自回归(Autoregressive, AR)范式长期主导着自然语言处理(NLP)领域的文本生成,其底层逻辑基于马尔可夫文本序列的条件概率接力。这种范式通过最大似然估计(MLE)逐词(Token-by-Token)预测下一个标记,成功催生了大规模语言模型(LLMs)的繁荣。然而,自回归模型固有的从左至右(Left-to-Right)顺序生成机制在推理效率、全局语义连贯性以及非单调生成任务(如文本填补、局部编辑和全局重组)中暴露出根本性局限。为了打破这一顺序偏置,扩散模型(Diffusion Models)被引入语言建模领域,开启了并行生成、分层逻辑规划与灵活控制的新路径。
其中,连续潜在扩散语言模型(Continuous Latent Diffusion Language Models, CLDLMs)代表了当前该领域的最前沿演进。通过将离散的文本标记映射到连续的潜在空间(Continuous Latent Space),并在该空间中执行扩散与去噪过程,这类模型成功剥离了全局语义规划与局部文本实现的过程。本报告将对连续潜在扩散语言模型的过去探索、当前核心架构、深层数学机制、优化策略以及未来发展轨迹进行严密、详尽且客观的系统性剖析。
一、 连续文本扩散的早期探索与理论基础
文本数据的天然离散性是扩散模型在自然语言处理中落地的初始技术壁垒。在图像等连续域中,加性高斯噪声的物理意义明确;但在离散的词汇表空间中,直接添加连续噪声会导致语义破坏。早期的文本扩散模型在离散与连续的表征域之间进行了大量试探。
1.1 离散扩散的局限性
离散扩散语言模型(Discrete DLMs)试图直接在标记空间(Token Space)定义扩散过程。早期的代表性工作如 D3PM,通过引入结构化的马尔可夫转移矩阵(Markov Transition Matrices)来扩散源数据,而非使用高斯噪声。在此框架下,模型设定了一个吸收状态(Absorbing State,通常为),在每个扩散步骤中,文本标记要么保持当前状态,要么以一定概率进入吸收状态。近期,通过分数熵(Score Entropy)将分数匹配(Score Matching)扩展到离散空间,此类模型的性能得到了一定提升。
然而,离散噪声的表达能力受到根本性限制。由于状态转移是离散的,它难以捕捉状态之间平滑过渡的细微差别,限制了模型表示渐进语义变化或对单个标记特征进行微调的能力,从而削弱了多步去噪生成的理论优势。
1.2 连续 Token 级扩散与舍入误差困境
为了利用连续扩散模型在图像领域的成熟架构,研究人员提出了连续文本扩散范式。Diffusion-LM 是该领域的开创性工作,其核心机制是通过端到端训练的词嵌入(Word Embeddings),将离散的文本序列直接映射为连续的随机向量表示 。
在给定编码器 和潜在表示 的情况下,连续扩散语言模型的损失函数被定义为标准的高斯去噪目标:
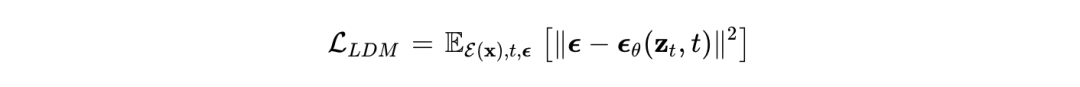
在逆向生成过程中,Diffusion-LM 将高斯向量序列迭代去噪为中间潜在变量序列,最终通过舍入(Rounding)操作,将预测的词向量映射回最接近的离散单词。基于此,后续研究进一步衍生出了 DiffuSeq 和 SeqDiffuSeq,将该架构扩展至序列到序列(Seq2Seq)的文本生成任务中。
尽管 Diffusion-LM 在句法树控制、文本长度控制等细粒度生成任务上展现了超越传统自回归微调的能力,但其实际应用受困于严重的“舍入误差”(Rounding Error)。由于直接在词嵌入级别进行连续化,目标空间缺乏足够的平滑度和拓扑结构,导致去噪后的连续向量在解码时难以精确对齐有效离散词汇,进而产生语义偏移和乱码。
