

Q1:WAM 和普通 VLA、世界模型最核心区别是什么?
A:VLA 仅建立观测到动作映射,无未来预测;普通世界模型只预测环境变化,不参与动作选择;WAM 必须将预测得到的未来表征用于动作生成、打分或优化,实现预测与控制耦合。
Q2:综述提出的三种 WAM 设计哲学,核心差异在哪?
A:差异在于动作解码前是否生成完整像素未来。1. 渲染解码:完整输出 RGB 像素;2. 仅隐态:保留视频主干、跳过像素解码;3. 无视频生成:完全移除视频生成网络,基于特征 / 几何等表征预测。
Q3:WAM 领域整体发展趋势是什么?背后的核心权衡?
A:趋势是 “Dream Less, Act More”,逐步放弃完整像素渲染,使用隐式、几何轻量化预测表征。核心权衡:越完整精细的未来预测,视觉信息越丰富,但算力、内存、推理延迟开销越大,轻量化方案牺牲部分视觉细节换取实时控制能力。
附录:World Action Models: A Survey
本文是新加坡国立大学团队发布的世界动作模型(WAM)领域综述,系统梳理 WAM 定义、两大分类视角、四维组件解剖、五大核心属性、数据与评测体系、现存开放挑战,统一了视频生成、VLA、世界模型、WAM 之间模糊的学术边界,是该领域系统性梳理文献。
一、研究背景与核心动机
- 具身 AI 长期目标
构建能在非结构化物理环境感知、推理、执行智能体。 两代主流路线局限 - VLA(视觉语言动作模型,RT-2、OpenVLA 等)
仅建立「观测→动作」映射,无法建模动作对环境带来的变化,缺少物理、接触、视角变化推理,只能被动响应,无法预判行为后果。 - 传统世界模型 / 视频生成模型
仅预测未来画面 / 隐状态,不将预测结果用于动作生成、打分、规划,缺少面向控制的耦合链路。 - WAM 诞生
将世界模型的未来预测嵌入动作决策链路,让预测结果参与动作生成、筛选、校验,弥补 VLA 与纯世界模型的缺陷。 领域乱象:视频、机器人、大语言社区各自提出同名 WAM 但实现完全不同,综述建立统一术语、分类框架,提出4 元组标准化描述任意 WAM,并提炼领域统一发展趋势:少生成、多决策(Dream Less, Act More)—— 无需完整渲染全部未来,仅保留控制必需预测信息。
