财报翻译中数字错误的现实风险
常见错误类型
财报翻译中的数字错误集中于以下几个高发区:
(1) 分隔符混淆。欧洲国家多用句号作为千位分隔符、逗号作为小数点,与中文习惯恰好相反。例如,1.500在欧洲表示1500,而在中文语境中易被误读为“一点五”,差了一千倍。在涉及多国数据的跨国财报中,这种混淆极易被忽视。
(2) 单位和数量级错位。美丽田园2025年8月发布业绩预告,因“无意的文书错误”,净利润从“亿元”错成“千万元”——本质是小数点错位:175百万元被错写成17.5百万元,170百万元写成了17百万元。
(3) 货币符号歧义。“$”在不同语境下可能是美元、澳元或港币,真金白银的数字翻译必须结合报告来源和上下文硬核实。同样,百分号与千分号的混淆也不容忽视——在医疗健康类财报的统计数据中,千分号一旦误译为百分号,发病率直接差十倍。
(4) 日期格式差异。“04/05/2024”,美国人看到4月5日,英国人看到5月4日。财报中涉及报告期、资产负债表日等关键时间节点,格式错位将直接导致财务分析的可靠性归零。
(5) 术语误导。财报数字的背后是严谨的会计概念体系。以绿茶集团为例,其向港交所递交的招股书中文版将“流动负债总额”错误地对应成了“流动资产总额”,公司在回应中承认系“翻译错误”。这类错误不同于单纯的数字输入问题,它混淆的是会计分类本身,附注与主表之间的数据将由此产生不可调和的矛盾。
这些案例揭示了一个共性:财报翻译中数字出错并非“技术性”失误,而是与分隔符规则、单位换算、术语概念等语境信息高度耦合的系统性风险。仅靠译员逐字逐句核对,效率低且盲区难以覆盖。
在传统的翻译质控流程中,针对数字的专项检查往往依赖于三个环节:译员自查、交叉互审和最终审核。但这一模式面临固有局限:
校对往往是译者完成初稿后的“自我审视”或同事间的“交叉互检”,容易受到疲劳和思维定势的影响。当译员阅读流畅的译文时,很容易产生“顺畅即正确”的心理暗示,从而对数字的微小偏差产生视觉盲区。
一份100页的专业合同,原文100页、译文100页,相当于精读200页专业文献,仅人工比对阅读估算就需要近100个小时。若再加上处理图表、注释错位等问题,审核工作几乎等同于重译一遍。
这些瓶颈叠加起来,使得财报翻译中数字错误的排查难度呈几何级增长。依赖单纯的人工审校,本质上是一种“以人力对抗概率”的防守策略,仍需有系统化工具的辅助才能实现更稳健的保障。
因此,引入一款能够独立于原文和译文进行专项数字校验的智能工具,成为打破瓶颈的必然选择。
功能定位与价值差异化
纠错猫是旗渡自主研发的“译问工具链”中的核心质检组件,其设计哲学可概括为“只纠错,不润色”。这一差异化定位背后的逻辑在于:大模型的计算资源有限,如果同时承担翻译、润色、纠错等多重任务,注意力必然被分散。纠错猫将所有算力聚焦于“找茬”——严格比对原文与译文的每一个数字、每一个术语、每一个逻辑连接词,通过段段对齐技术和术语表约束,精准捕捉数字偏差和术语不一致。
在财报翻译实践中的具体应用
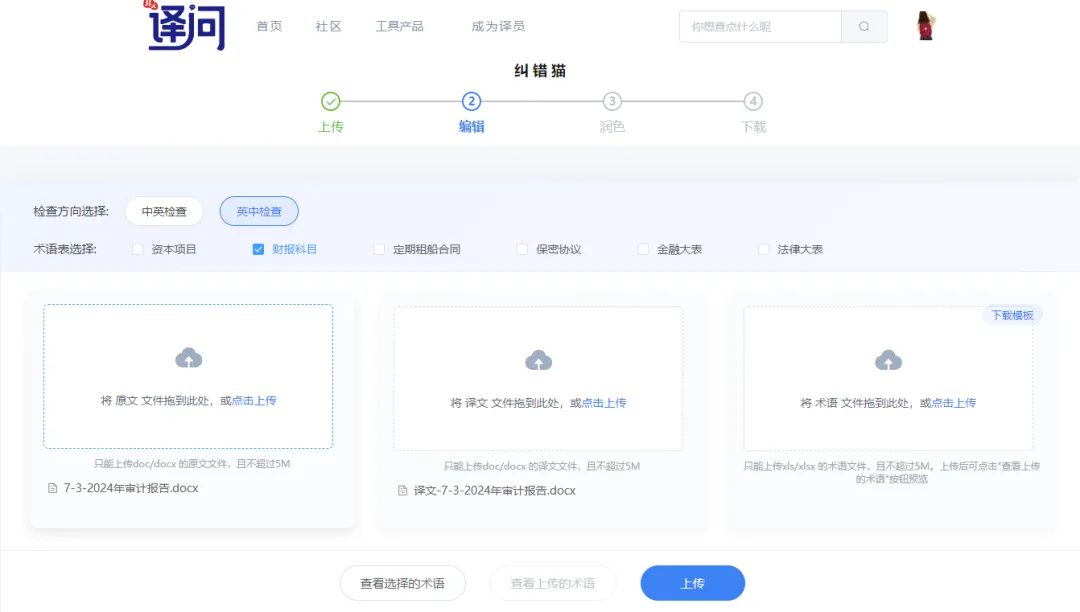
