系列导读上一篇我们聊了 AI 数据"全球漂流"是怎么实现的;这一篇深入到 AI 训练阶段——这是网络压力最极致的环节。一个事实:大模型训练过程中,通信时间占训练总时间的 30% 以上。网络不解决,万张 H 卡也只能"摸鱼"。
一、训练网络的真实瓶颈:东西向流量,从 20% 飙到 80%
传统业务:用户 → 服务器,南北向流量为主,对称、可预测。
大模型训练:GPU ↔ GPU,东西向流量为主——AllReduce、AllGather、参数同步……每一步都依赖海量小包的高频通信。
这意味着:东西向流量占比从 20% 突增到 80%;
通信时间一旦拉长,算力利用率(MFU)直接腰斩;
单条链路抖动,可能让整轮 step 全部回退。
所以 AI 训练对网络的要求很"极端":要么不丢包、要么超高吞吐、要么毫秒级故障收敛。
阿里云这一波升级,正是冲着这三件事去的。
二、一张图看懂"全球训练算力资源池"
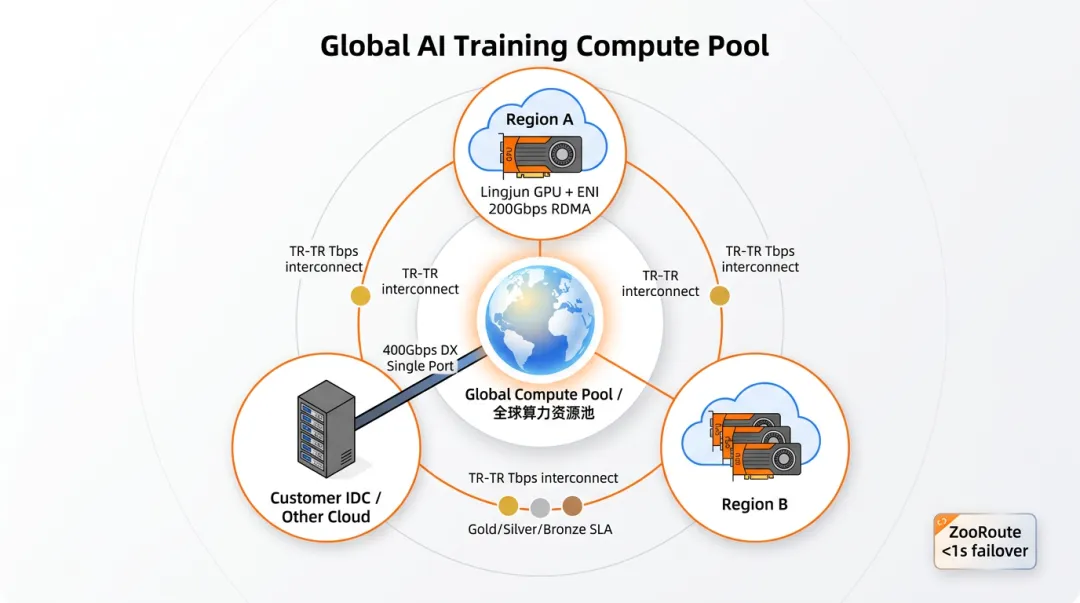
整个方案的核心思路:把分散在不同 VPC、不同 IDC、不同 Region 的 GPU 集群,"拼"成一个统一的算力资源池。
这背后由三层升级支撑:机头网络、混合云专线、跨地域骨干。
三、第一层升级|机头网卡 ENI:200Gbps + RDMA 直通
云上的 AI 集群,机内一般跑高速 RDMA(即所谓"机尾网络"),机间走 VPC(也就是"机头网络")。
过去机头网络只承担管理和外部访问,是个"小水管";现在它要承担集群间算力池构建和推理 PD 分离后的 KVcache 流量卸载——压力陡增。
阿里云灵骏智算服务器的 ENI 网卡这一波直接拉满:
吞吐拉到 200Gbps:靠 Jumboframe + 硬件卸载实现;
VPC 自研拥塞控制算法:适配大规模组网,不靠传统 ECN 也能稳;
按需开启 RDMA 直通:高速存取能力直接在 VPC 上,特别适合推理 PD 分离场景;
支持 TCP/RDMA 比例自定义:同一张卡,不同任务可以拆带宽。
一句话:以前 RDMA 只能在机内玩,现在 VPC 上也能跑。这意味着跨服务器、跨 VPC 的算力池化真正可行了。
四、第二层升级|专线:400Gbps 单端口 + 倒换组毫秒级容灾
很多企业的 AI 训练是"混合云"形态——部分算力在自己 IDC、部分在云上、部分在他云。
这就要靠专线把多方算力拉通,构建跨云算力资源池。
痛点 1:突发大流量丢包
过去用多条小专线 + ECMP 凑带宽,但 hash 不均时,burst 流量会在某条专线上瞬间打爆丢包,算力效率直接崩。
阿里云方案:单端口/单专线 400Gbps,从根上消灭 hash 不均。
痛点 2:多业务混跑互相挤
一条专线既跑训练数据回传又跑算力池通信,离线流量一起来就会挤掉算力集群带宽。
阿里云方案:专线出向 QoS——按业务优先级配带宽比例,互不干扰。
痛点 3:专线故障收敛慢
