


算力是工具而非智能。或我们应该重新定义一种工具智能。亚理斯多德的《工具论》并非为日常用具而写。它给出了范畴和逻辑的定义。为何范畴和逻辑对我们做任何事情是重要的,因为范畴和逻辑是思考上的思考。通过工具思维,我们可以通达正确的科学和哲学的方向。
全国算力网必须有一个清晰的技术洞见。这个洞见不仅是可升级的,也是技术可兼容的。如果人们不希望好好的算力设施因为技术迭代很快沦为废品,人们就必须想,这种算力设施具有一种天然的先进性。这种先进性属于一,即不可分割的范畴。如果我们只是采用常规非创新的路径,算力网可能是消耗型和臃肿型结构的,这种结构无法指引我们走进历史的正确的思维,它将使我们的下一步的工作倾向停滞。由于算力网在我们的定义里面具有一定的工具智能,因此我们有必要以较低的代价运行和释放这种智能。如果人们说自己没有休息好,大脑很沉重,这样大脑就会短暂地停摆或失去活力,正是在此意义上,算力网和大脑一样,必须是日常的轻架构型态,低时延和低成本的创造,而且相对于美国的网络,具有天然的优势。
一、采用NRZ调制或半DSP调制打造低时延和低功耗的算力数据中心内部网络
在算力数据中心内部网络中,采用NRZ(Non-Return-to-Zero,不归零)调制以及“半DSP”/线性驱动方案(如 LPO、Hybrid)已成为兼顾低时延与低功耗的重要技术路径。两类方案分别面向不同的速率等级与传输距离场景,核心目标是在满足高速互联需求的同时,缓解传统全DSP方案功耗高、时延大的问题。
1. NRZ调制:成熟可靠,极致低时延
NRZ是一种传统的二进制调制方式,每个符号携带1比特信息。在短距离互联中,它凭借简单的物理层特性成为低时延首选。
适用场景:主要应用于 单通道≤200Gbps 速率的互联场景。随着技术发展,部分高性能SerDes也在探索基于NRZ原理的优化方案用于更高速率,但主流高速率(400G/800G)已转向PAM4。
优势:
- 极低时延:无需复杂的数字信号处理(DSP)进行均衡和纠错,信号从电到光的转换几乎无额外处理延迟。- 低功耗:电路结构简单,没有DSP芯片的高功耗负担,单模块功耗通常控制在较低水平(如几瓦特以内)。- 高信噪比容忍度:在光纤中,信道损耗较小,NRZ的二电平信号具有较好的抗干扰能力。
