点击蓝字 关注我们



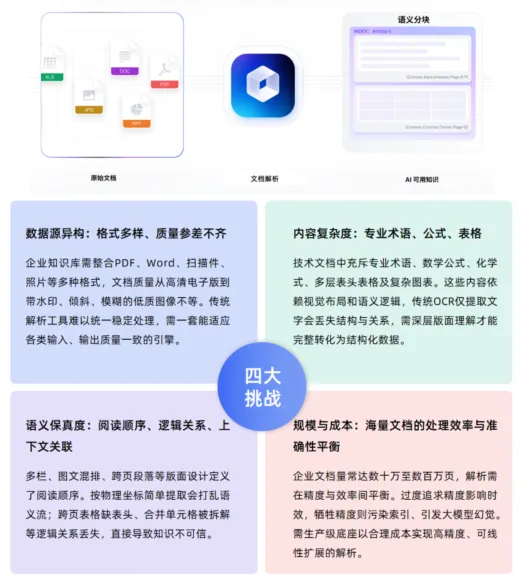
2026年,企业知识库与大模型应用的深度融合正在加速。从RAG检索增强生成系统到AI智能体,企业对“让大模型读懂内部文档”的需求日益迫切。然而,一个普遍被低估的瓶颈是:在文档可以被大模型“理解”之前,必须先被准确解析。
合合信息近期发布的《2026企业知识库建设白皮书》,系统梳理了知识库建设的完整路径与核心痛点。
这份白皮书的核心结论令人警醒:文档解析的质量,决定了知识库所有后续环节的上限——表格识别错误、阅读顺序混乱、跨页内容断裂,会直接污染索引、误导检索、诱发大模型幻觉。
?当大模型“读不懂”你的文档,一切AI投入都是徒劳
1
核心要点
01 知识库的“三种形态”
白皮书重新定义了企业知识库的三种形态:
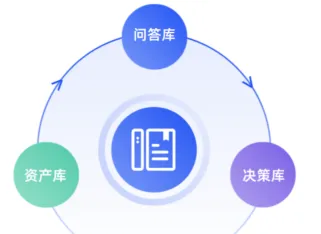
? 资产库——将企业核心知识资产进行系统化归集、存储和检索。本质是“把知识存起来、找得到”。但知识仍是“静态”的——机器能帮你定位文档,却无法代替你阅读和理解。
? 问答库——在资产库基础上叠加大模型能力。用户用自然语言提问,系统从知识库中检索相关内容,由大模型生成精准、可溯源的答案。问答库极大降低了知识获取门槛,但其性能高度依赖于知识库中数据的结构化程度和解析精度。
? 决策库——知识库的高级形态,为战略和业务决策提供数据驱动的支持。不依赖预先定义的报表,而是能基于海量非结构化知识进行关联分析、趋势预测和方案比选。
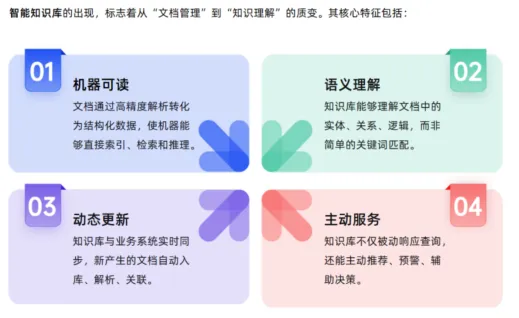
? 绝大多数企业尚处在从资产库向问答库过渡的阶段,而真正的分水岭,在于文档解析能力。
02 大模型为什么“看不懂”你的企业?
通用大模型虽然在互联网规模的公开数据上表现出色,但直接用于企业内部知识问答存在三个根本性缺陷:
? 知识截止日期——训练数据截至某个时间点,之后产生的新文档无法被模型知晓。
? 缺乏私有知识——大模型从未见过企业的内部文档,试图让模型“猜测”必然产生大量幻觉。
? 无法提供溯源——企业决策和合规审计要求答案必须有据可查,大模型直接生成的答案缺乏可信度。
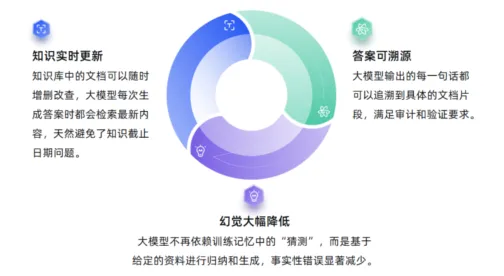
RAG(检索增强生成)正是为解决这些问题而设计。但RAG的成功有一个前提:知识库里的文档必须被准确解析。
