做过类案检索的朋友们都有同感,做类案检索不难,但是要做好类案检索就费时费力。从设定检索条件、判断相关性到归纳整理裁判观点、庭审证据乃至总结地区倾向……完成一份高质量的类案报告可能需要花上数个小时。但是现有AI工具用起来很难称心如意不说,多数 AI 工具只做到 “罗列案号 + 一句话要点”,真要用到卷宗里、写进研究报告,还得自己花大半天返工;更要提防 “真案号配假判词” 的 AI 幻觉,暗藏执业风险。
为此我做了一套自动的类案检索分析报告系统。输入案情或研究主题,输出三样东西:一份研报排版的 Word 报告(封面、目录、脚注、统计图表、页码都有,每个引用都带案号、法院和数据库链接),一份 Excel 类案清单,外加一套判决原文集——报告里每一段实质说理,都能在原文集里找到出处。项目对接北大法宝MCP官方数据源(注:需要自己另行订阅北大法宝MCP。项目也搭建了其他数据源的格式,但是推荐北大法宝的MCP,检索起来最省心,返回结果工整,不用另行处理数据了)。
已经搭好了全流程自动化工作流,同时内置四道验证关卡兜底内容真实性。这些天不眠不休到现在迭代了13个版本,用起来已经比较顺手了。现在代码、文档、演示数据全部 MIT 协议都开源出来,希望能帮助到更多的朋友。
GitHub 地址:
https://github.com/silvrblt/legal-case-research
有需要的朋友可以自取,以下对项目功能和使用方法做一个简单介绍。
一、两大模式,办案/ 研究都可以直出定稿报告
针对「个案办案归档」和「专题规则研究」两类最高频场景,项目设计了两套独立工作流,输出标准各有侧重,成品均无需人工二次排版整理。
两大模式核心对比
对比维度 | 实案研究模式(办案版) | 学理研究模式(研究版) |
核心场景 | 单一案件诉讼准备、卷宗归档、庭审研判 | 法律专题调研、学术写作、行业裁判口径分析 |
检索范围 | 定向指定法院,严格遵循法定检索顺位 | 全国范围全量检索,支持定向法院专项分析 |
核心产出 | 归档式 Word 报告 + Excel 类案清单 + 判决原文集 | 全景研究报告 + 多维统计图表 + 核心案例库 |
内容重点 | 类案对标、要素拆解、相似性评分、参照要点 | 规则演进、观点分歧、数据分布、趋势总结 |
适用人群 | 执业律师、企业法务、司法办案人员 | 法学研究者、合规专员、律所专业团队 |
?实案研究模式:合规优先,生成即可直接入卷
完全对标最高法《关于统一法律适用加强类案检索的指导意见(试行)》设计,从检索逻辑到报告格式全流程符合司法实务要求。
- · 检索顺位合规:按「指导性案例→最高法案例→本省高院→上一级人民法院及本院」法定顺序检索,层级清晰;
(注:项目已经内置了截至发文的全部指导性案例,可以开箱即用。不过由于指导性案例数量少,更新慢,所以没有设置抓取案例的程序。当需要更新的时候,可以再手动抓取更新一下)
- · 类案深度拆解:自动对重点类案完成 6 项结构化拆解:基本案情、抗辩逐条梳理、裁判逻辑对应、证据对照表、相似性评分、参照裁判要点;
- · 归档要素齐全:Word 报告自带封面、目录、页码、脚注,附录完整列明检索过程、筛选标准、检索缺口,配套 Excel 清单与判决原文集,所有引用均可溯源。

(点击图片可放大查看)
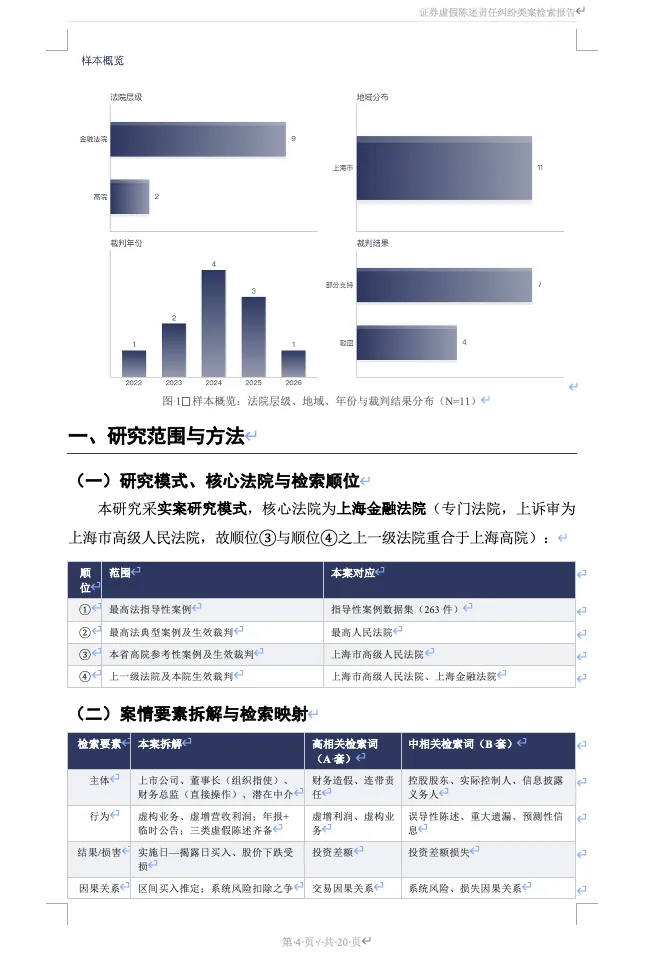
?学理研究模式:数据驱动,全景梳理裁判规则
面向专题研究场景,支持全国范围或指定法院批量检索,输出体系化的裁判规则研究报告,专业度对标司法研究机构的分析文稿。
- · 智能数据清洗:针对证券虚假陈述等集团诉讼,自动折叠同源平行判决,仅保留说理最完整的核心案例,避免统计失真;
- · 体系化规则拆解:以侵权构成要件为核心框架,逐争点梳理主流观点、例外情形、各地裁判分歧,对比新旧司法解释的规则演进;
- · 严谨结论约束:内置样本量闸门,样本不足时自动收敛结论措辞,不强行推断 “地域裁判倾向” 等无统计依据的内容。
既可以做全国范围的全景研究(如《证券虚假陈述裁判规则全国研究报告》),也可以定向聚焦特定法院(如《京沪金融法院证券虚假陈述裁判对比报告》),灵活适配不同研究需求。