结合财报翻译的实操场景,纠错猫可以在以下情形中发挥关键作用:
(1) 跨国财务报告中的分隔符错误检测。针对不同地区财报的数字格式差异,纠错猫自动识别并标注出可能与分隔符规则不符的数字引用,避免因国家/地区习惯差异导致的量化错误。
(2) 财报附注与主表数据的交叉验证。在审阅大量财务附注、附表时,纠错猫可依据交叉对应关系,自动检测主表与附注中前后不一致的明细数字,高效识别关联性差错。
(3) 单位与数量级偏差筛查。面对不同币种、不同单位的财务数据,纠错猫可依据项目预设的术语表与财务规范设定,发现单位错位、数量级悬殊等情况,及时给出疑似错误提示。
(4) 关键财务指标的一致性检查。连续多年的财报对比,在翻译不同年份的财务数据时,纠错猫可依据翻译记忆库,检索到历年惯用表述,并发现任何可能的数据引用矛盾,保证各年度财务数据对比的可靠性。
“工具+人工”协同保障的实践价值
纠错猫并非试图取代人工审校,而是提供一种“清除海量泛型错误 + 最终人工重点裁决”的双重防线。财报翻译的实际交付场景通常涉及多轮审核:
第一层,由纠错猫基于规则和算法定位原文中的数值单位差异、分隔符异常等浅层问题,快速过滤掉约90%的常见低级错误;第二层,再搭配人工审校专攻疑难逻辑和核心财务科目,确保真正需要人为判断的高风险内容得到精准把控。通过“第一重AI深度初校 + 第二重AI交叉精校 + 第三重术语统一管控 + 第四重专家人工核验”的流程,财务报表译文整体错误率可降至0.1%,主要内容准确率可达99.9%。
纠错猫的出现不仅是一个更高效的“数字核对工具”,更代表了一种从“依赖个人”到“构建系统”的质控逻辑转变。在过去,高质量的翻译成果往往依赖于某位“经验老道、状态神勇的资深译者”——即所谓的“超级个体”。但人的状态存在波动,大师的经验难以规模化复制,一旦出现片刻疏忽,整个交付物就可能面临崩盘的风险。
纠错猫的实践标志着质控逻辑的深刻转变:它将一个独立的、不知疲倦的质检组件嵌入到工作流的每一个关键节点,使质量不再依赖于个人的临场状态,而是内嵌于一个经过冗余设计、拥有多重反馈回路的稳健系统架构中。对于财报翻译这种容错率趋近于零的领域,这种从“人治”走向“系统制”的范式转变,具有里程碑式的意义。
财报翻译中的数字,看似无需“翻译”,却因分隔符、单位、术语语境等复杂因素而隐含诸多风险。一个漏掉的“0”、一个混淆的分隔符、一个误配的会计科目,都可能引发从市场信任危机到监管合规问题的严重后果。纠错猫的推出,正是为这一薄弱环节构筑了一道有针对性的专业防线——让AI负责不知疲倦的海量筛查,让人类专注于最终的价值判断与责任承担。
在实际的财报翻译与审核流程中,将纠错猫作为“第一道AI校验防线”,再结合人工重点审核,既能消除翻译过程中的大部分低级隐患,又能将专业译员从低效重复性劳动中解放出来,在最大程度上保障译文最终的交付质量。对于任何一家将财报翻译准确性视为生命线的翻译服务团队来说,将纠错猫纳入常态化质检流程,绝非锦上添花,而是提升系统性翻译安全保障的必要组成。
END
