高频退审的“算法研究报告”,如何借助AI工具实现合规“逆袭”?
2026-06-27 10:35
高频退审的“算法研究报告”,如何借助AI工具实现合规“逆袭”?
来来来~走过路过不要错过,唠唠~AI工具如何实现合规“逆袭“
最近一年,医疗器械 RA、QA 和研发团队对 AI 工具的兴趣明显变高了。这不奇怪。软件类医疗器械、人工智能医疗器械、联网设备的注册资料越来越细,审评关注点也越来越具体。过去靠几份模板、几段通用描述就能糊过去的地方,现在很容易暴露问题。尤其是 SaMD 和人工智能医疗器械,资料难点通常不在“会不会写”,而在“证据链能不能闭上”。算法研究报告、软件研究资料、网络安全研究资料、需求追溯矩阵,这些文件看起来分散,实际上都指向同一个问题:产品声称的功能、实际的软件实现、风险控制、测试验证和注册资料之间,能不能互相对上。它不是替 RA 做最终判断的工具,更不是替企业承担注册资料真实性责任的工具。它更适合做三类工作:整理材料、生成初稿、检查一致性。一、需求阶段:先把“研发语言”翻译成“注册语言”
研发团队习惯说功能:“支持用户登录”“支持图像上传”“支持结果导出”。RA 和 QA 更关心的是:这个功能对应哪条用户需求?涉及哪些风险?有没有验证?变更后追溯关系是否更新?AI 可以从需求阶段就介入。比如把脱密后的 URD、SRS、风险分析和测试用例输入给 AI,让它先做一版一致性检查:有没有功能描述在说明书、SRS、测试报告里写法不一致。这一步不追求 AI 一次性给出最终答案。它的作用是先把问题暴露出来,让 RA、QA 和研发知道该往哪里补证据。二、算法研究报告:不要让 AI “自由发挥”
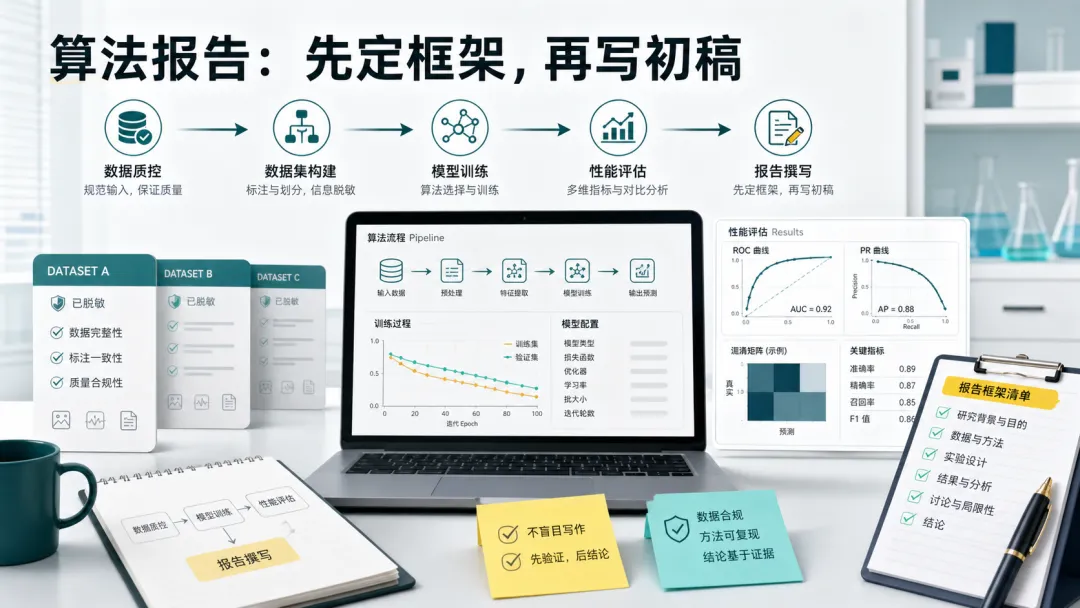
人工智能医疗器械的算法研究资料,不能只写模型名称和性能结果。根据器审中心相关指导原则,算法研究通常需要围绕算法基本信息、风险管理、需求规范、数据质控、算法训练、算法验证与确认、可追溯性分析等内容展开。真正难写的地方,是这些内容必须和产品预期用途、数据来源、验证方案、风险控制对应起来。所以,用 AI 写算法研究报告时,最忌讳一句话开工:先给 AI 产品边界:预期用途、适用人群、使用场景、软件安全性级别、算法版本。再给数据边界:数据来源、纳排标准、标注规则、质控流程、训练/调优/测试集划分。最后给验证边界:评价指标、样本分布、亚组分析、失败案例、风险控制措施。然后让 AI 只起草某一小节,例如“数据质控”或“算法验证与确认”,并明确要求:不使用“先进”“显著”“优异”等没有证据支撑的词;三、网络安全资料:不要只写“已加密”