1.3 替代编码方案:Analog Bits 与自条件机制
为缓解舍入误差,Chen 等人提出了 Analog Bits(位扩散)方案。该方法完全避开了词嵌入映射,利用二进制编码方案(将文本标记的索引表示为二进制比特序列,随后训练连续时间扩散模型将这些比特建模为实数(即“模拟位”)。在生成阶段,模型首先生成模拟位,通过阈值量化操作和二进制解码恢复离散的标记索引。
Analog Bits 的另一项重要贡献是引入了自条件(Self-Conditioning)机制。在去噪步骤中,模型不仅以当前时间步的噪声状态 为条件,还将前一个时间步对 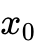 的预测结果作为附加密集条件输入。自条件机制有效引导了扩散轨迹,显著提升了生成样本的质量,使其在图像字幕生成等 NLP 任务上能够仅用 10 个扩散步骤便取得与自回归模型相近的性能。
的预测结果作为附加密集条件输入。自条件机制有效引导了扩散轨迹,显著提升了生成样本的质量,使其在图像字幕生成等 NLP 任务上能够仅用 10 个扩散步骤便取得与自回归模型相近的性能。
二、 现代连续潜在扩散架构的全面建立
早期架构表明,仅对局部词嵌入或比特序列进行连续扩散,难以支撑超大规模语言生成。现代 CLDLMs 的核心范式跃迁在于:彻底摒弃预定义的 Token 级连续代理映射,转而使用变分自编码器(VAE)学习一个高度压缩、语义对齐且平滑的全局潜在空间,并结合扩散 Transformer(DiT)与流匹配(Flow Matching)技术在该空间中进行先验传输。
2.1 文本潜在空间的重建:TextLDM 架构解析
TextLDM 的提出证明了视觉领域的连续潜在扩散配方只需进行最小的架构修改即可高效转移至文本生成领域,向多模态统一扩散架构迈出了实质性一步。该模型摒弃了依赖庞大预训练编码器/解码器的传统做法,系统由两个核心模块串联构成:
首先是 TextVAE 模块。该模块使用标准的 Transformer 编码器将离散的 Token 序列 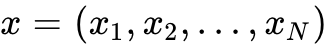 映射为连续的潜在变量,并通过 KL 散度进行正则化。解码器则通过交叉熵损失从潜在变量重构文本。
映射为连续的潜在变量,并通过 KL 散度进行正则化。解码器则通过交叉熵损失从潜在变量重构文本。
其次是 TextDiT 模块。在完成 TextVAE 的训练并冻结其编码器后,模型在学习到的潜在空间中训练一个架构上与视觉版本无异的扩散 Transformer(DiT)。模型将干净的上下文潜在变量与带噪的目标潜在变量拼接作为输入,预测速度场以进行条件去噪。
TextLDM 团队在系统实验中对模型配置进行了细致的消融研究。在 TextVAE 的设计上,实验涵盖了 350M、502M 和 690M 三种参数规模,潜在通道维度 设定为 64、128 或 192。实证数据显示,在 OpenWebText2 数据集上从头训练的 TextLDM(328M DiT)成功克服了早期模型保真度不足的问题,并在相同的训练设置下,其生成质量和收敛轨迹完全匹敌甚至超越了经过复现的 GPT-2(459M 参数,因适配 Qwen3 分词器导致词汇表增大)。
2.2 追求极致压缩与推理加速:Cosmos 模型
由于文本 Token 级表示的高维属性极大阻碍了扩散模型的计算并行性和生成效率,Cosmos 模型专注于构建一个定制化的高效压缩平滑潜在空间。
Cosmos 的设计核心是一个联合优化的自编码器。其压缩模块(Compressor)的注意力复杂度与序列长度呈线性关系(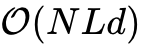 ),而解压模块(Decompressor)的注意力复杂度与序列长度呈二次方关系(