(点击图片可放大查看)
二、报告专业度的细节设计
一份能用的专业报告,不止是把文字堆起来,更要符合朋友们的使用习惯和专业标准,这几个细节是项目的核心打磨点:
- · 引用全程可溯源:报告中每一处裁判观点都标注案号、审理法院与数据库链接,对应判决原文同步打包交付;
*One more thing,还会交付一份Excel格式的案件清单,其中不仅列出了所有分析的案例,同时逐行列出了争议焦点以及相对应的抗辩观点和法院的裁判观点,庭审争议能够一目了然。

(点击图片可放大查看)
- · 分歧点重点突出:不回避裁判争议,专门将各地法院的分歧意见作为核心产出呈现,而非一笔带过;
- · 检索缺口主动公示:不吹嘘 “全覆盖”,明确列出高关注度典型案例的覆盖情况,哪些未检索到、哪些仅作名录提示,全部坦诚说明;
- · 格式统一规范:所有报告结构、标题层级、引文格式、图表样式统一,符合法律文书的专业排版标准。
三、四道验证关卡防幻觉
专业报告的底线是内容真实。针对 AI 类案检索最突出的“虚构案号、篡改判词” 问题,项目在全流程末端设置了四道自动化验证关卡,用确定性的程序逻辑校验每一份产出。
1. 案号溯源关卡
报告生成后,脚本自动提取全文所有案号,与本次检索落地的本地判决库逐一比对。库中不存在的案号直接报错,终止报告输出,从源头杜绝虚构案件。
2. 引文核验关卡
专门针对 “真案号配假判词” 设计。报告中所有弯引号标注的判决原文,都会与裁判全文做逐字匹配,AI 改写、拼接的伪引文会直接被识别。
同时配套统一规则:判决原文用弯引号,归纳总结用直角引号;直角引号内若出现大段裁判文书句式,会自动标记提醒人工复核,堵住漏洞。
3. 编码抽检关卡
对案件争点归类、抗辩采信情况等 AI 定性判断,系统随机抽取不少于15% 的样本,将 AI 结论与判决原文并列生成复核清单。借鉴学术研究的编码者信度检验逻辑,用抽样复核保障定性准确。
4. 样本量闸门关卡
一条写死在代码里的硬约束:样本数量不足时,不允许生成确定性结论。该规则纳入回归测试,任何代码改动破坏约束都会被拦截,从机制上保障统计结论严谨客观。
四道关卡全部接入持续集成流程,每次生成报告、更新代码都会自动全量校验。机制上线之初,就连我自己写演示数据时的不规范引文都被精准检出,校验效果实打实。
四、上手简单,零基础也能用
1. 免费体验:十分钟看完成品效果
无需付费订阅,本地安装 Python 3.11+、Node.js、Git 三款基础工具后,克隆仓库运行内置演示命令,就能用脱敏合成数据生成完整报告,直观查看成品效果。具体命令可直接参考仓库 README。
2. 正式使用:对接数据源即可开工
真实检索需要准备北大法宝 MCP 订阅与 AI 编程助手,仅需一步配置 Token,再设置好个人署名与行文偏好,后续所有报告都会自动匹配你的风格。
全程对话式操作,流程内置两个人工确认节点(检索前核对要素、检索后确认样本),专业判断由人把控,体力活交给机器。
3. 无接口也能用:支持导入自有数据
没有法宝订阅也没关系,支持导入裁判文书网、律所内部数据库导出的 CSV/JSON 格式判决数据,导入后分析、生成报告、校验关卡全流程完全一致,兼容性极强。
写在最后
AI + 法律的工具很多,但大多停留在 “帮你找案例” 的阶段。这个项目想往前走一步:不止检索,更直接交付可落地、可核验、可归档的专业成果。
让机器承担检索、拆解、排版、校验这些重复劳动,把朋友们的时间留给专业判断,这是我理解的 AI 工具的真正价值。
不过需要提示的一点:关于AI工具,目前主要是在Claude Code上opus 4.8跑通的。虽然在SKILL等项目文件上尽可能兼顾到其他的AI工具,但是囿于工具能力,可能在具体执行上还是会有差别。
如果有朋友不想倒腾的话,可以私信我帮忙代查,报销一下token就好。
项目完全开源开放,欢迎各位朋友们fork体验、测试提意见,每一个反馈都是工具优化的方向。让我们一起帮助法律行业变得更好。
项目地址:
https://github.com/silvrblt/legal-case-research
希望大家玩得开心!
-Silvrblt