

英伟达最新财报一出来,很多人只看到两个数字,816亿美元营收,85%的同比增长。
然后立刻得出结论,AI还没见顶,英伟达还在狂飙。
但yiyi想说,这次财报真正重要的,不只是英伟达又卖了多少GPU,而是它释放了一个更强烈的信号,人工智能发展的瓶颈,正在从“缺芯片”,变成“缺网络、缺光通信、缺存储、缺电、缺冷却”。
先看看英伟达这份财报到底有多猛。
英伟达2027财年第一季度,营收 816亿美元,同比增长 85%。
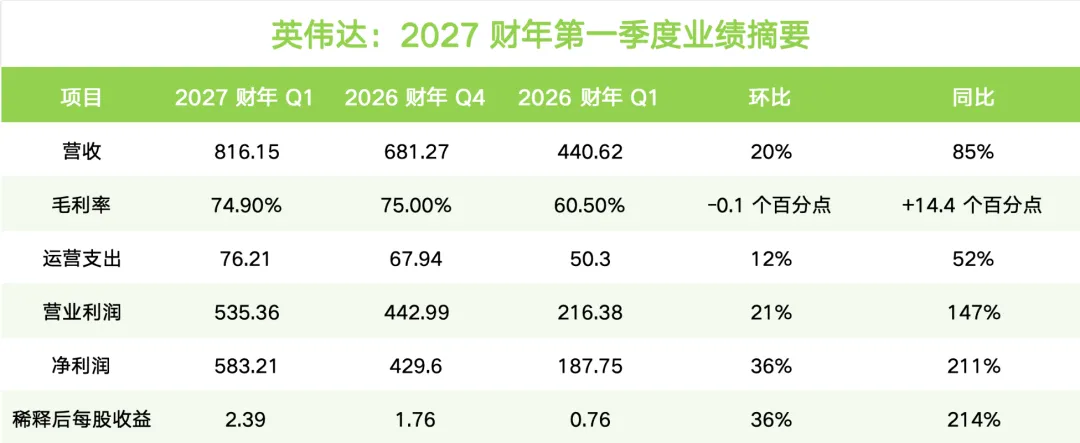
数据中心收入 752亿美元,同比增长 92%;毛利率还稳在 75%左右。
更夸张的是,公司给出的第二季度收入指引达到 910亿美元,上下浮动 2%。
这里有个细节,非常关键,这个指引里,英伟达明确没有假设,来自中国地区的数据中心算力业务收入。
这说明,即使暂时不把中国高端数据中心算力收入算进去,全球AI基础设施需求依然非常强。海外云厂商、主权AI、企业AI、推理应用、智能体应用,都还在继续要算力。
所以这份财报真正想告诉市场的,不是AI资本开支要停了,而是AI基础设施进入了第二阶段。
上一阶段是买GPU,谁买得多,谁就看起来领先。
下一阶段是建AI工厂,谁能把GPU、网络、存储、电力、液冷、调度系统全部组织好,谁才是真正有效率。
而这次最亮眼的数字,其实不是GPU,是网络。
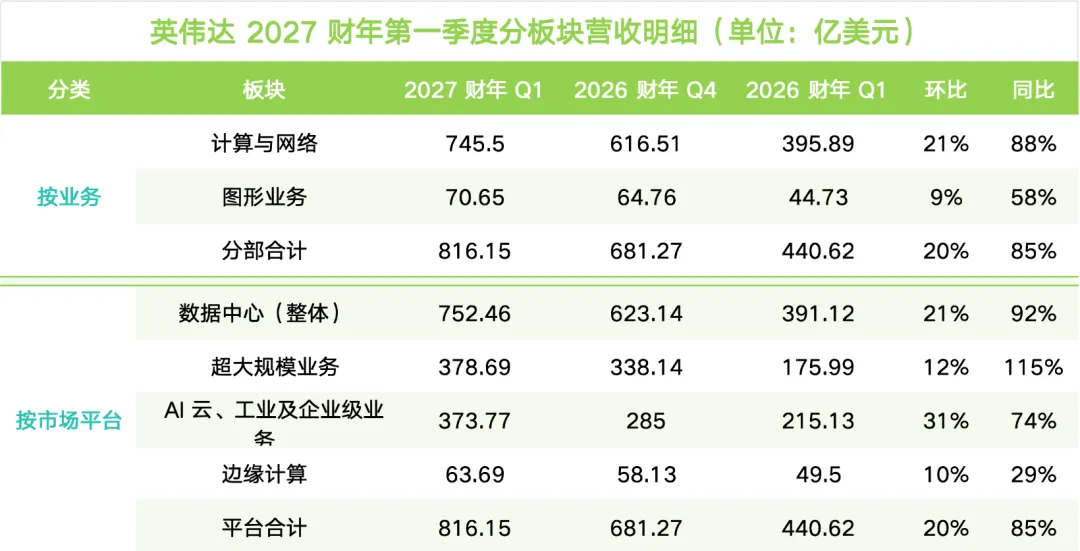
英伟达数据中心计算收入 604亿美元,同比增长 77%。这个增速已经很惊人了。
但数据中心网络收入达到 148亿美元,同比暴涨 199%,环比也增长 35%。
这才是重点。
如果把GPU比作AI工厂里的工人,那网络就是工人之间沟通的道路、电话线和传送带。
工人再多,如果互相传消息很慢,材料送不到,任务分配不过来,那大家就只能站着等。
AI模型越大,GPU数量越多,这个问题就越明显。
几千张、几万张GPU一起训练和推理,不是把它们放进机房就结束了。它们之间要不停交换数据,模型参数要同步,推理请求要分发,存储里的数据也要快速调出来。
任何一个环节慢一点,昂贵的GPU就会被迫等待。
而GPU一等,烧的可不是时间,是钱。
这就是为什么,光通信这次会成为最直接受益的方向。
英伟达不是只在财报里说网络重要,它已经开始用真金白银绑定全球光学产业链。