局限:频谱效率较低,难以支撑单波长50Gbps以上的高速传输,因此在400G/800G及以上速率的主流数据中心和AI算力架构互联中逐渐被PAM4取代 。
易飞扬的200G QSFP-DD S8/PSM8 平行光模块是这个领域的里程碑。
2.“半DSP”调制方案:LPO与Hybrid技术
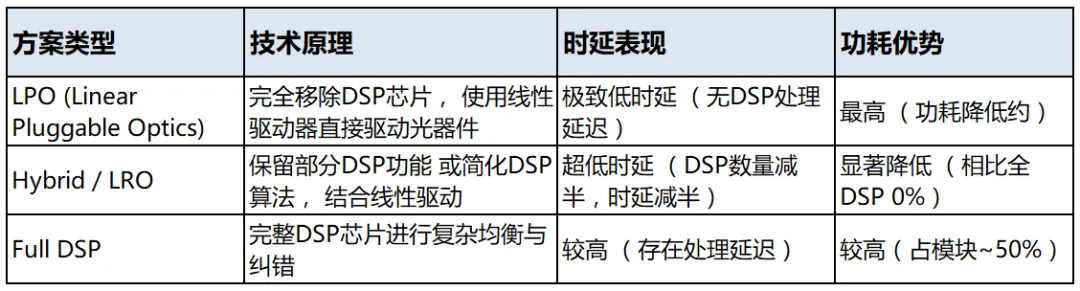
所谓的“半DSP”并非标准术语,通常指代弱DSP+LPO(Linear Pluggable Optics,线性可插拔光学)或Hybrid/LRO(Linear Receive Only) 等去DSP化或弱DSP化的技术方案。这些方案旨在保留一定信号完整性的同时,大幅降低传统全DSP方案的功耗和时延。
LPO (Linear Pluggable Optics)
LPO方案完全移除了光模块中的DSP芯片,仅保留线性驱动器(Driver)和跨阻放大器(TIA),依赖交换机侧ASIC芯片的强大均衡能力来处理信号。
Hybrid (Half Retimed &half linear LRO)/ LRO (Linear Receive Only)
Hybrid方案通常指在发射端或接收端保留部分线性驱动功能,或在特定方向上使用简化的DSP逻辑,以平衡性能与功耗。
特点:
- 功耗与性能的平衡:相比LPO,Hybrid方案可能在长距离(如100m-2km)上提供更好的信号完整性,同时仍比全DSP方案节能 20%-30% 。- 时延优化:虽然保留了部分处理能力,但通过简化算法或减少DSP数量,仍能实现显著的时延降低。
适用场景:100m – 2km 的中短距互联,适用于需要一定传输距离但仍对功耗敏感的场景 。
核心方案对比
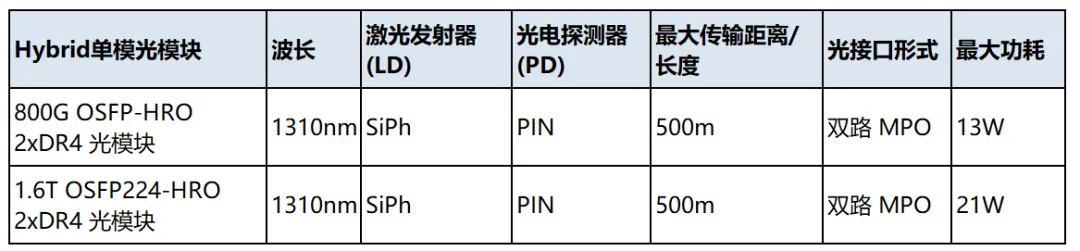
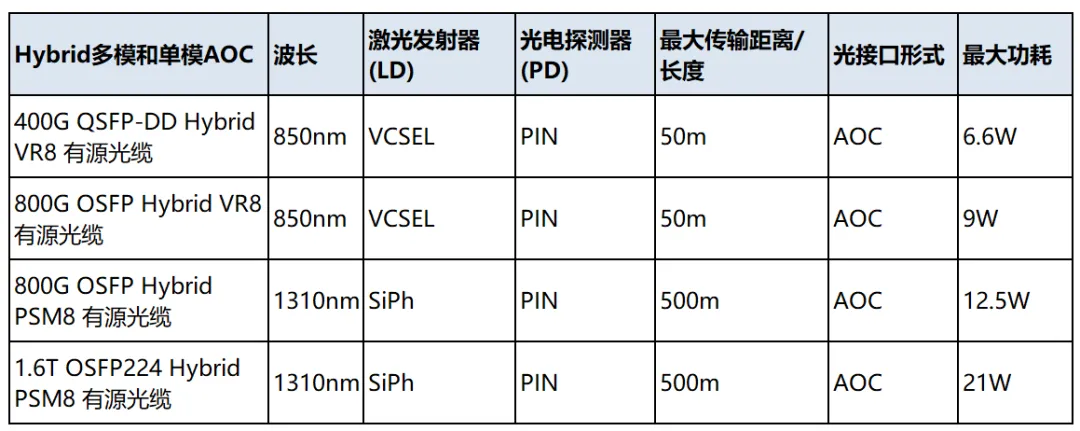
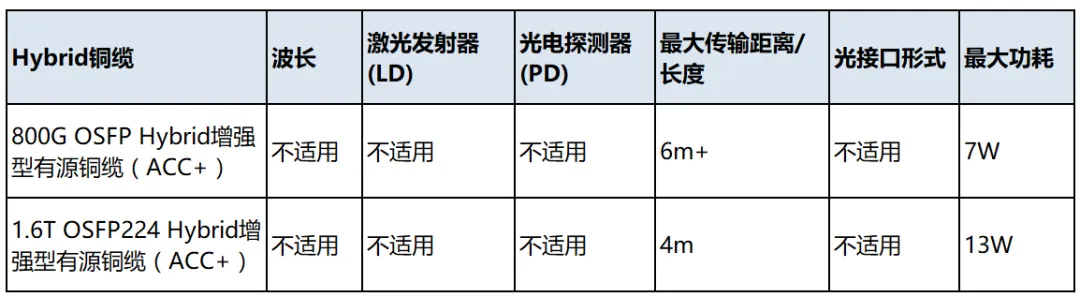
易飞扬的半DSP /Hybrid光模块和有源光缆产品线是这个领域的工程创新型产品。比LPO/LRO 具有超大型组网的现实可行性。此类产品列表如下:

二、采用O-BAND非相干DWDM作为DCI相干通信的有力补充,实现低时延低成本中短距DCI
随着AI算力集群和分布式数据中心快速发展,数据中心互联(DCI)对400G/800G/1.6T高速光互联提出了更高要求。传统相干通信方案虽然具备超长距传输能力,但其复杂DSP架构、高功耗、高成本以及较高传输时延,在30km以内的中短距DCI场景中逐渐显现出成本与效率的不匹配。
基于此,易飞扬(GIGALIGHT)推出基于O-BAND(1310nm窗口)的非相干DWDM系列产品,通过利用O-BAND天然零色散特性,实现无需DCM色散补偿的高效传输架构,为数据中心中短距互联提供了可替代相干通信的高性价比解决方案。
相较于传统C-BAND相干方案,O-BAND非相干DWDM方案具备以下核心优势:
低时延:省去复杂DSP色散补偿处理,显著降低链路传输延时,更适合AI训练、实时算力调度等低时延场景;
低功耗:采用硅光集成技术与PAM4调制架构,整体功耗远低于传统相干模块;
低成本:无需昂贵相干器件、DCM模块及复杂线路设计,大幅降低CAPEX与运维成本;
高密度部署:支持QSFP-DD、OSFP等高密度封装,满足下一代数据中心规模化部署需求;
灵活开放:支持开放光网络架构,适配白盒交换机与开放线路系统,提升网络灵活性。
从100G到800G, 再到1600G,易飞扬已经构建起业内最完整的O-Band DWDM可插拔产品矩阵,全面覆盖不同代际、不同容量的数据中心互联需求。
100G QSFP28 DWDM1:单波100G,极简运维,系统支持16波传输;
200G/400G QSFP-DD DWDM4:4路波长聚合,单波50G/100G,系统支持16波传输;
800G OSFP/QSFP-DD 2XPSM DWDM4 (O-BAND ,单波, 100G PAM4)系统支持16 波传输;
6T OSFP224-EL 2XPSM DWDM4 (O-BAND ,单波200G PAM4,外置光源),系统支持16波传输。
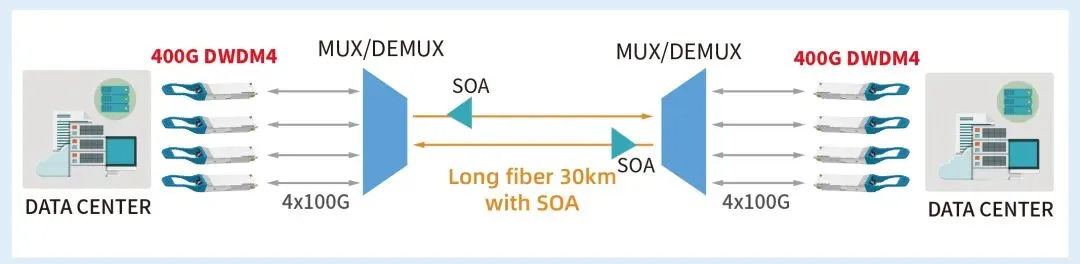
O-band DCI互联应用场景(2km-30km):
三、1.6T AI&DC互连的三种灵活解决方案
