合: 预算有限的项目、纯中文场景、需要高速响应的应用
5.2 GPT-4o / GPT-4o-mini / o1 (OpenAI)
GPT-4o
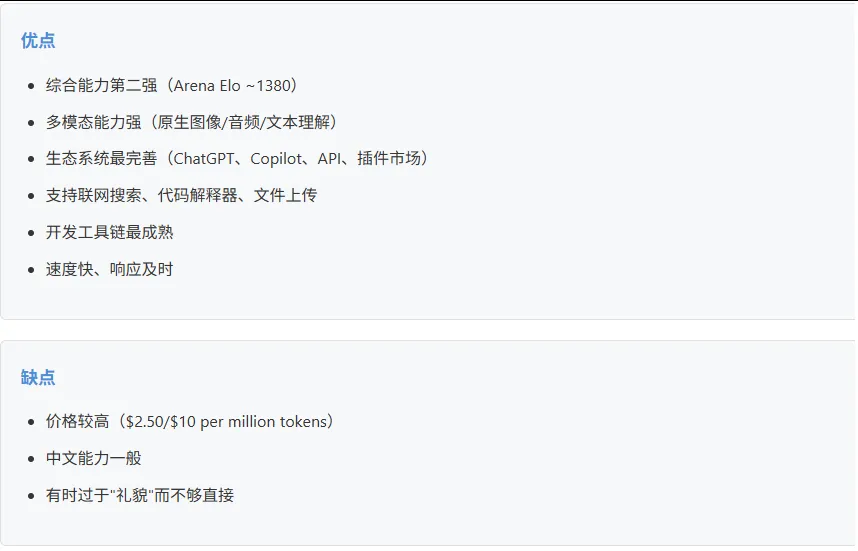
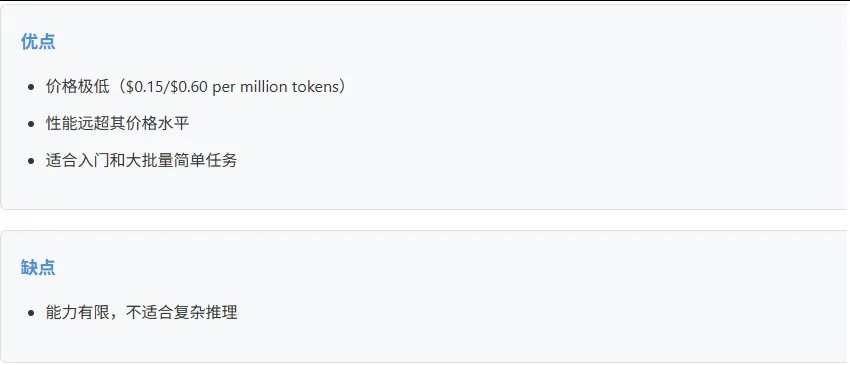
GPT-4o-mini
o1 (推理专用)
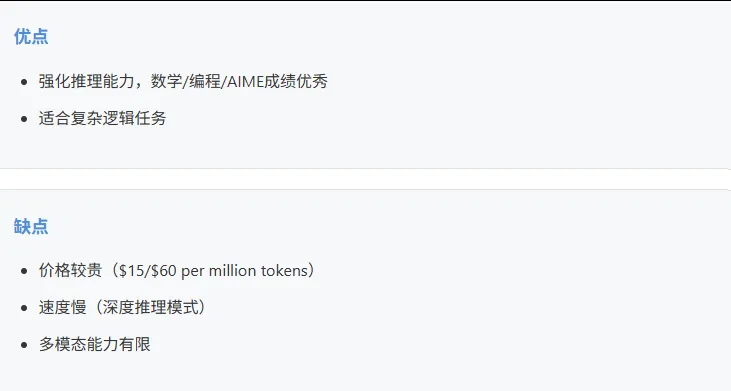
适合: GPT-4o适合日常多模态应用;GPT-4o-mini适合预算敏感场景;o1适合推理密集型任务
5.3 Gemini 2.0 Pro / Flash (Google)
Gemini 2.0 Pro
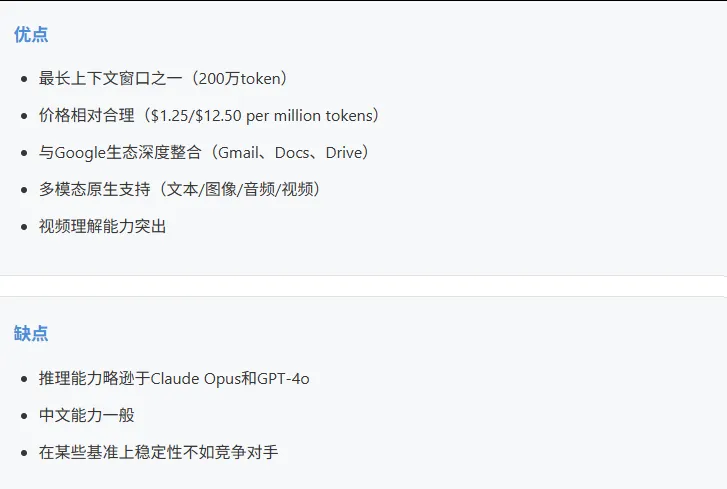
Gemini 2.0 Flash
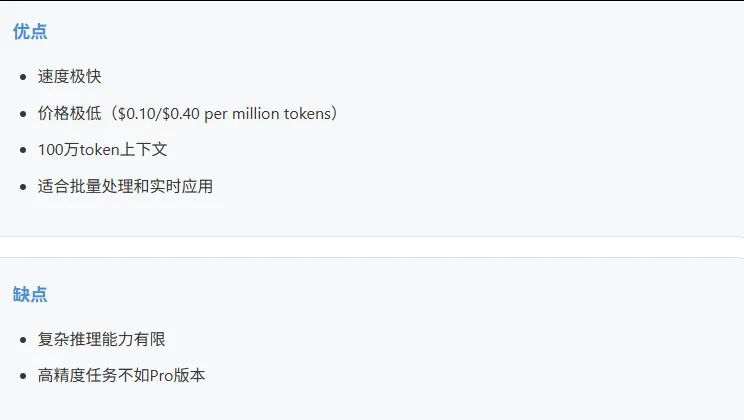
适合: 长文档分析、批量文本处理、视频理解、需要低成本大规模调用的场景
5.4 Claude Sonnet 4 (Anthropic)