),而解压模块(Decompressor)的注意力复杂度与序列长度呈二次方关系(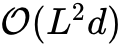 ),其中 代表输入序列长度, 代表潜在变量数量, 为潜在维度。
),其中 代表输入序列长度, 代表潜在变量数量, 为潜在维度。
通过这种非对称架构设计,Cosmos 成功将文本表示在潜在空间中压缩了 8 倍(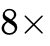 Compression)。实验评估表明,这种压缩并未牺牲生成保真度;相反,更长的潜在序列允许 Cosmos 在故事生成、问题生成、文本摘要和去毒化(Detoxification)等四项生成任务上超越传统的 Token 级扩散基线。与处理未压缩完整文本表示的基线模型 TEncDM 相比,Cosmos 在困惑度(Perplexity)指标上实现了近乎四倍的下降(55.0 对比 228.3),同时提供了超过两倍的推理加速。
Compression)。实验评估表明,这种压缩并未牺牲生成保真度;相反,更长的潜在序列允许 Cosmos 在故事生成、问题生成、文本摘要和去毒化(Detoxification)等四项生成任务上超越传统的 Token 级扩散基线。与处理未压缩完整文本表示的基线模型 TEncDM 相比,Cosmos 在困惑度(Perplexity)指标上实现了近乎四倍的下降(55.0 对比 228.3),同时提供了超过两倍的推理加速。
2.3 分层信息解耦与块因果扩散:Cola DLM 模型
由字节跳动 Seed 团队开源的 Cola DLM(Continuous Latent Diffusion Language Model)代表了当前连续潜在扩散语言模型的最高技术集成之一。其根本理论创新在于通过“分层信息解耦”(Hierarchical Information Decomposition)重构文本生成流程:语言模型不再局限于左到右的词语拼接,而是首先在连续高维空间中组织全局语义轮廓,然后再将其实现为具体的离散词汇。
Cola DLM 的核心由 Text VAE 和块因果 DiT(Block-Causal DiT)两部分组成。在其统一的马尔可夫路径视角中,扩散过程并非执行 Token 级别的观测恢复,而是执行“潜在先验传输”(Latent Prior Transport)。其潜在变量被划分为多个块结构 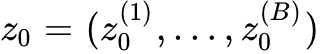 ,系统通过块因果因子分解模型来学习联合分布:
,系统通过块因果因子分解模型来学习联合分布:
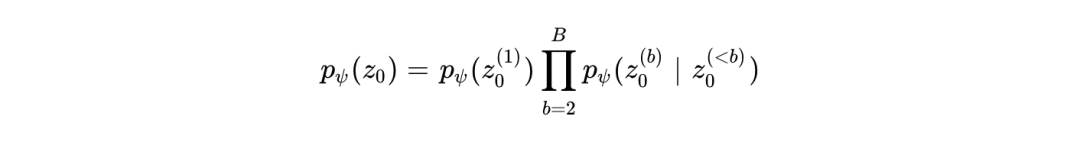
这种块级别的自回归与块内部的并行流匹配相组合的设计,既维持了文本长程依赖的因果序列特性,又极大地赋予了非自回归系统极高的采样效率和语义建模弹性。
三、 底层数学机理与物理动力学解析
现代 CLDLMs 的成功并非简单的架构堆叠,而是依赖于一系列严密的数学重构,主要集中在流匹配(Flow Matching)、整流流(Rectified Flow)积分以及变分下界(ELBO)的重构。
3.1 整流流与流匹配的积分轨迹
传统扩散模型基于随机微分方程(SDEs)或马尔可夫链的离散步长推导,其轨迹往往呈现高斯布朗运动的弯曲特性,求解缓慢且容易累积截断误差。新一代模型如 TextLDM 和 Cola DLM 全面采纳了流匹配技术。