? 如果一份年报中的跨页表格被拆解成碎片,如果一份技术手册中的多层表头被识别错误,如果一份工程图纸中的专业符号被当作乱码——那么无论大模型多么强大,检索到的都是错误的信息,生成的答案自然也是错误的。
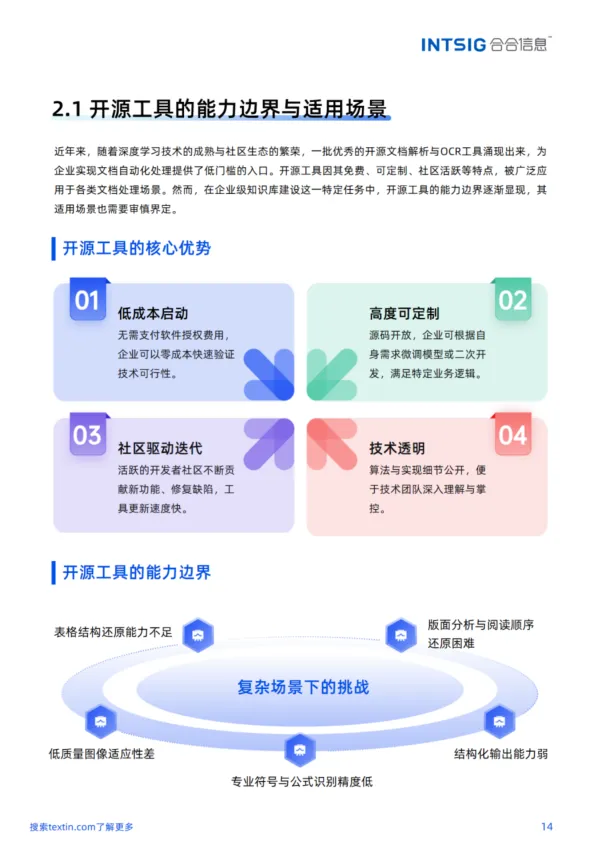
03 文档解析的“12道难关”
白皮书系统梳理了非结构化文档解析的12大痛点。这12个场景,几乎是每一家试图建设知识库的企业都会撞上的“南墙”:
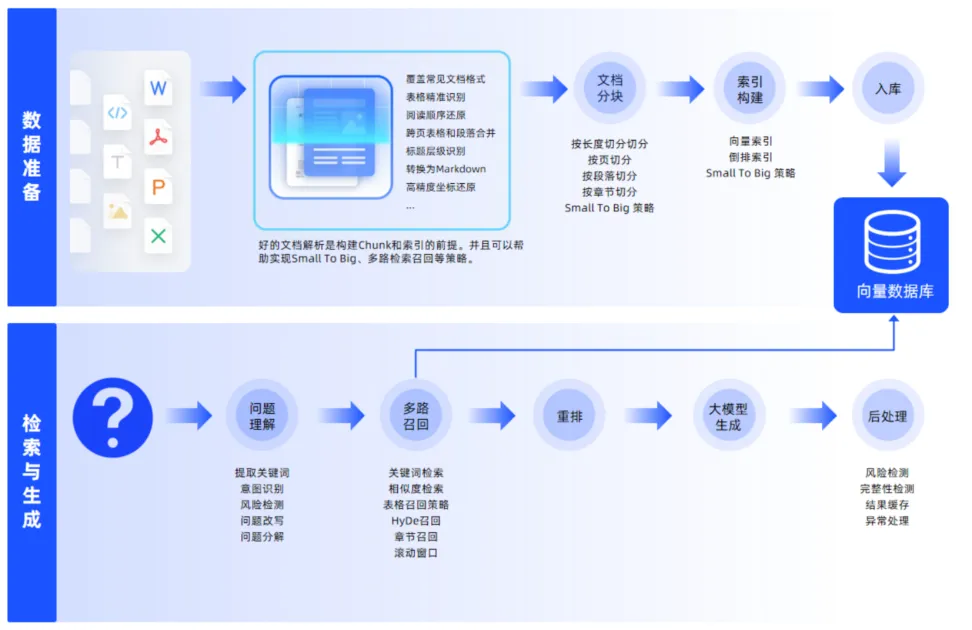
? 复杂表格——多层表头、合并单元格、无线表格,传统OCR往往将合并单元格拆解为多个独立单元格,导致数据归属关系断裂。
? 跨页内容——表格被分页截断后表头丢失,段落被“腰斩”后语义断裂。
? 多栏布局——学术论文的双栏排版,按物理坐标读取会将左栏后半段与右栏前半段混排,完全打乱叙事逻辑。
? 图文混排——图片内嵌注释无法提取,图文分离导致语义断裂。
? 图表——柱状图、折线图被当作普通图片截取保存,图中的原始数据、数值关系全部丢失。
? 特殊符号与公式——数学公式、化学式被拆解为普通字符,语义彻底丢失。
? 手写字体——生产批记录、审批签字无法电子化,难以检索。
? 密集文本——芯片数据手册中5pt至8pt的极小字体,传统OCR极易将邻近笔画粘连。
? 低质量图像——倾斜、透视变形、水印与印章干扰,识别率骤降。
? 工程图纸——标题栏、修订记录、技术要求、专业符号难以自动提取。
? 标题层级——视觉样式与语义层级不匹配,检索颗粒度过粗。
? 多语言混排——多语言同篇共存,单语言模型识别失败。
? 白皮书以“一痛点一方案”形式,逐一呈现如何通过生产级文档解析底座,将这些难题转化为结构化、可溯源、大模型友好的高质量数据。
04 开源工具 vs 生产级底座
白皮书对比了开源工具与生产级文档解析底座的差异。开源工具通常只解决“能开始”,而生产级底座必须解决“能交付、能规模化、能长期运行” 。
两者的核心差异体现在五个维度:
? 全格式输入兼容——用一个统一的API覆盖企业所有混杂的文档格式,而不是为每种文件维护一套独立解析链路。
? 整本文档结构还原——跨页、目录、层级完美保留,而不是靠字数硬切导致检索命中率大幅下降。
? 关键场景效果可靠——在复杂表格、财报、学术文献等高价值信息密度区提供高精度识别。
? 企业级Runtime——稳定、高并发、可观测、多租户隔离、信创适配。
? 对知识库与Agent生态友好——开箱即用的标准化输出,大幅缩减接入胶水代码。