它和 Coherent达成多年战略协议,并投资 20亿美元;和 Lumentum签协议,也投资 20亿美元;和 Corning合作扩大光连接和光纤产能;还和 Marvell围绕 NVLink Fusion、定制XPU、硅光、先进光互连等方向合作,并投资 20亿美元。

这不是普通买货,而是在提前锁定AI工厂里的“高速公路”和“光纤管道”。
为什么英伟达这么着急?
因为AI集群规模越大,传统连接方式越容易遇到瓶颈。
数据中心内部距离并不算远,但数据量大得吓人。卡和卡之间、机柜和机柜之间、甚至不同数据中心之间,都需要更高速、更低延迟、更低功耗的连接方式。
这就是光通信的价值。
所以现在 800G光模块 还在放量,1.6T已经开始导入。再往后,硅光、LPO、CPO、OCS这些新技术路线,也会被市场反复讨论。
映射到中国,这条产业链就很清楚了。
高速光模块、光芯片、激光器、硅光平台、PCB、连接器、高速线缆、光纤光缆,都可能被AI数据中心需求带动。
但这里千万别一听“光通信”就上头。,不是所有沾上光通信概念的公司都能躺赢。
低端组装环节很容易卷价格。最后可能出现一种情况,收入看起来增长了,但利润没变厚,甚至还被压薄了。
真正有价值的,是高速率产品能力、良率控制、全球大客户认证、核心光芯片和激光器能力,还有海外供应链布局。
所以光通信这条线,短期看订单,中期看 800G到1.6T的切换,长期看硅光和光电共封装能力。
再看中国算力。
这次财报里有个很微妙的点,英伟达第二季度 910亿美元 的收入指引,没有把中国数据中心计算收入算进去。
有人看到这里,会觉得这是利空中国。
但yiyi老师更愿意把它理解成,这给中国算力产业按下了加速键。
因为它提醒我们,中国的大模型、行业智能体、工业AI、政企AI应用,不能把未来全押在外部高端GPU供应上。
外部供应越不确定,国产算力闭环就越重要。
但注意,国产算力不是简单造出一颗AI芯片就结束了。
未来拼的是整套系统。
包括国产AI芯片、AI服务器、国产交换机、智算中心、算力租赁平台、算网调度、液冷、高密供电、低成本绿电、数据中心运维能力。
任何一块短板,都可能拖慢整体效率。
尤其在 全国一体化算力网 和 算电协同 的政策框架下,中国算力建设会越来越像一张全国级别的“算力高速网”。
以前大家问的是,你有多少卡?
以后更关键的问题会变成,你的卡有没有客户用?上架率高不高?电价贵不贵?电源使用效率能不能降下来?液冷能不能跟上?跨区域算力能不能调得动?