整流流提出了一种在源分布 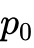 和目标分布 之间构建确定性概率路径的最简方法,即线性插值:
和目标分布 之间构建确定性概率路径的最简方法,即线性插值:
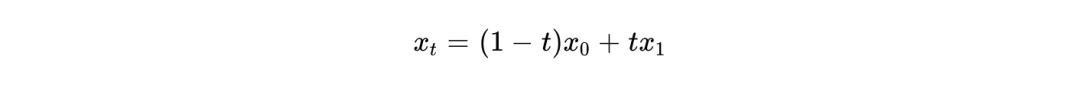
在这个线性路径下,模型在时刻 的状态 受到一个恒定的速度场(Velocity Field)驱动,该目标速度场的解析方向即为:
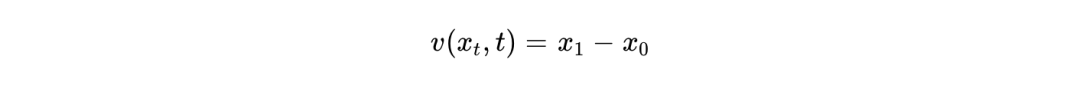
流匹配算法的核心目标是不再直接预测噪声,而是通过回归损失,训练一个参数化的神经网络 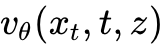 来近似真实的常微分方程(ODE)速度场。在变分整流流匹配推断算法中,系统首先从先验分布采样初始潜在状态
来近似真实的常微分方程(ODE)速度场。在变分整流流匹配推断算法中,系统首先从先验分布采样初始潜在状态 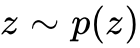 和
和  ,随后在
,随后在 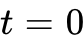 到 的区间内使用 ODE 求解器积分
到 的区间内使用 ODE 求解器积分 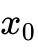 。最基础的欧拉(Euler)离散化步骤如下:
。最基础的欧拉(Euler)离散化步骤如下:
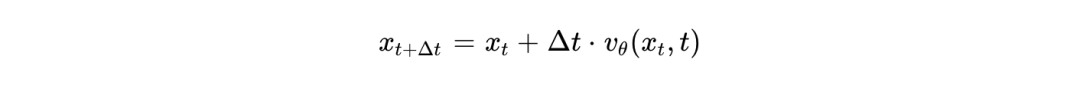
这种方法通过直线轨迹传输数据,大幅降低了 ODE 求解的刚性,允许模型在极少的采样步骤内逼近目标流形,赋予了连续潜在空间高度的平滑性和可解释性。
3.2 变分下界(ELBO)在文本模型中的重构
连续潜在扩散模型的训练可以被统一在随机路径与证据下界的联合框架内。根据信息论分解定律,对于包含连续潜在变量 和离散观测文本 的生成模型,其 ELBO 的期望可被严格分解为:
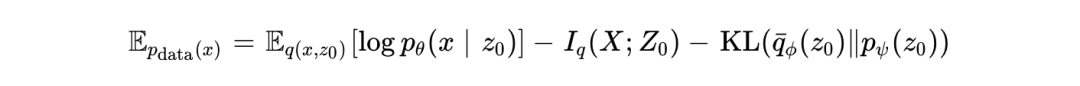
上述公式具有深刻的物理意义: 并不是离散文本的简单连续代理(Surrogate),而是一个明确被边缘化的中间变量。其中,全局语义信息被强行压缩进 中,这反映在互信息项 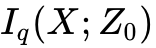 和 KL 散度约束中;而局部标记的具体物理实现,则完全委托给解码器的似然项
和 KL 散度约束中;而局部标记的具体物理实现,则完全委托给解码器的似然项 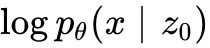 。
。
在 Cola DLM 的实际联合优化过程中,其目标函数结合了自编码约束、流匹配速度先验以及防止潜空间漂移的参考正则化:
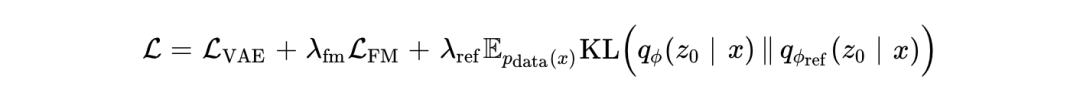
第一项保证了文本与潜在空间的双向稳定映射,第二项驱动 Block-Causal DiT 拟合先验场,第三项则确保在长时间的联合训练中,潜在流形不会发生严重的拓扑退化。
3.3 球面常微分方程与 vMF 分布路径
为了进一步提升连续文本表示在高维流形上的采样质量,有研究开始探索几何感知(Geometry-aware)的扩散路径。在处理通用棘手的条件速度积分时,利用 von Mises-Fisher (vMF) 密度的径向对称性,可以将 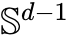 超球面上的连续性方程简化为余弦相似度上的标量 ODE。
超球面上的连续性方程简化为余弦相似度上的标量 ODE。
