公众号并非行业报告搜索引擎,点击查看→新用户必读【如何下载】


报告延伸:2026全球AI算力发展研究报告(文末附全文PDF) 出 品 方:中国智能计算产业联盟
一、算力狂飙:模型越大,算力越“吃”得凶
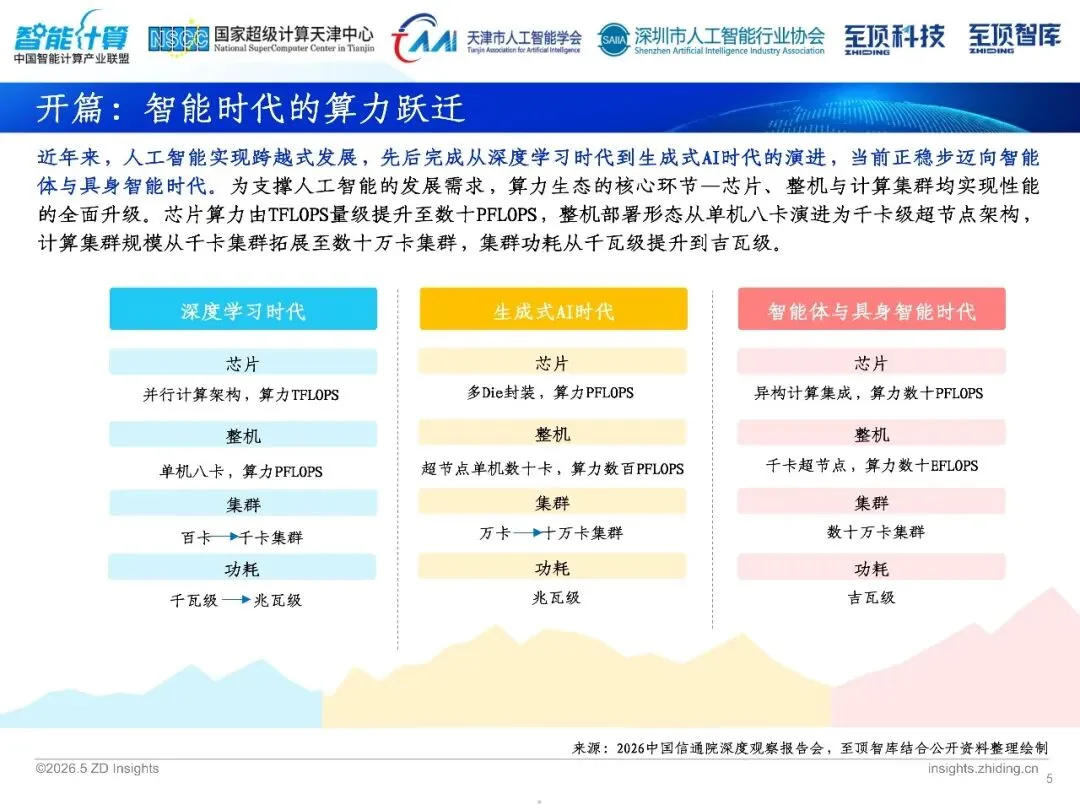
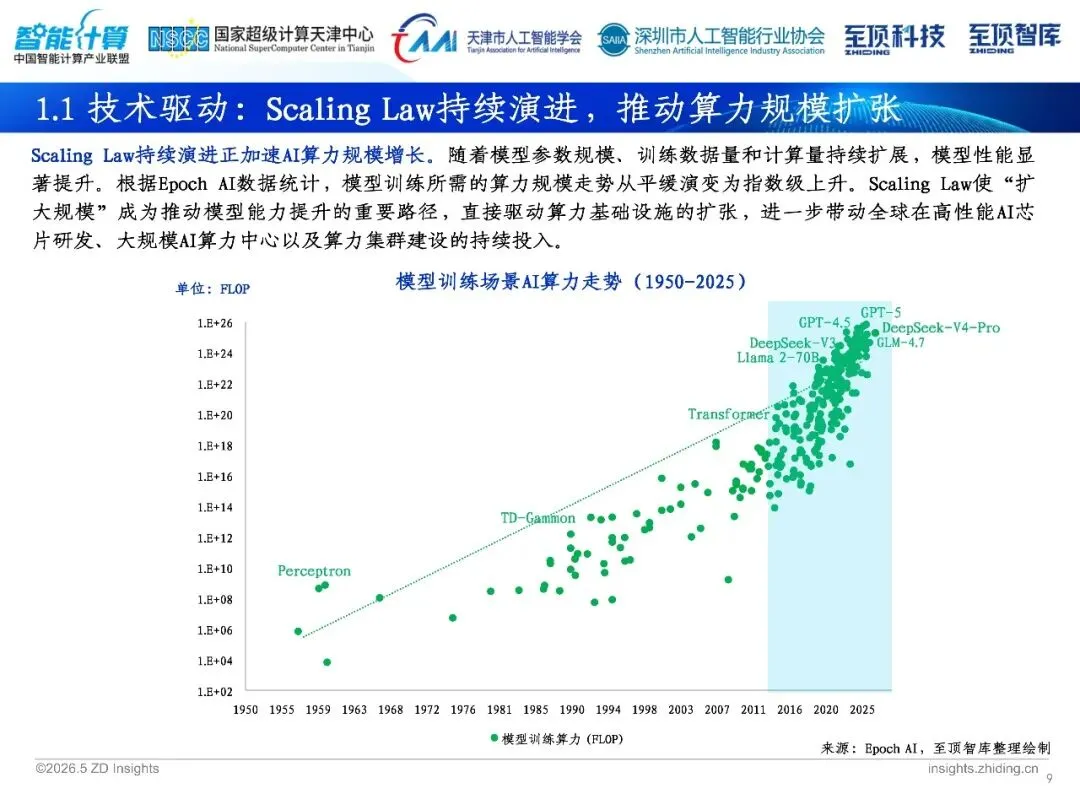
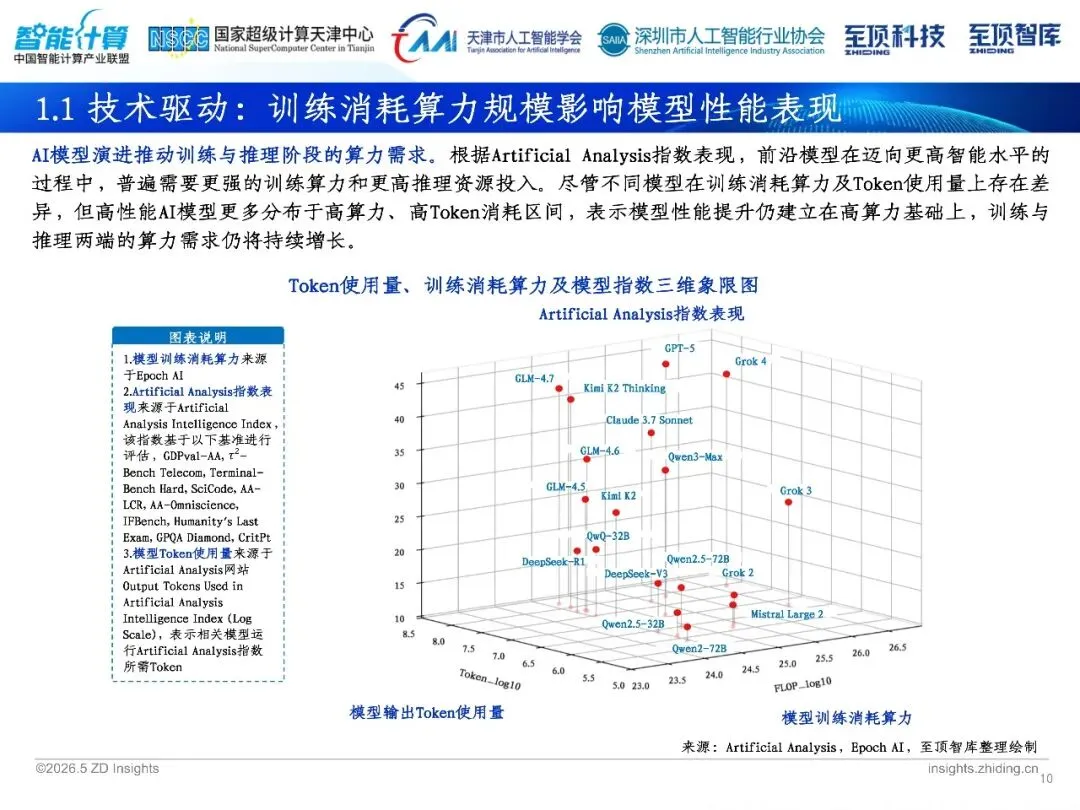
在过往的几年当中, AI训练算力先是从呈现指数级爬坡状况转变为呈现火箭式蹿升态势, 千卡集群已然属于过去的形式, 十万卡集群已然成为新的常态了。单芯片算力从TFLOPS数量层级跳跃至数十PFLOPS数量层级, 集群功耗从千瓦级别快速暴涨到吉瓦级别。这背后是Scaling Law在持续发挥力量: 参数数量越多、数据规模越大、算力越强大的话, 那模型也就会变得更加聪明些。2030年的时候 , 全球算力中心所具备的容量会从102GW增加到220GW , 其中AI负载所占的比重也将会超过70%。而算力正逐渐成为像电力那样的基础设施。
