过去一年,AI 圈最火的词叫Agent。
创业公司融几千万美金要做 agent,大厂发布会连着念十遍 agent,技术大会排满 agent workshop,独立开发者熬夜啃各种 agent 框架的文档——LangGraph、CrewAI、AutoGen、Swarm,一个比一个花哨,一个比一个重。
然后 OpenAI 官方出了一份 34 页的白皮书,标题朴素得像课堂讲义:A Practical Guide to Building Agents(构建智能体实用指南)。
翻完之后你会发现,整份文件的核心可以浓缩到极致:
Agent 就是一个 while 循环。
运行模型 → 调用工具 → 拿到结果 → 反馈回去 → 重复,直到退出条件满足。没了。
一条推文,把 34 页浓缩进一张图
6 月 28 日,X(推特)用户 @shmidtqq 发了条帖子,直接引爆了开发者社区。
"OpenAI published a 34-page guide on building AI agents. The whole thing reduces to one idea: an agent is a loop."
「OpenAI 发了一份 34 页的 AI agent 构建指南。整份文件归结为一个想法:agent 就是一个循环。」
"The key insight: the agent is not the model, it is the loop around it."
「关键洞察:agent 的本质是围绕模型的那个循环,模型只是循环里的一个零件。」


▲ @shmidtqq 的推文获得 172 赞、1.6 万次浏览,把 34 页白皮书压缩成了一张卡片
这条帖子很快在 X 上被开发者讨论。有人回复说 "the agent is the loop not model frfr"(agent 指的是循环,模型只是里面的一环,认真的),有人立刻追问 PDF 在哪儿下载。
▲ @0xCristal 回复:agent 就是那个循环,真的
为什么这句话能激起这么大反响?
因为它戳破了一个持续了一年多的泡泡——大家以为 agent 是某种神秘的、需要特殊框架才能实现的高级 AI 系统。结果 OpenAI 亲口告诉你,核心架构就是你大一学 C 语言时写的那个 while 循环。
OpenAI 官方白皮书到底写了什么?
这份指南发布在 OpenAI 的 Business 页面上,面向的是"正在探索构建第一个 agent"的产品和工程团队,内容来自 OpenAI 在大量客户实际部署中积累的经验。
▲ OpenAI 官方落地页:A practical guide to building agents
指南开门见山给了 agent 一个定义——
"Agents are systems that independently accomplish tasks on your behalf."
「Agent 是能够独立代表你完成任务的系统。」
注意那个"独立"。简单聊天机器人、单轮 LLM 调用、情感分类器,这些都不算 agent。它们用了大模型,但没有让模型去控制工作流的执行。
真正的 agent 有两个标志:
第一,用 LLM 管理工作流。模型能识别任务是否完成、主动纠错、失败时交还控制权。
第二,访问并调用工具。根据当前状态动态选择工具,在明确的 guardrails(护栏)内运行。
然后指南给出了 agent 最基本的三个组件:
- Model
(模型):驱动推理和决策的 LLM - Tools
(工具):模型能调用的外部函数或 API - Instructions
(指令):告诉 agent 怎么做、边界在哪的明确规则
到这里都还算常规。真正让人拍大腿的是下一章——编排(Orchestration)。
编排的核心:一个 While 循环
白皮书原话:
"This concept of a while loop is central to the functioning of an agent."
「这种 while 循环的概念是智能体运行的核心。」
什么意思?
OpenAI 把 agent 的运行方式拆解成了一个循环:模型运行 → 决定是否调用工具 → 调用工具 → 获取结果 → 把结果喂回模型 → 模型再次运行 → 再决定……如此反复,直到触发退出条件。
退出条件有三种常见形式:
调用了"最终输出工具"(明确标记任务完成) 模型返回了不带任何 tool call 的回复(直接回答用户) 报错,或达到最大轮次上限
用 Python 伪代码写出来,大概就是:
while not done: response = call_llm(messages) if response.tool_calls: results = execute_tools(response.tool_calls) messages.append(results) else: done = True 这就是全部。
一个 while 循环,包着一个模型调用和一组工具。它能跑起来,能停下来,中间能执行外部操作。这就是 agent。
OpenAI 甚至在指南里建议:先把单 agent 做好,别急着上多 agent。给一个 agent 配足够多的好工具,比一上来就搞什么 swarm(蜂群)靠谱得多。只有当指令已经复杂到模型持续选错工具的时候,才考虑拆分成多个 agent。
第三方独立印证:Claude Code 也是这个架构
如果只是 OpenAI 自己这么说,你可能觉得是王婆卖瓜。
但独立技术平台 Braintrust 在一篇博文里也得出了完全相同的结论:
"Surprisingly, many of the most popular and successful agents, including Claude Code and the OpenAI Agents SDK, share a common, straightforward architecture: a while loop that makes tool calls."