专线物理中断不可避免,传统冗余专线 + BFD 收敛是秒级(1~10s),对训练来说还是太慢。
阿里云方案:专线倒换组——同一倒换组里的 VBR 之间建容灾隧道,故障切换 < 100ms,业务无感。
小科普:什么是 VBR?可以理解成专线接入云上的"虚拟边界路由器"。倒换组的本质是:让同一组里的 VBR 互相做"备胎",谁挂了流量就跳到隔壁。
五、第三层升级|跨地域:Tbps 级骨干 + 金银铜链路 + ZooRoute
阿里云全球 29 个 Region 自建光传输网络,连接全球各区域数据中心。
对 AI 训练来说,关键三件事:
① Tbps 级互联 + 99.995% SLA
主要 Region 之间 Tbps 互联带宽,每天数百 PB 数据在 Region 间流动。
② 金/银/铜差分链路
不同业务挑不同档:
训练数据跨地域同步:选铜牌,降本;
关键参数同步、checkpoint 回传:选银牌,性价比;
跨地域推理请求:选金牌,最低时延。
加上 TR 的流量调度功能,可以按业务划分带宽配额,避免离线训练数据挤掉在线推理带宽。
③ ZooRoute:故障 1 秒内收敛
阿里云自研的主动式重路由技术:
多平面探测协议主动感知故障;
分级多指标调度算法自动选最优路径;
多链路批量秒级切换。
通常网络故障收敛时间从分钟级 / 秒级压到 1 秒内,业务层无感知——对动辄训练几天几周的大模型来说,这一点比带宽数字更重要。
六、规划落地:四步搭好训练网络
如果你正在规划企业 AI 训练网络,这 4 步是教科书级别的:
Step 1|训练 VPC 子网划分
至少包含:算力子网(灵骏/EGS/ACS-GPU)、存储子网(CPFS/OSS)、TR 接入子网、NAT 子网。职责清晰,不混跑。
Step 2|同 Region 跨 VPC 池化
所有训练 VPC 都挂到同 Region 的 TR,实现 VPC 间高速互通,构建同 Region 算力池。
Step 3|混合云接入
选 2 条以上冗余专线接入;
VBR 通过ECR 低时延接入 TR(避免跨 AZ 绕行);
配 BGP + BFD +专线倒换组;
大流量场景上400Gbps 单专线。
Step 4|跨地域池化
不同 Region 的 TR 互联;
按业务挑链路等级(金/银/铜);
按业务配跨地域 QoS(避免离线挤在线)。
七、一个被低估的事实
很多人以为,AI 网络优化就是"加带宽"。
但白皮书里反复在讲一句话:网络是算力效率的"放大器"。
ENI 200Gbps + RDMA → 让单机头不再是瓶颈;
400Gbps 专线 + 倒换组 → 让混合云算力池真的能跑训练;
Tbps 骨干 + 金银铜 + QoS → 让跨地域协同不抢带宽;
ZooRoute → 让长任务不被一次抖动毁掉。
算力堆得再高,没这套网络,利用率就会被卡在 50% 上不去。
下一篇我们聊推理——那是一个完全不同的网络故事:入口在哪、模型在哪、用户在哪,全都要被网络重新缝合。