通过这种映射,边缘速度和 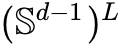 上的边缘得分均可分解为仅在单 Token 标量权重上有所不同的后验加权切线和。该数学性质不仅提供了对 ODE 采样的精确控制,还允许应用预测-校正(Predictor-Corrector, PC)采样器。实证表明,将 vMF 路径与 PC 采样结合,相比传统的欧几里得空间直线路径,显著改善了语言建模和复杂序列推理(如数独)的生成精度。
上的边缘得分均可分解为仅在单 Token 标量权重上有所不同的后验加权切线和。该数学性质不仅提供了对 ODE 采样的精确控制,还允许应用预测-校正(Predictor-Corrector, PC)采样器。实证表明,将 vMF 路径与 PC 采样结合,相比传统的欧几里得空间直线路径,显著改善了语言建模和复杂序列推理(如数独)的生成精度。
四、 潜在空间的对齐陷阱与优化策略
构建一个重构损失极低的自编码器相对容易,但该自编码器的潜在空间对扩散模型而言往往呈现出高度的非凸性与混乱。为了使潜在空间变得“可扩散”(Diffusable),研究者引入了一系列外部对齐机制与联合训练配方。
4.1 表征对齐(REPA)机制的引入
TextLDM 等模型在早期实验中发现,仅仅依靠交叉熵或 MSE 损失得出的重构保真度是远远不够的。为了获取高质量的连续文本表示,必须显式地对齐潜在特征。表征对齐(Representation Alignment, REPA)被引入文本扩散域,其核心策略是通过辅助损失,强制 VAE 或 DiT 的中间隐藏状态投影与一个冻结的外部预训练视觉或语言模型(教师模型)对齐。
在 TextLDM 中,模型选择了 Qwen3-1.7B 作为冻结的教师语言模型。研究评估了对齐该模型倒数第 1 层与倒数第 3 层的特征差异,确认倒数第 3 层的中间层表示更能提供平滑的语义梯度指导,使得提取出的表征极其适合条件去噪。类似地,在跨模态 TARFlow 架构中,研究验证了前向 REPA(F-REPA)、分离 REPA(D-REPA)以及反向 REPA(R-REPA)等不同的梯度反向传播策略,确保对齐损失能够有效穿透整个网络深度。
4.2 容量不匹配困境与 HASTE 截断干预
REPA 机制虽然极大加速了模型在早期的收敛,但随着训练的深入,往往会导致严重的性能停滞甚至退化。其根本症结在于“容量不匹配”(Capacity Mismatch):当作为学生的生成模型开始真正深入建模联合数据分布时,教师模型较低维度的嵌入和固化的注意力模式不再是“引导者”,而变成了限制学生模型表达能力的“束缚衣”。
针对这一困局,HASTE(Holistic Alignment with Stage-wise Termination for Efficient training)架构提供了一种阶段性终止对齐的系统性解决方案。HASTE 采取了两阶段调度策略:
在第一阶段,应用全局对齐损失,将教师模型的关系先验(注意力图)和语义锚点(特征投影)同步蒸馏至 DiT 的中间层,促成极速收敛。在第二阶段执行“单次终止”(One-shot Termination),一旦系统达到预设的固定迭代触发点,立即彻底停用对齐损失,释放 DiT 全部的生成容量以专注于去噪。
实证数据表明,该策略在未改变底层网络架构的前提下效果显著。以 ImageNet 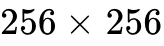 任务为例,HASTE 仅用 50 个 Epoch 便达到了 SiT-XL/2 基线模型的 FID 指标,并在该周期内匹配了标准 REPA 训练 500 个 Epoch 的最佳 FID 性能,相当于减少了 28 倍的优化计算步数,这一高效配方目前正被广泛推广至 MS-COCO 的文本到图像扩散及纯文本建模任务中。