二、概念界定:四类模型边界区分

1. VLA 模型
建模:\(p(a|o,l)\),输入观测o、语言指令l直接输出动作,无显式未来预测环节,无环境动态建模。
2. 基础世界模型
建模:\(p(o'|o,a,l)\),仅预测动作后的未来观测\(o'\),不参与动作选择,仅用于仿真、数据生成,不服务控制决策。
3. 视频生成模型
条件生成未来画面,属于世界模型子集,但不绑定动作输入与动作输出。
4. 世界动作模型 WAM(严格定义)
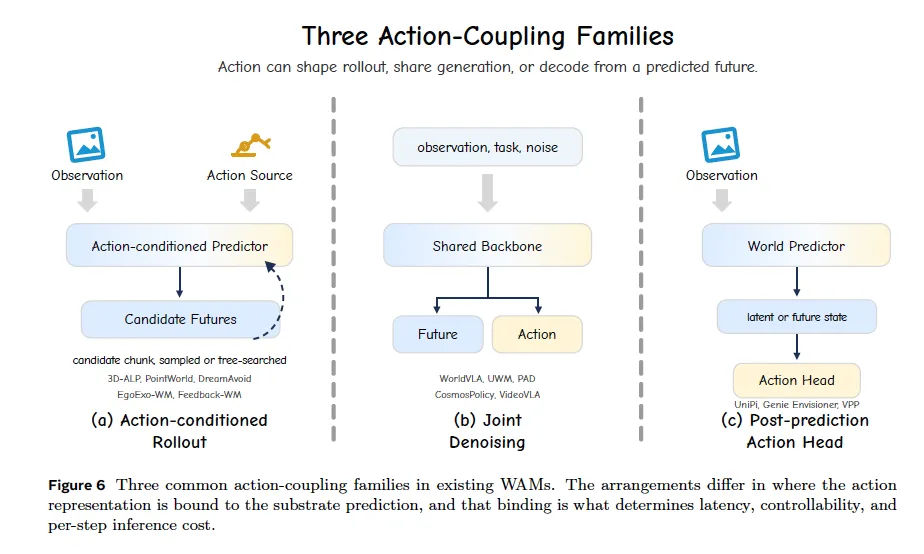
必须满足:预测的未来表征参与动作生成 / 打分 / 训练,数学形式为联合分布\(p(s_{t+1:H},a_{t:H-1}|c)\)(c为历史观测、动作、指令上下文)。三种耦合范式(区分 WAM 与普通世界模型的核心):
- 先预测再解码动作(后预测头)
先生成未来表征,再独立模块从中提取动作(UniPi 等早期视频规划类); - 动作条件推演
先给出候选动作,用世界模型预测后果并筛选最优(MPPI、MCTS 规划类 WAM); - 联合生成
单一主干同步预测未来表征与动作(GR 系列、PAD 扩散联合模型)。
三、第一层分类:三大设计哲学(按推理链路中未来表征形式划分)
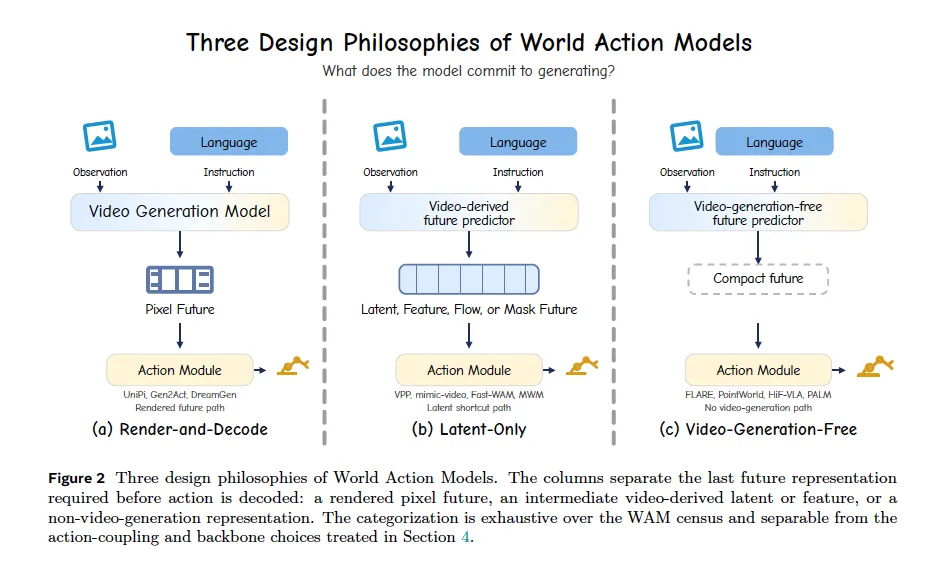
从「动作解码前需要生成何种未来」维度,将所有 WAM 划分为互斥三类,是顶层宏观分类:
1. Render-and-Decode 渲染解码型
链路:完整运行视频生成主干至像素级 RGB/RGB-D 画面,再从渲染画面提取动作; 代表:UniPi、VLP、GR-1/2、DreamGen; 优势:画面直观,复用大规模视频视觉先验; 缺陷:推理时延、显存开销极大,大量像素信息对控制无作用,视频画质指标和机器人任务成功率弱相关; 细分:离线开环生成完整视频规划、块式闭环逐段渲染。
2. Latent-Only 仅隐式型