「令人惊讶的是,许多最流行、最成功的 agent,包括 Claude Code 和 OpenAI Agents SDK,都共享一个简单明了的架构:一个执行工具调用的 while 循环。」
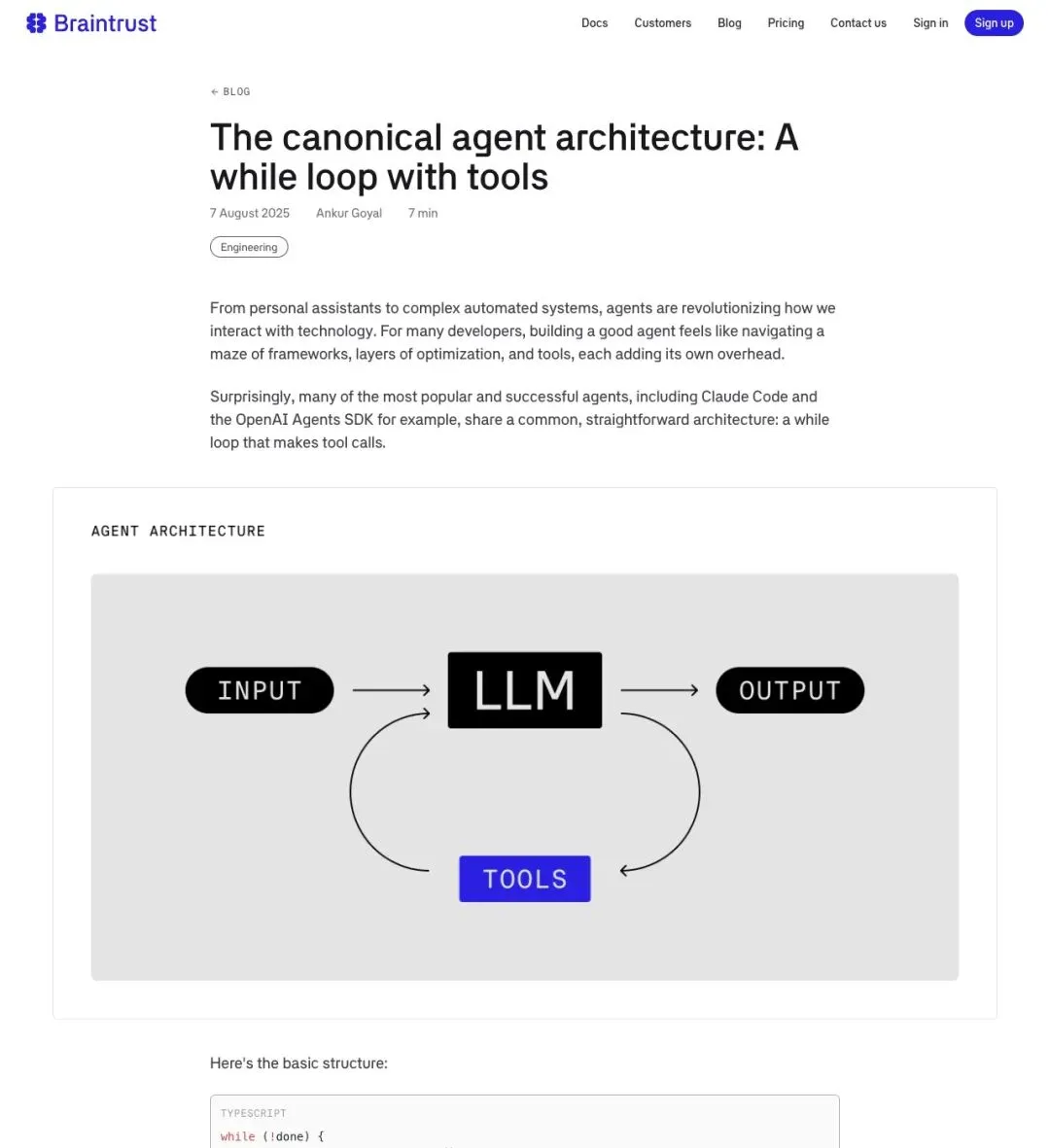
▲ Braintrust 的架构图:INPUT → LLM → TOOLS → 循环 → OUTPUT,就这么直白
Braintrust 还直接贴了 TypeScript 代码骨架:
while (!done) { const response = await callLLM(); messages.push(response); if (response.toolCalls) { messages.push(...(await executeTools(response.toolCalls))); } } 跟 OpenAI 指南里的逻辑一模一样。
这意味着,你用的 Claude Code、ChatGPT 的 agent 模式、各种自动化 coding assistant——它们的核心架构全都是这个 while 循环。没有什么魔法,没有什么神经网络之上的神经网络。就是一个循环,一直跑,直到任务完成或者明确停止。
开发者社区的真实反应
Hacker News:务实到残酷
这份指南在 Hacker News 上获得了 253 分、35 条深度评论。

▲ HN 讨论帖,开发者们用真实案例拆解 agent 的价值和边界
评论区的画风相当现实主义。
一位用户直接开炮:"For every example-agent they gave, an ordinary 'dumb' service would've sufficed."(「他们举的每个 agent 例子,用一个普通的'笨'服务就够了。」)
但也有人分享了真正管用的案例——一家 App 托管平台用 agent 来审查恶意应用。agent 读取每个新应用的首页、截图,LLM 判断是否可疑,然后交给人类做最终决定。这种"模糊 + 多模态"的场景,传统规则引擎搞不定,LLM 循环却能胜任。
讨论最终收敛到一个共识:框架只是 while loop + parser,真正难的是工具怎么设计、退出条件怎么定、护栏怎么搭。
中文社区:翻译和解读铺天盖地
指南在中文互联网上的扩散速度也快得惊人。

▲ Lewlh 的中文全文翻译,阅读量 3781,完整还原了指南的结构和核心概念
知乎上"OpenAI 34 页最佳构建 Agent 实践"的专栏文章被收入多个 AIGC 专栏,评论区大量留言说"终于有人把 agent 讲成工程了"。CSDN 上的解读文章阅读量迅速破万。
翻译者们不约而同地把同一个判断加粗高亮:"这种 while 循环的概念是智能体运行的核心。"
真正的工程挑战:循环容易,刹车难
知道 agent 是 while 循环之后,你可能会觉得"这也太简单了"。