随着AI算力需求爆发式增长,数据中心互联带宽正从400G/800G快速向1.6T演进。为满足不同场景下的部署需求,业界围绕1.6T形成了三种主流解决方案路径,各具特色,适配不同的成本结构、功耗预算与规模化诉求。
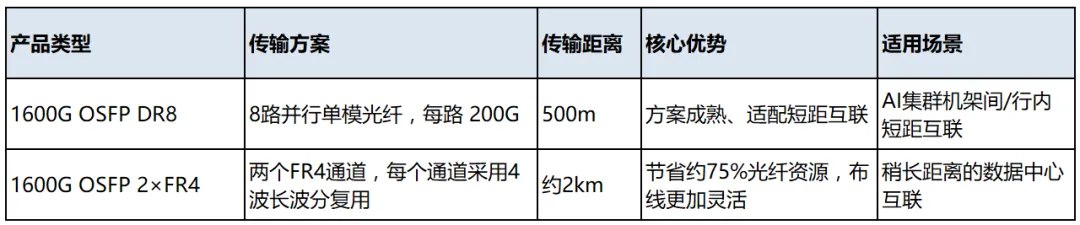
1. 标准 1.6T 可插拔光模块(Pluggable Transceiver)
标准1.6T OSFP224 光模块
1.6T OSFP224光模块是总带宽1.6Tbps、采用OSFP224封装的新一代高速光模块,是当前满足AI集群和超算带宽需求的主流产品。
核心参数与定义
- 速率与封装
总速率:1.6 Tbps,通过8个200G PAM4通道实现总带宽,净载荷扣除开销后刚好为1.6Tbps
OSFP224封装:OSFP封装的演进版本,具备224个引脚,支持16路电气通道,相比传统封装密度更高、散热能力更强,适配高密度AI交换机部署。

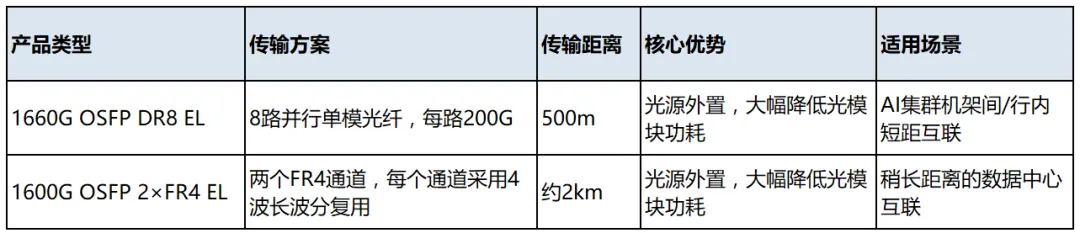
2. 外置光源的 1.6T 可插拔光模块(External Light Source Pluggable,ELS-Pluggable)
该方案将激光光源从1.6T OSFP224光模块中剥离,由机架级或板卡级集中式外置光源(ELS / Co-packaged Light Source)**统一供光,通过光纤耦合至各插拔模块。模块本身只保留调制器、探测器及必要的电处理单元,大幅降低单模块热耗散。
作为外置光源1.6T 可插拔光模块概念提出者,易飞扬可以提供如下外置光源可插拔解决
3. 外置光源的1.6T(16×100G) NPO解决方案(Near-Package Optics,NPO)
NPO方案是可插拔与共封装光学(CPO)之间的"过渡态"架构。光引擎(Optical Engine)不再封装于交换芯片内部,而是紧贴封装体外侧安装(距ASIC <50mm),配合外置光源通过硅光子或聚合物波导实现超短距高速互联。1.6T NPO 方案通常与**硅光子(Silicon Photonics)**平台深度结合,实现极低电-光传输损耗。必须注意,可实用的NPO 光引擎基本必须基于16×100G或32×100G 的物理架构。这是和1.6T可插拔光模块主要的界分点。虽然业界正在投票基于224G SERDES的3.2T/6.4T NPO 架构,但这一标准尚未出台。