核心创新:保留视频预训练主干,但推理时跳过像素解码器,直接从中间扩散隐变量、光流、语义掩码等中间表征解码动作; 代表:VPP、mimic-video、Fast-WAM; 优势:大幅降低计算与延迟,保留视频学到的时空物理先验; 缺陷:无可视化画面,难以人工调试;
3. Video-Generation-Free 无视频生成型
核心:彻底移除视频扩散 / 自回归生成主干,预测空间为 VLM token、DINO 等视觉特征、3D 点云、仿射图、音频隐空间; 代表:FLARE、DUST、PointWorld、PALM; 优势:开销最低,完全规避视频渲染成本,适配实时控制; 缺陷:缺少大规模视频的视觉动态先验,几何 / 语义表征设计难度更高。 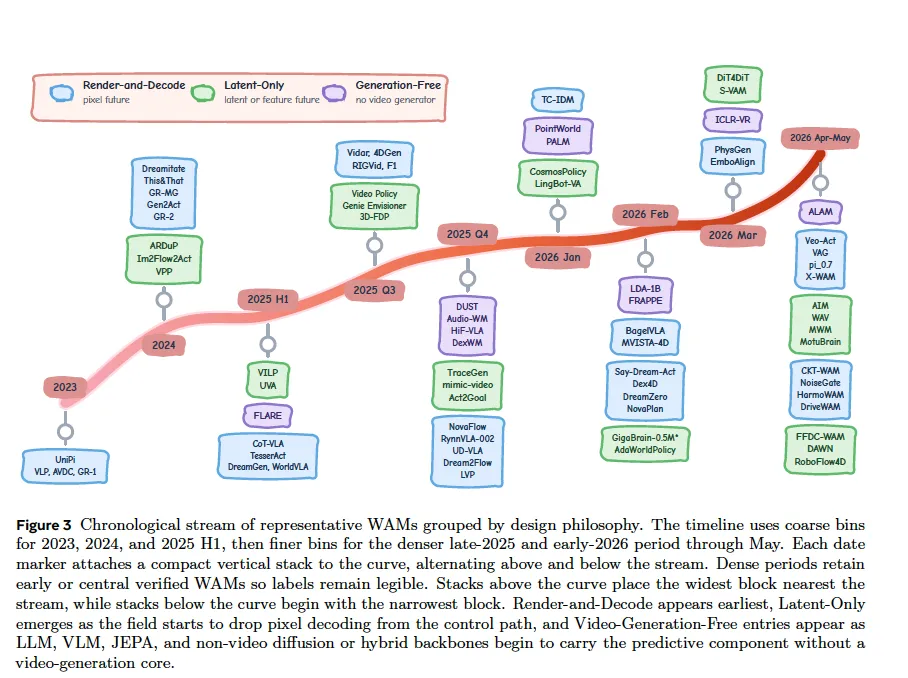
时序演进规律
早期全是 Render-and-Decode;2024 年后 Latent-Only 兴起;2025 起无视频生成分支快速发展,整体趋势是逐步舍弃像素渲染,轻量化预测表征。
四、第二层分类:四维组件解剖(标准化 4 元组 WAM=(Φ,F,B,D))
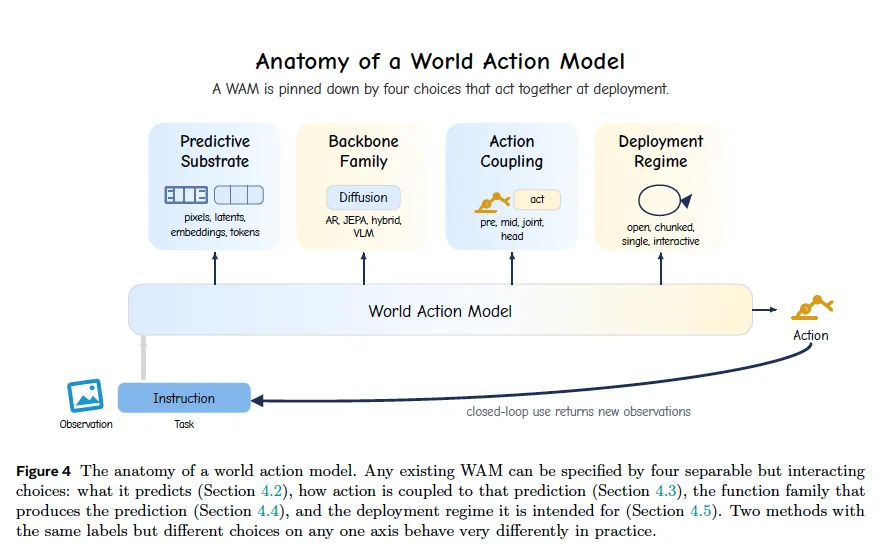
综述提出精细化组件拆解框架,四个正交维度可完整刻画任意 WAM,实现跨论文统一对比:
维度 1:Predictive Substrate 预测基底 Φ(预测未来的表征空间)
四类基底,可多模态联合预测(用∧标记):
- 像素基底
解码 RGB/RGB-D 或 VQ/VAE 可解码视频隐变量; - 特征基底
无固定图像解码器,含 JEPA 特征、VLM 文本 / 视觉 token、中间扩散隐态; - 几何基底
光流、3D 点轨迹、关节位姿、关键点、运动矢量; affordance(任务图基底):价值热力图、接触掩码、目标可达区域、任务得分图。
维度 2:Action Coupling 动作耦合方式 F(未来与动作如何联合建模)
- 动作条件推演
先采样 / 规划候选动作,预测后果打分选最优;适合 MPPI、树搜索; - 联合生成
单主干同步输出未来表征 + 动作,共享损失训练;易出现双任务训练冲突; - 后预测动作头
世界主干固定,额外轻量模块从预测结果输出动作;易模块化、适配不同机器人。