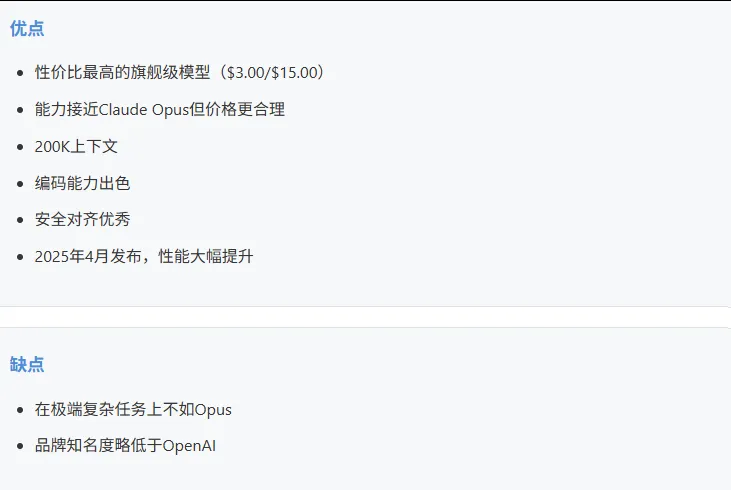
适合: 大多数生产环境的首选、编码助手、商业应用
5.5 Qwen 2.5系列 (阿里巴巴)
Qwen 2.5 72B (开源)
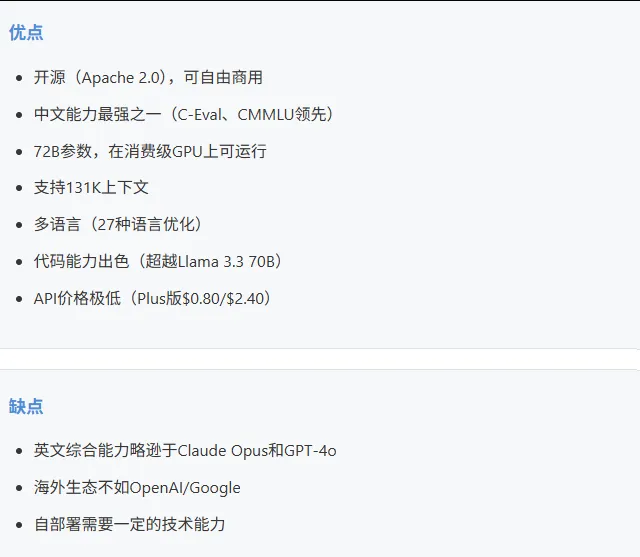
Qwen API系列 (Max/Plus/Turbo)
- Max
: 最强版本,对标GPT-4级别 - Plus
: 性价比最优,$0.80/$2.40 - Turbo
: 最快版本
适合: 中文场景首选、需要自部署的企业、预算有限的团队
5.6 DeepSeek V3 / R1
DeepSeek V3
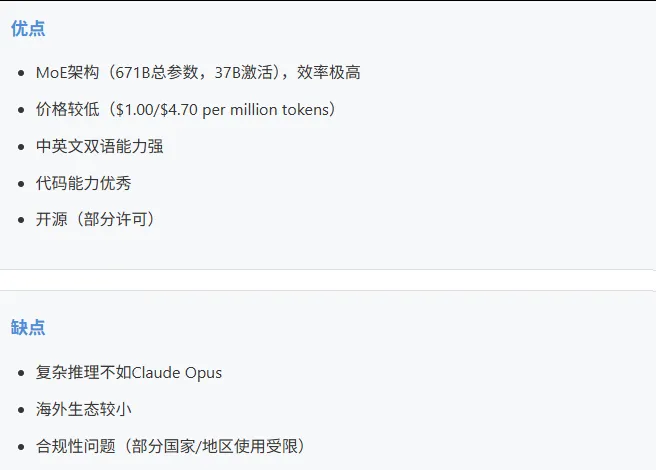
DeepSeek R1
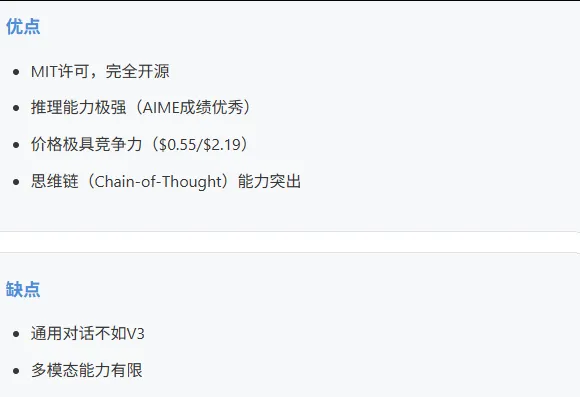
适合: 预算敏感项目、推理密集型任务、需要开源模型的场景
5.7 Llama 3.3 70B / Llama 3.2 (Meta)