是的,写一个 while 循环很简单。写一个不会失控的 while 循环,才是整个 agent 工程的核心难题。
退出条件是产品决策
"until it is done"——这是最危险的退出条件。谁来定义 done?模型自己说"我做完了"算不算?
OpenAI 指南给出的答案很明确:你需要可验证的停止信号。最终输出工具触发、外部测试通过、构建成功、人工确认——这些才是靠谱的退出条件。
没有明确退出条件的 agent,会自己跟自己聊天、自己给自己找活干,直到钱烧光。
$47,000 的教训
@shmidtqq 在他更早的一篇长文中提过一个真实案例:有人的 agent 循环在没人看管的情况下跑了11 天,累计烧掉了47,000 美元。
他的原话是"Brakes go on before the engine"(刹车要装在引擎之前)。
好的刹车包括:步数上限、预算天花板、心跳检测、强制人工审核节点。你在造引擎之前,先得确认刹车能踩得住。
Guardrails:多层洋葱式防护
OpenAI 在指南里把 guardrails(护栏)做成了一个分层体系:
- 输入层
:相关性分类器、安全分类器(防 jailbreak)、PII 过滤 - 工具层
:按风险等级给工具评级——低风险(读数据)、中风险(写数据)、高风险(发邮件、退款、删除) - 执行层
:乐观执行 + 并行检查,一旦违规立刻抛异常 - 人工层
:超过失败阈值、涉及高风险操作时,交还人类
每一层都像洋葱皮,单独一层不够用,叠在一起才能把风险裹住。
工具设计比换模型更有效
Braintrust 的博文里提到一个关键数据:在典型的 agent 运行中,工具返回的内容占了 token 的 67% 以上。
这意味着什么?你的 agent 大部分时间都在消化工具给它的信息。更聪明的做法是把精力花在工具输出的精心设计上——去掉冗余字段、只返回 agent 需要的信息、用清晰的结构化格式。把一个复杂的 REST API 包装成 agent 能直接理解的窄接口,效果远好于砸钱升级到下一代模型。
范式已经变了
OpenAI 这份指南最犀利的地方在于——它把 agent 从"需要特殊框架和高级技巧的神秘系统"拉回到了"任何工程师都能理解的基础架构"。
同一个模型,调用一次,是聊天机器人。
同一个模型,放进 while 循环,配上工具和退出条件,就成了 agent。
关键从来都在循环本身的精密程度:退出条件够不够清晰、工具接口够不够干净、护栏够不够结实、人工干预的触发点够不够准确。
正如 @shmidtqq 在帖子里写的:
"34 pages from real OpenAI deployments. It moved my work from tuning prompts to designing the loop."
「34 页来自 OpenAI 真实部署的经验。它让我的工作从调整提示词转向了设计循环。」
从"调 prompt"到"设计 loop"——这大概是过去一年里 AI 工程领域最安静、也最深刻的一次转向。