三种方案对照比较:
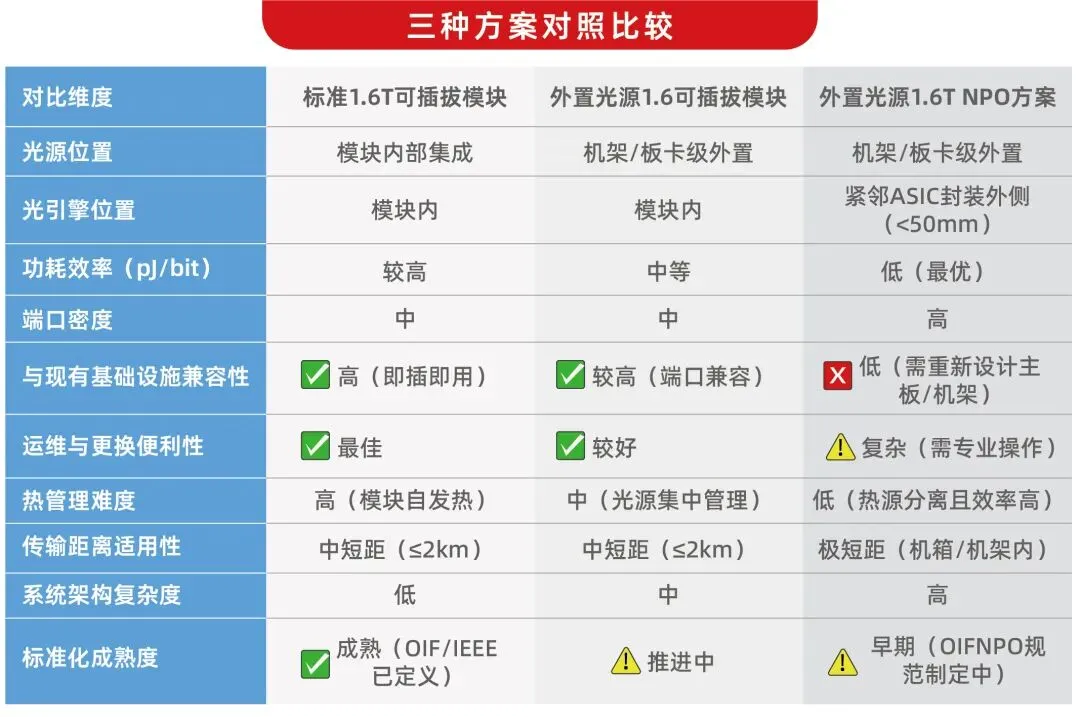
三种方案并非相互替代,而是针对不同阶段和场景的分层部署策略:
近期(2024~2026年):标准可插拔模块仍是主流,满足绝大多数数据中心的平滑升级需求;
中期(2027年+):外置光源可插拔方案很有可能将在超大规模AI集群中快速渗透,兼顾部署便利与功耗优化;
远期(2027年+):NPO方案随着硅光子与标准化成熟,有望成为AI超算互联的主导架构,为迈向2T/6.4T奠定基础。
四、采用AWGR +EDFA /AWGR+SOA实现关键节点枢纽的全光低时延交换
1. AWGR(阵列波导光栅路由器)
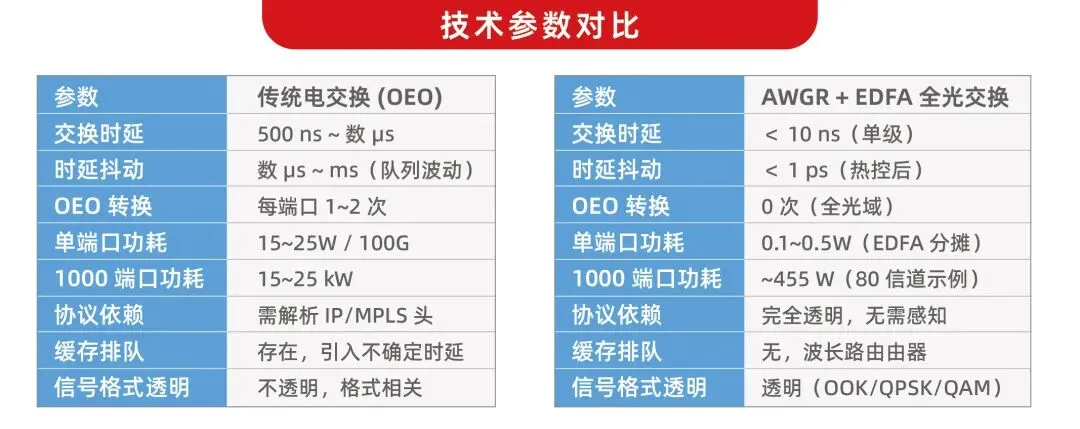
AWGR作为无源波长路由引擎,利用其循环路由特性,将WDM信号中不同波长的光确定性地映射至对应输出端口,无需查表、调度或缓存,彻底消除了传统电交换的"光—电—光"转换环节。信号全程保持光域形态,单级交换时延仅为纳秒量级,较传统OEO架构降低 2~3 个数量级,且时延抖动极小,具备高度确定性,可满足算力低时延切换路由的业务需求。
2. AI算力集群AWGR+EDFA拓扑结构
层级架构说明
- 该架构多用于数据中心跨机柜/跨园区长距离全光交换枢纽,拓扑采用"计算接入-核心波长交换-光放大输出"三级扁平结构:- 接入层:每个AI计算节点/GPU服务器通过 100G PSM DWDM4 (C-BAND) 光模块输出信号,每个端口直接携带4个C波段固定波长,信号通过光纤汇集到DWDM合波器(MUX)。- 核心交换层:合波后信号送入N×N AWGR波长路由器,基于波长完成全光路由交换,输出侧信号完成光路切换。- 补偿输出层:AWGR交换后存在约8dB固有插损,经过EDFA光放大器放大补偿损耗后,输出到下一级交换节点或目的计算集群,满足10km级传输要求。
拓扑特性
无多层O-E-O转换,核心交换时延<1μs,整体架构简洁,适合拓扑相对稳定的大型算力枢纽部署。