维度 3:Architectural Backbone 主干架构 B(预测模块网络家族)
5 大类主流主干:
视频扩散(迭代去噪,Wan、CogVideoX、Cosmos); 自回归主干(逐帧 / 逐 token 预测,GR、WorldVLA、NOVA); JEPA 联合嵌入预测(确定性特征预测,无生成噪声,速度快); 混合主干(共享编码器,分支分别做预测、动作头); LLM/VLM 视觉语言主干(无视频生成,仅文本图像 token 预测)。
维度 4:Deployment Regime 部署模式 D(控制循环调用策略)
- 开环推演
任务开始一次性生成完整长时未来,全程不重新观测;低实时性; - 块式闭环
每 K 步重新预测一段动作块,平衡算力与环境反馈;工业机器人主流; - 单步闭环
每一次控制都重新预测一帧未来,响应最快、算力开销最大; - 交互式仿真
:无限长持续生成,通过 KV 缓存复用历史,用于持续交互模拟。 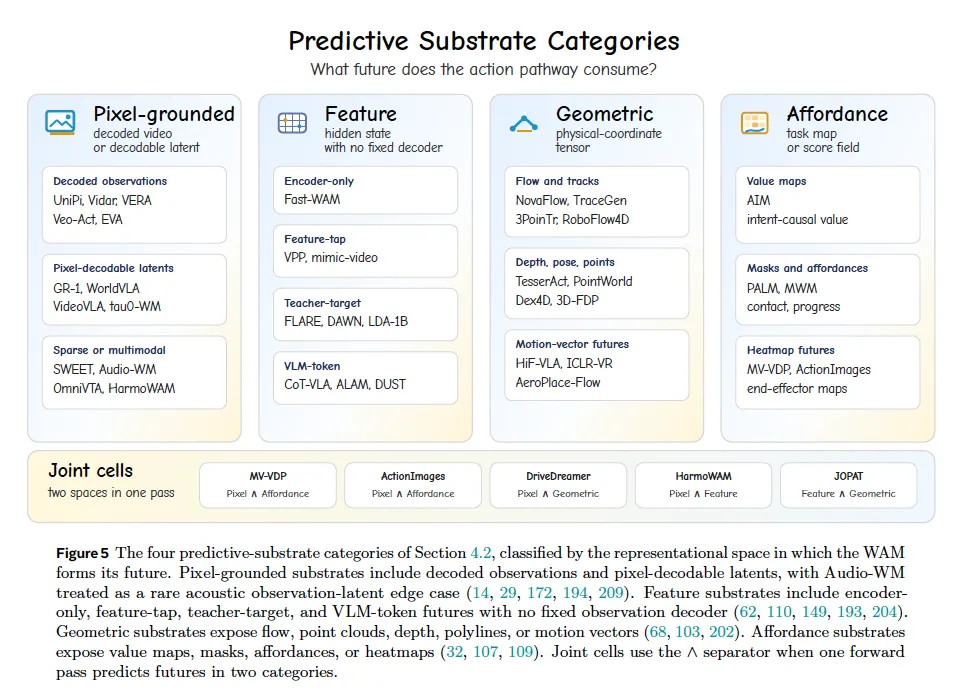
五、WAM 五大核心必备属性(具身控制约束)
一个合格 WAM 不能仅视觉逼真,必须满足机器人实操五大特性,各特性存在天然权衡:
- 可交互性(Interactability)
动作输入可中途修正预测,而非只能生成前一次性给定;后解码型交互最弱,联合生成、条件推演交互性更强。 - 因果性(Causality)
禁止未来帧信息泄露给当前动作;扩散全局建模易时序泄露,自回归因果掩码、分步去噪解决该问题,同时降低推理延迟。 - 持续性(Persistence)
长时预测不漂移、不遗忘物体;核心方案:新观测实时替换缓存想象帧、稀疏时序存储、滑动上下文窗口。 - 物理合理性(Physical Plausibility)
预测动态必须机器人可执行,不只视觉好看;需融合几何、触觉、关节限位、接触力约束,舍弃纯像素冗余信息。 - 泛化性(Generalization)
跨物体、场景、相机、机械臂、指令通用;核心方案:用光流 / 特征等不变表征替代像素,复用互联网视频先验。
六、训练数据与评测体系
1. 五大训练数据源