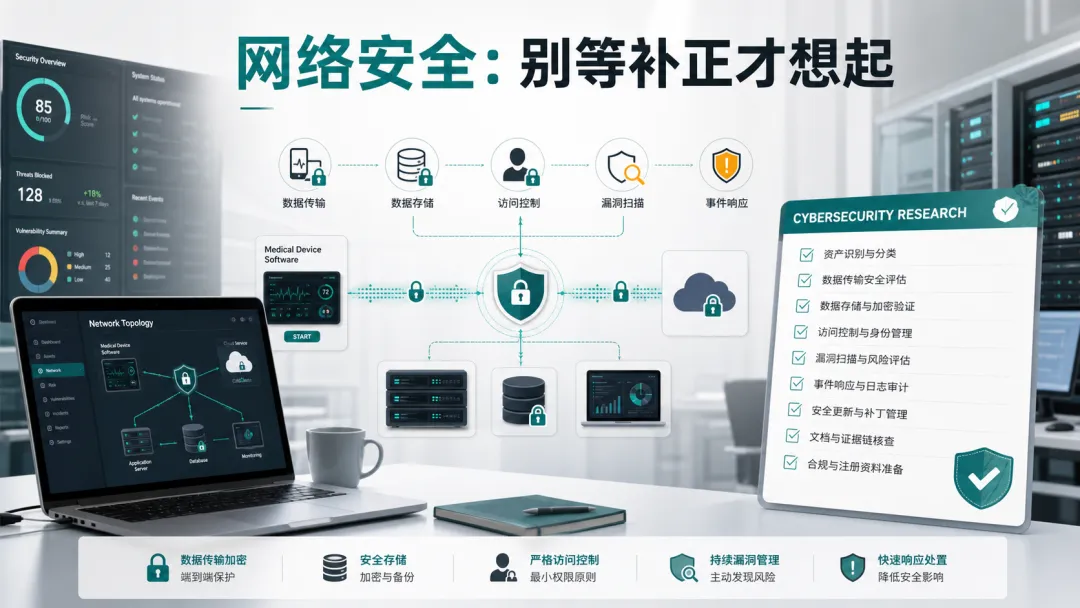
软件类和联网类医疗器械的网络安全资料,已经不适合用几句模板带过。如果产品涉及电子数据交换、用户访问、远程维护、数据传输或存储,就要具体说明用户身份鉴别、访问权限、数据接口、传输和存储安全、漏洞评估、更新维护、应急响应等内容。例如,把产品的软件架构说明、接口说明、用户角色权限、数据流向输入给 AI,让它输出:但有一点要说清楚:AI 不能替代漏洞扫描、渗透测试、验证确认,也不能替代企业对安全措施有效性的判断。它只能帮你把“该问的问题”列出来。四、追溯矩阵:AI 最适合做第一轮整理
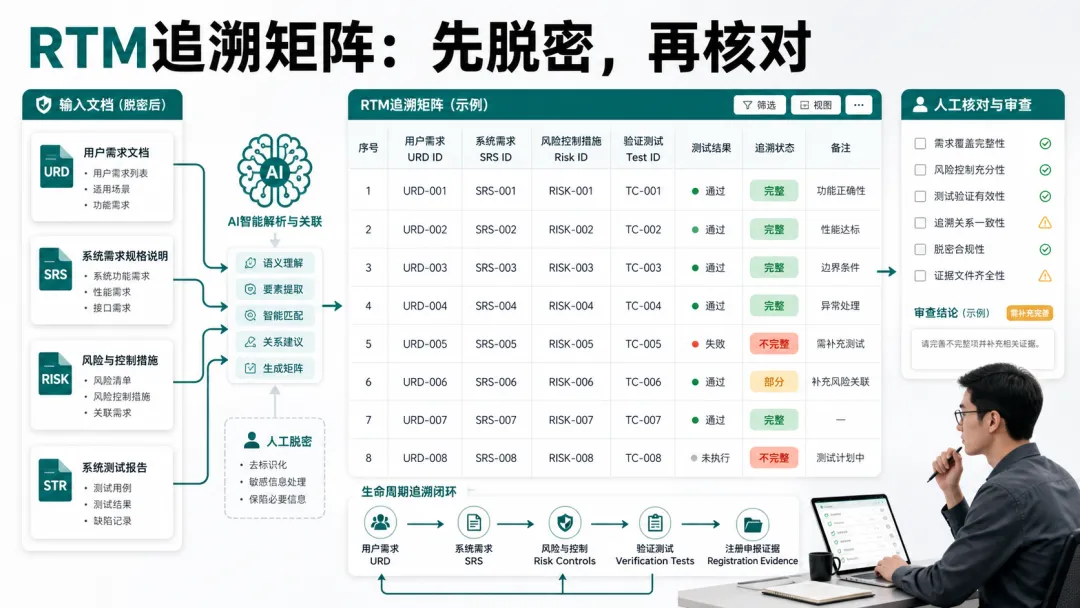
它看起来只是表格,但真正承载的是需求、设计、风险、测试、验证和变更之间的关系。表格填满不代表追溯完成。关键是每一条需求能不能找到对应的实现、测试和风险控制证据。但最终必须人工复核。尤其是需求编号、测试用例编号、版本记录、报告页码、验证结论,这些都不能只相信 AI 输出。比较实用的做法是,让 AI 在矩阵最后加一列“待确认问题”。比如:五、RA、QA、研发怎么协同用 AI
RA 用它做法规要求拆解、资料目录、审评关注点检查;QA 用它做体系文件一致性检查、追溯关系梳理、记录缺口识别;研发用它把技术实现、测试方案和版本变更转成 RA 能读懂的说明。这样 AI 解决的不是“谁来写字”的问题,而是“信息在三类语言之间怎么流动”的问题。法规语言、质量语言、工程语言,本来就不一样。很多返工不是因为团队不努力,而是因为大家说的不是同一种话。医疗器械注册资料的底层逻辑没有变。真实、完整、可追溯,仍然是最重要的要求。AI 能提高效率,但它提高的是整理速度、初稿速度和一致性检查速度。它不能替代研发记录,不能替代验证确认,也不能替代 RA 对法规适用性的判断。真正适合长期使用的方法,是把 AI 嵌入全生命周期管理:这样用,AI 才不是一个会写漂亮话的工具,而是团队少返工、少漏项、少临时救火的助手。