技术参数对比:
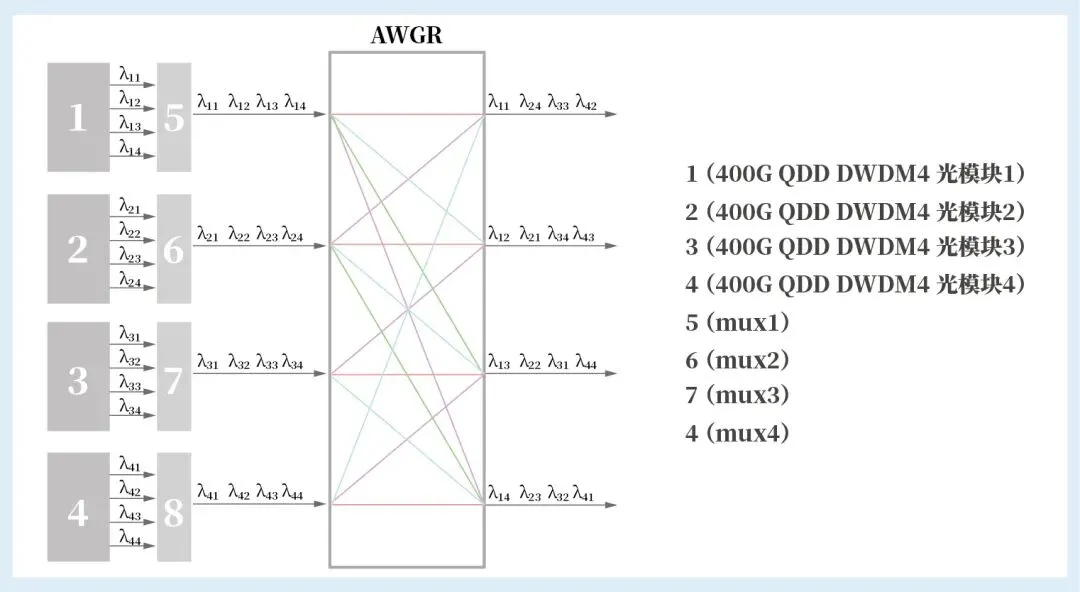
3. AI算力集群AWGR+SOA拓扑结构
该架构多用于机柜内部/同机房短距离高密度全光交换枢纽,拓扑采用"有源调度+全光交换+集成放大"紧凑结构:
波长调度层:每个计算节点连接O-BAND DWDM 光器件或O-BAND多波长可调谐光引擎,调度控制器根据GPU通信需求(梯度同步/参数广播)动态调整输出波长。易飞扬提供不同波特率的O-BAND DWDM 平行光模块适配中短距AI 算力互连场景。
核心交换层:动态波长信号送入AWGR完成基于波长的全光路由,实现纳秒级光路切换。
集成放大层:采用集成化SOA半导体光放大器对交换后弱信号进行放大,相比EDFA体积更小,适合高密度机柜内部署,同时可辅助完成波长变换,提升调度灵活性。
拓扑特性:整个交换过程时延可压缩至100纳秒以内,单芯片功耗仅为同类电交换ASIC的1/10,适合万卡级AI训练集群的GPU横向低时延通信。
组网示意框图如下:
关键节点选型建议:

结束语
由于算力网的本质是工具调用的能力。单纯的算力网—这一昂贵的基础设施,如果没有全民好学的基础,算力网将是没有意义的。从任何商业的发展角度攀附算力大模型,这将和语言为建构的知识事业发生冲突。商人组织只能在算力网上思考创新,他们不能希望算力本身是竞争能力。算力网必须是惠民智力的网络。否则花费万亿巨资产生不了任何正向的效果。正如以往的电信管道是连接信息的目的。算力网必须是连接人的工具智能的目的。只有对算力网的目的做好精确的竞争力的定义,算力网将成为我们国家愿意埋单的一张网络。


关于易飞扬
作为开放光网络器件的向导,易飞扬(GIGALIGHT)集有源和无源光器件以及子系统的设计、制造和销售于一体,产品主要是传统III-V族光模块、硅光模块和硅基NPO/CPO引擎、浸没液冷光模块、光无源器件、有源光缆和直连铜缆、基于相干光模块和非相干O-band DWDM 光模块的OPEN DCI BOX子系统,以及超高清SDI 视讯光模块等产品。易飞扬重点服务AI算力数据中心、5G承载网、城域波分传输、超高清广播视讯等应用领域,是一家创新设计的高速光互连硬件解决方案商。