这就像开餐馆,不是买了十口大锅就一定赚钱。
有没有客人,煤气费贵不贵,厨师效率高不高,后厨动线顺不顺,才决定这家店能不能活下来。
所以中国算力链的机会,会集中在真正能提高效率、降低成本、稳定交付的环节。
国产AI芯片、服务器整机、液冷、高密供电、国产交换设备、算力调度平台,都值得持续跟踪。
但只讲“我有算力”,却没有利用率、客户订单和现金流的项目,就要小心。
接下来讲讲存储。很多人一听存储,就想到硬盘、SSD、数据仓库。
数据多了,就多买点盘;模型大了,就加点容量。
这个理解在AI训练早期还可以,但到了智能体AI时代,就不够了。
因为存储的角色正在变化。它不再只是“仓库”,而是AI的“记忆系统”和“工作台”。为什么这么说?
以前你问AI一句话,它回答一句话,任务就结束了。
但现在的智能体不一样。它要规划任务,要调用工具,要读企业资料,要连续对话,还要多个智能体一起协作。
这就要求AI必须记住更多上下文,并且能在不同节点之间快速共享这些上下文。
这里就牵涉到一个关键概念,KV cache。
你可以把 KV cache理解成AI推理过程中的“临时记忆”。
对话越长,任务越复杂,这个临时记忆就越大。
如果所有临时记忆都塞在GPU显存里,GPU很快就会被占满。结果就是推理速度下降,成本上升,用户等得更久。
所以问题变成了,能不能把这些上下文记忆,用更高效的方式存起来、调出来、共享出去?
英伟达给出的方向,就是BlueField-4、AI数据平台,以及推理上下文内存存储平台。
这些技术听起来很复杂,但背后的逻辑很简单,
AI越聪明,越需要更强的记忆系统。
而这个记忆系统,不只是一块硬盘,而是存储、网络、DPU、智能网卡和GPU一起配合。
映射到中国,短期更现实的机会,是企业级SSD、存储服务器、分布式存储、对象存储、AI数据平台、RDMA/RoCE、智能网卡等等
中长期更有想象力的,是向量数据库、国产DPU、KV cache分层存储、AI原生文件系统、近存计算和推理优化软件。
尤其是企业AI落地之后,真正的问题不会只是“有没有模型”。
企业里大量合同、图纸、客服记录、研发文档、图片、视频,能不能变成AI能理解、能检索、能调用的数据资产,这才是关键。
所以存储这条线,短期可能没光通信那么刺激,但它很可能是AI推理时代最容易被重新定价的基础设施。
把这三条主线放在一起看,逻辑就很清楚了。
光通信,信号最直接。 因为英伟达网络收入同比增长 199%,还真金白银投了Coherent、Lumentum、Corning、Marvell。
算力,底盘最重要。 因为AI工厂建设周期还没有结束,中国又叠加了国产替代、全国一体化算力网和算电协同。
存储,长期最容易超预期。 因为智能体AI、长上下文、多模态和企业数据接入,会持续推高对高速存储和AI数据平台的需求。
但最后一定要提醒一句,财报利好,不等于所有公司都利好。
光通信要看客户认证和技术迭代,不能只看概念。
智算中心要看利用率、电价和现金流,不能只看建设规模。
存储要看产品是不是真的进入AI推理链路,不能只靠讲故事。
这份英伟达财报真正告诉我们的,不是AI泡沫破没破,而是AI已经从“买芯片”,走向“建基础设施”。
谁能把芯片、网络、光通信、存储、电力、液冷和调度,连成一张高效率的网,谁才有机会吃到下一轮AI红利。
记得点好关注,yiyi陪你穿透科技的迷雾。

市面上讲半导体的人很多,但大多数是观察者在转述。
我做过芯片设计公司的联合创始人,做过投资机构的产业研究,也做过面向百万用户的科技自媒体传播。这条路走下来,我越来越清楚一件事,真正准确有效的半导体产业认知,只能来自身在其中的人。
半导体是AI时代真正的底层战场,算力竞赛、国产替代、先进制程、供应链重构,每一场博弈的背后,都有你看不见的产业逻辑在运转。
这些你每天都在看的词,背后真实的逻辑是什么?我想把我在决策层和投研端看到的那些,系统地讲给你听。