机器人遥操作:动作标签精准,但采集成本极高; 便携人体演示(头戴 / 手机拍摄):量大,但存在人 - 机器人形态域差; 互联网第一视角视频:海量视觉动态,无动作标注; 仿真环境:完美标签,存在仿真 - 现实鸿沟; WAM 自身生成合成轨迹:低成本扩充数据,但会复刻模型自身预测误差。
2. 双层评测标准(单一指标无法衡量 WAM)
- 视觉保真指标(FVD、PSNR 等)
仅衡量画面,和机器人任务成功率弱相关; - 闭环实操评测(仿真 / 真实机器人)
核心标准,衡量任务完成率,但成本极高; 补充评测:物理一致性、长时序连贯性、推理延迟、显存占用等工程指标。
七、开放研究挑战(七大核心待解决方向)
- 预测算力分配:多想象还是多执行?
按需生成预测:常规运动轻量化推演,接触 / 危险关键场景精细渲染;缺少自适应调度机制。 - 多阶段数据分配
互联网视频、人体数据、机器人数据分别适配预训练 / 对齐 / 动作微调,缺少标准化课程式训练方案。 - 长时序内存瓶颈
自回归 KV 缓存持续膨胀,如何兼顾长时记忆与有限硬件内存尚无统一方案。 - 跨域泛化机制
现有迁移依赖视频预训练,缺少通用、轻量化跨机械臂 / 物体的表征方案。 - 抽象动作物理落地
流、隐动作等抽象表征降低数据需求,但缺少力、接触等物理约束绑定。 预测物理真实性标准化缺少统一物理指标衡量预测轨迹是否符合机器人运动、接触规则。 标准化评测协议缺失现有论文只单独报成功率,缺少统一的「成功率 + 延迟 + 内存 + 时序鲁棒性」综合评测规范。
八、全文结论
- 定义统一
WAM 核心本质是「面向控制的耦合世界预测」,区分纯 VLA、纯世界模型、视频生成; - 双层次分析框架
顶层三大设计哲学(生成何种未来)、底层四维组件解剖(如何构建模型),两套框架互补,可统一梳理全部现有算法; - 行业发展主线
领域持续从全像素渲染向隐特征、无视频生成轻量化路线演进,核心思路是只生成控制必需的未来信息,削减冗余视觉细节; - 固有权衡
所有架构设计都存在「预测丰富度 ↔ 计算 / 内存 / 时延」的取舍,不存在全能 WAM; - 未来方向
自适应按需推演、分阶段混合数据训练、物理约束嵌入、统一闭环评测体系是领域核心突破口。