? 白皮书特别指出,复杂表格是企业知识库中信息密度最高的载体之一。当表格结构在解析过程中受损,大模型在处理此类数据时极易产生“幻觉”——输出看似合理、实则错误的信息。这种错误在合规审计、关键数据抽取等场景中难以被人工快速识别,可能引发严重的业务风险。
05 从概念验证到规模化落地
白皮书精选了五个行业的头部企业案例:
? 头部券商——通过文档解析实现研报、年报、基金产品说明书等复杂文档的高效结构化处理。一份200页的含多表格、多公式、图文混排的复杂文档,传统人工处理需3-4小时,而通过解析技术1分钟内即可完成。整体流程处理效率提升70%以上。
? 跨国工程机械集团——将千万级图纸、BOM清单、检测报告等存量文档统一解析接入知识库,实现图纸版本、工艺参数、供应商报价的快速检索与复用。系统重点处理多级表头、合并单元格、跨页表格、无框线表格和密集型表格,尽可能保留表格的行列关系、层级关系和上下文关系。
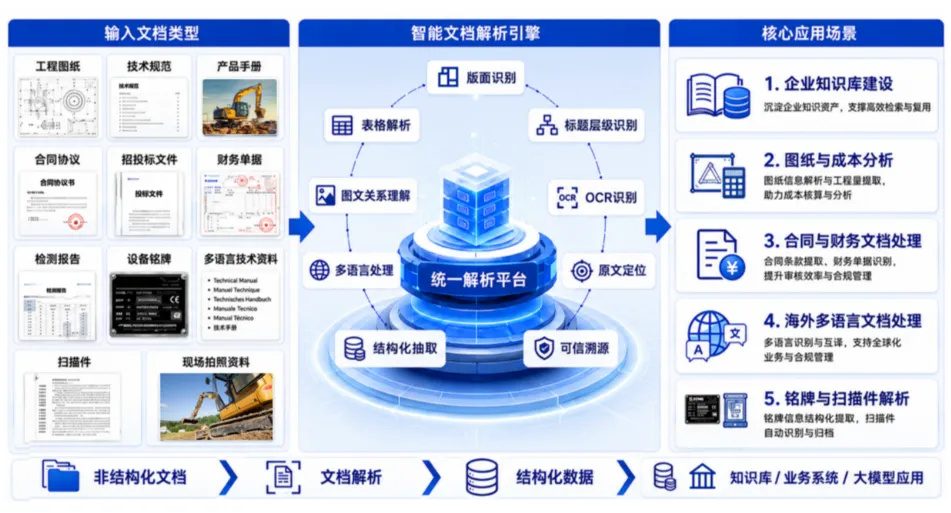
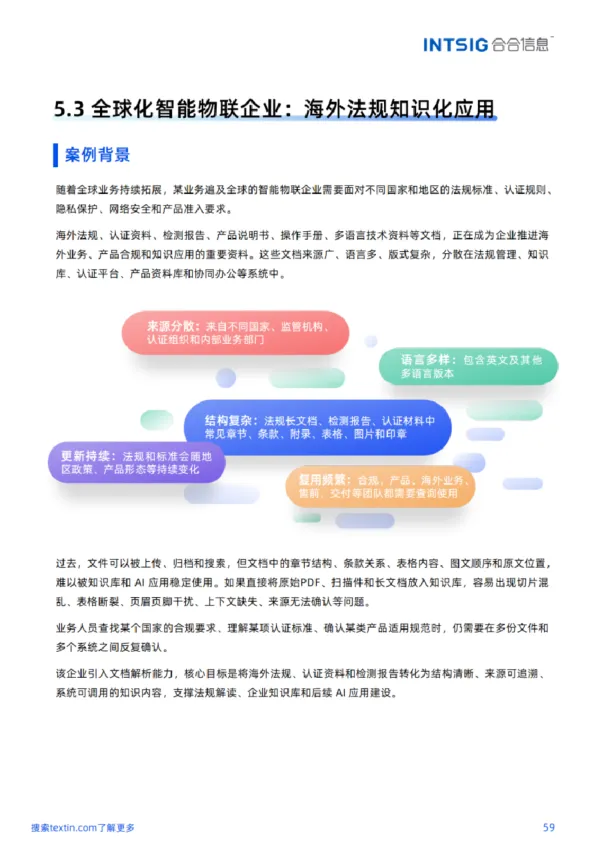
? 全球化智能物联企业——将多语言法规、认证资料、检测报告通过章节结构保留与表格还原,转化为可检索、可问答的知识内容。法规文件可按章节、条款、段落和附录进入知识库,业务人员查询法规要求时可快速定位并回到原文确认。
? 头部半导体企业——高精度解析电路设计手册、学术论文中的密集文本与复杂公式,构建研发知识库,支撑器件参数检索与设计规范查询。