适合: 数据敏感场景、需要高度定制化的企业、开发者社区
5.8 GLM-4 (智谱AI)
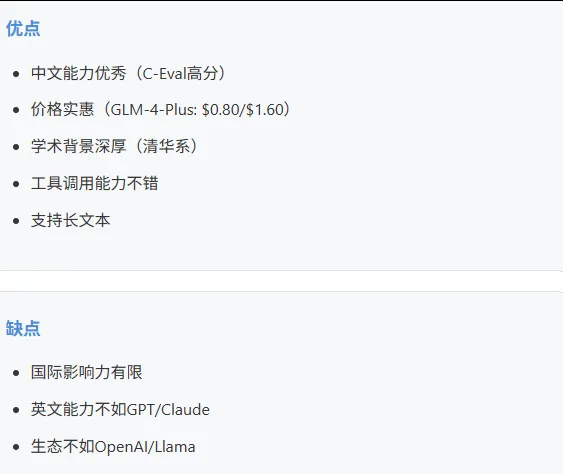
适合: 纯中文场景、学术用途、预算有限的国内项目
5.9 Grok 3 (xAI)
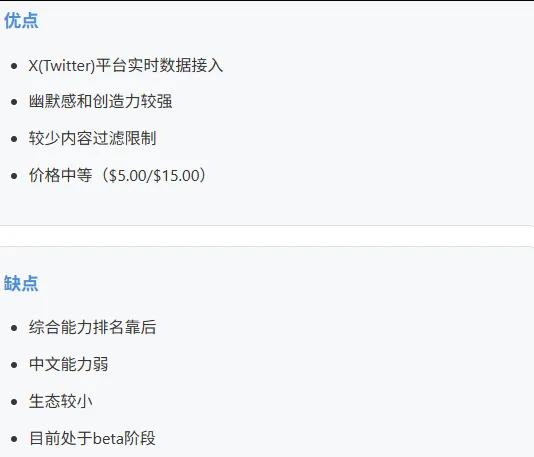
适合: X平台开发者、需要实时社交媒体数据的场景
中文能力专项对比
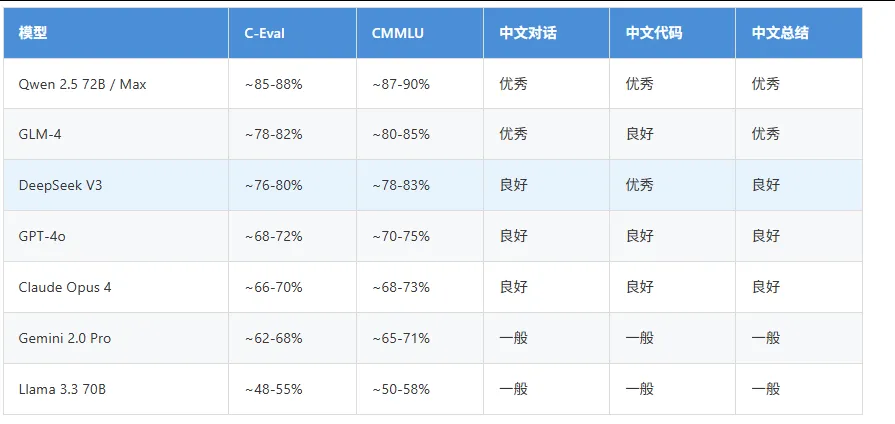
中文场景推荐排序: Qwen > GLM > DeepSeek > GPT-4o ≈ Claude > Gemini > Llama
决策指南:如何选择
7.1 按场景选择
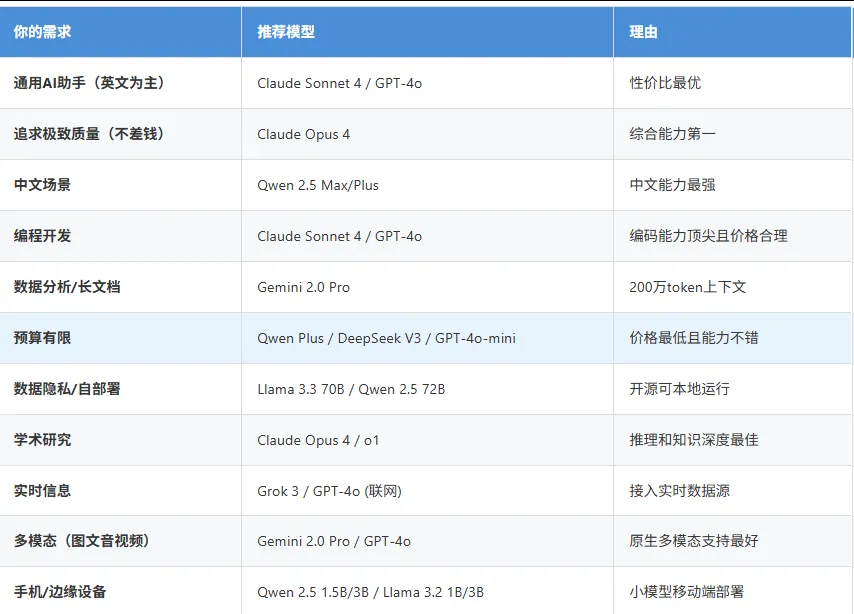
7.2 按预算选择
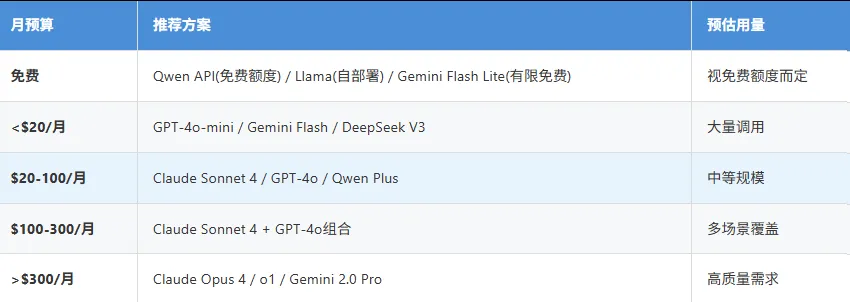
7.3 按技术能力选择

常见误区
误区1:"参数越多越好"
事实: MoE架构的DeepSeek V3(671B总参数/37B激活)在多项基准上超过密集架构的Llama 70B