二、芯片领域展开激烈竞争, 其中NVIDIA处于领先靠前的位置, 而国产的众多相关团队在奋力快速追赶
基于 NVIDIA 的 Rubin GPU 实现推理算力高达 50 PFLOPS(FP4), 其配有 288GB 的 HBM4 以及 3.6TB/s 的 NVLink, 堪称性能怪兽。然而国产芯片正努力奋起直追: 如华为的昇腾 970 目标为 8 PFLOPS(FP4), 昇腾 384 超节点已然落地;沐曦、飞腾、摩尔线程是在训练和推理两条线上同时展开行动。国外追求的是单芯片的峰值, 与之不同的是国内更擅长于在集群方面实现突破以及在软硬方面进行协同——华为的“韬定律”着重强调要通过系统优化来降低时延。在AI芯片竞赛当中, 不再仅仅围绕着拼算力展开了, 开始进入架构方面的比拼,进入互联方面的比拼, 进入生态方面的全方位比拼。
三、超节点+液冷:算力中心的“新标配”
已成历史事物是单机八卡, 华为384卡、中科曙光640卡超节点架构致使几百块芯片“黏”在一起, 达成超高带宽以及超低延迟, 然而单芯片功耗突破1000W, 风冷完全承受不住了。液冷全面占据主导地位: 冷板式、浸没式可以将PUE从1.4以上压低至1.1以下。不要轻视这0.3——一个大型算力中心电费有几亿元, PUE每降低0.1就能节省几千万。液冷已然不是选项, 而是必须要修习的课程。
四、算力出现了“下凡”的情况, 它能够制造蛋白质, 它能够开启自动驾驶模式, 它能够管理工厂
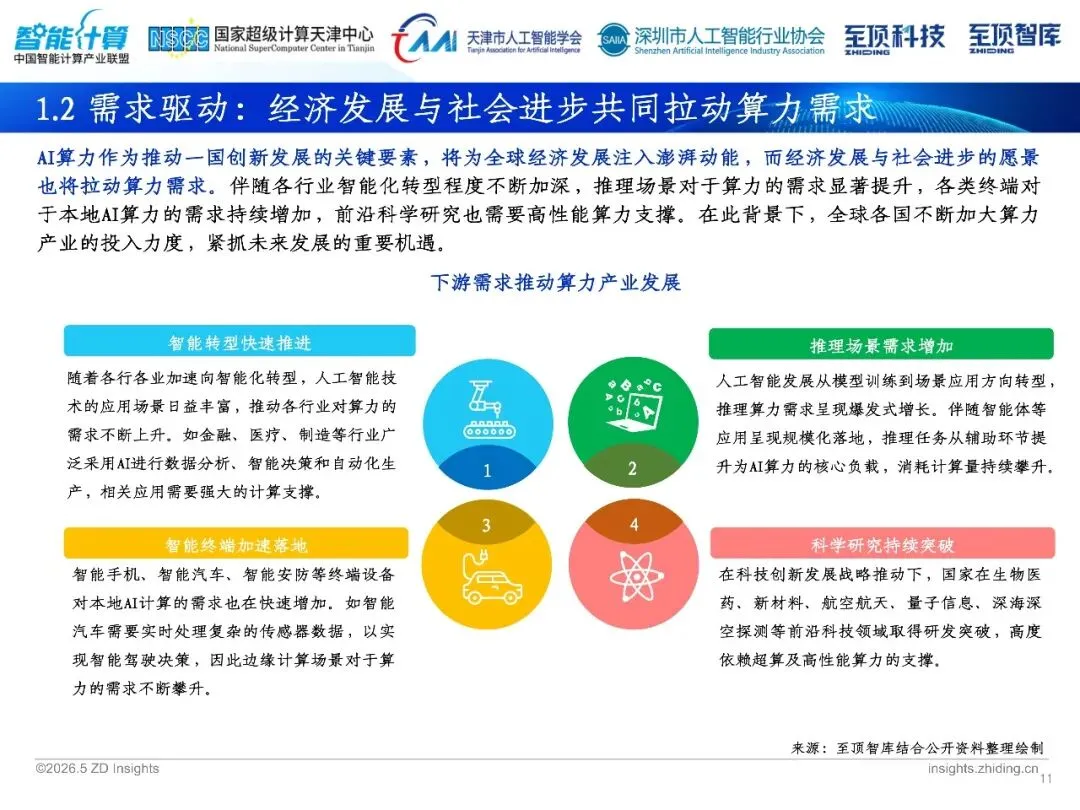
算力并非仅存于论文之中, 而是正着手开 展各类“贴近实际”的工作。AlphaFold 3运用扩散模型预测蛋白质结构, MatterGen直接生成全新材料, 科研模式从“反复尝试纠错”转变为“直接生成”。地平线征程6芯片已应用于车辆, 舱驾融合使智能驾驶与座舱合二为一;工厂里的智能质量检测、预测性维护, 公路上的车路协同、无人配送, 均全然依赖端到端的算力予以支撑。算力正从“昂贵稀罕之物”演变成“日常常用物品”。
五、后续有三个主要的发展方向, 分别是, 新能源领域, 太空算力层面, 算网融合
算力迅速狂奔向前, 能源却陷入告急状态——到2030年的时候, 全球数据中心每年的耗电量将会快要接近1000TWh。短期内依靠风光储来解决, 中期要上马小型核反应堆也就是SMR, 长远来看则期待氢能。更具有科幻色彩的是: Starcloud已经把H100送到太空当中并且进行大模型的训练了, 国星宇航实施“星算计划”要发射太空计算中心。在国内是走“算网融合”这样的路径——使得算力能如同水电那般随时取用, 三大运营商已经开始建设算力互联网了。算力的将来, 不仅仅是在地面上, 更是在星辰大海那里。在“那里”后面。









『公众号并非行业报告搜索引擎,下方链接一键解锁20W份报告』

免责申明:top行业报告收录的资料版权归原撰写/发布机构所有,若版权方认为有侵权问题,请立即通知删除。TOP行业报告——全行业报告平台,分享有价值的行业研究报告,行业数据报告,行业分析报告,行业调研报告,仅供行业科普学习。 点击查看→新用户必读【如何下载】