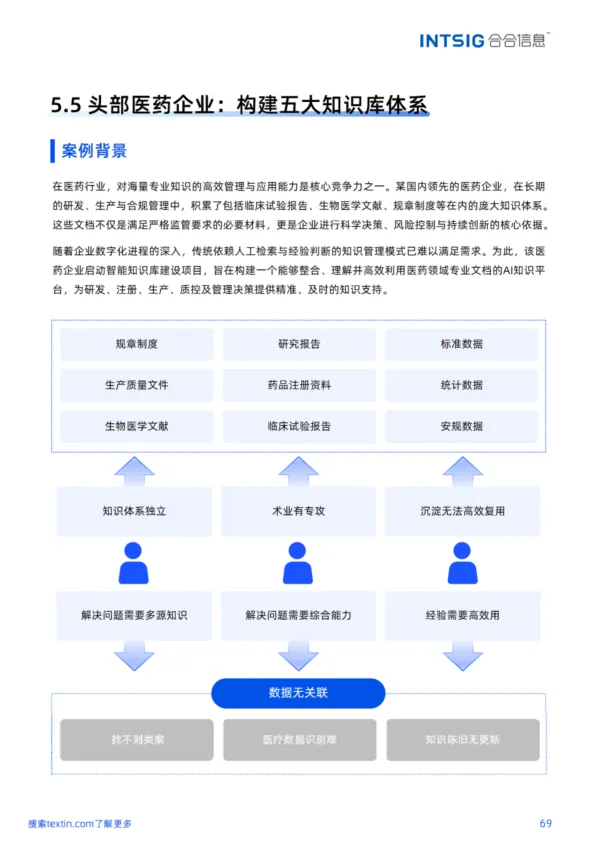
? 头部医药企业——统一解析临床试验报告、化学分子式、手写记录等多源异构文档,精准还原复杂表格与专业符号,支撑研发、生产、质量、供应链、营销五大知识库建设。
总结
这份白皮书传递的核心信息其实只有一句话:文档解析是知识库的“第一粒扣子”,这粒扣子扣错了,后面所有的努力都是徒劳。
在大模型与智能体技术普及的背景下,文档解析能力正在成为企业知识库落地的关键。企业需要结合文档类型、业务场景与安全需求选择技术方案,通过智能化解析盘活存量知识资产,推动知识复用、业务提效与全链路智能化升级。
? 这份73页的报告,回答了一个核心问题:如何把企业累积的文档,从“待激活的数据资产”转化为“可支撑的决策力”。
(只截取部分报告,需要查看全文,见文末链接可免费下载资料)
2
报告原文
















报告来源:INTSIG 合合信息
篇幅有限,需要查看报告完整版可私信“2026企业知识库建设白皮书",小z助手会自动回复链接,也可点击下方链接自行下载,资料均免费获取。
如果本篇文章对您有帮助或有价值,记得点赞分享给更多人,感谢您的支持!

我们组建了AI赋能行业交流群,群内会分享政策、行业动态和合作信息,感兴趣的伙伴可扫码或私信入群~

往期回顾

AI 瞭望星球
站在未来最前沿,
探索智能时代的星辰大海!
联系邮箱丨biz@steoak.com