关键: 训练数据质量 > 参数量
误区2:"开源的一定不如闭源的"
事实: Qwen 2.5 72B在中文场景下超过GPT-4o-mini,DeepSeek R1在推理上接近Claude Sonnet
关键: 开源模型进步极快,特定场景可能反超
误区3:"越贵的越好"
事实: Claude Sonnet 4 ($3/$15) 的能力已非常接近Claude Opus 4 ($15/$75),但价格便宜80%
关键: 根据任务复杂度选择,简单任务用便宜模型即可
误区4:"一个模型走天下"
事实: 不同模型在不同任务上有明显差异
建议: 复杂系统应采用多模型路由(简单任务用便宜模型,复杂任务用顶级模型)
误区5:"中文场景一定要用国产模型"
事实: GPT-4o和Claude Opus在中文任务上已经相当不错
关键: 如果涉及专业领域中文(法律/医疗/政务),国产模型仍有优势
总结与建议
给AI新手的最终建议
- 入门首选: 直接用 ChatGPT (GPT-4o) 或 Claude (Sonnet 4) 的网页版,无需编程
- 开始调用API: 从 GPT-4o 或 Claude Sonnet 4 开始,价格适中、文档完善
- 中文优先: 选择 Qwen Plus 或 智谱GLM-4-Plus,价格低中文好
- 预算紧张: DeepSeek V3 或 GPT-4o-mini,$0.15/百万token起
- 数据安全: 自部署 Llama 3.3 70B 或 Qwen 2.5 72B
- 长期学习: 了解多模型组合策略,不要绑定单一供应商
趋势展望
- 开源追赶迅速: Qwen 2.5和DeepSeek R1已接近闭源模型的第一梯队
- 价格战持续: 模型能力提升的同时价格不断下降,2026年已成为"AI平民化"元年
- 多模态成为标配: 纯文本模型逐渐被淘汰,视觉/音频/视频理解成为基本要求
- 中文模型崛起: Qwen、GLM等在中文场景已全面超越国外模型
- 推理专用模型兴起: o1、R1等推理专用模型在数学/编程/科学领域展现独特优势
- 超大上下文成为卖点: Gemini 2.0 Pro的200万token上下文引领长文档处理趋势