任务为例,HASTE 仅用 50 个 Epoch 便达到了 SiT-XL/2 基线模型的 FID 指标,并在该周期内匹配了标准 REPA 训练 500 个 Epoch 的最佳 FID 性能,相当于减少了 28 倍的优化计算步数,这一高效配方目前正被广泛推广至 MS-COCO 的文本到图像扩散及纯文本建模任务中。
4.3 联合训练的动态配方(LDLM 机制)
除了借助外部教师模型,LDLM(Latent Text Diffusion Framework)提出了一种内部自洽的联合学习路径,即潜在空间与扩散模型在训练过程中共同演化,而非提前冻结自编码器。
研究表明,朴素的联合训练会产生低质量的扩散模型。为克服联合优化的不稳定性,LDLM 制定了一套严格的配方,包含四个关键组件:
MSE 解码器损失:在潜在空间提供更平滑梯度的监督信号。
扩散至编码器预热(Diffusion-to-Encoder Warmup):缓解初期 DiT 输出剧烈震荡对 VAE 潜空间的破坏。
自适应时间步采样(Adaptive Timestep Sampling):在流匹配轨迹中动态分配训练重点。
解码器输入噪声(Decoder-input Noise):增强解码器对不完美去噪潜在变量的容错鲁棒性。消融实验证实,这四个组件对最终的生成性能具有决定性影响。在 OpenWebText 和 LM1B 数据集上,LDLM 不仅实现了超越现有离散及连续扩散语言模型的生成质量,且其推理速度提升了 2 至 13 倍,确立了动态潜空间联合优化在文本生成领域的可行性。对于 Cola DLM 而言,其实验同样证明了完全冻结 VAE 会限制性能天花板,而持续的 VAE-DiT 联合协适应(Co-adaptation)是实现规模化扩展的关键。
五、 模型实证评估与对照分析
为了验证连续潜在扩散架构的绝对竞争力,必须将其置于统一的基准测试下与当代最强的自回归模型及离散掩码扩散模型进行对照。
5.1 零样本与少样本生成基准对比(Cola DLM)
字节跳动的 Cola DLM 在其实验中采取了极其严格的对齐比对标准:将 Cola DLM(约 500M 参数的 VAE + 1.8B 参数的 DiT,总参数量约 2.3B)与同样维持 1.8B 非嵌入主干、总参数 2B 的自回归(AR)基线以及 LLaDA(离散掩码扩散)基线进行测试。所有模型在扩展至 2000 EFLOPs 的计算量下,采用了统一的少样本/零样本生成式评估协议。
以下为 Cola DLM 在八个主流评估任务中的零样本参考准确率表现(数据来源:官方 HuggingFace 检查点推理):
评估基准任务 | Cola DLM 准确率 (%) | 任务类型特征 |
LAMBADA | 50.80 | 长文本上下文依赖与词汇预测 |
MMLU | 19.30 | 多学科综合知识与推理 |
OBQA | 23.00 | 常识性开卷问答 |
HellaSwag | 10.70 | 情境推理与常识判断 |
RACE | 19.60 | 阅读理解(生成式选择评估) |
SIQA | 28.90 | 社会常识与因果推理 |
SQuAD | 30.90 | 抽取式阅读理解 |
Story Cloze | 30.77 | 故事连贯性与结尾预测 |
八项任务平均值 | 26.75 | 综合零样本生成能力 |
综合实验数据与 Scaling 曲线显示,基于流匹配连续潜先验建模的 Cola DLM 在多项核心指标上表现出了极具竞争力的缩放行为,在最终的平均得分上成功比肩同等规模的强 AR 和离散扩散基线。这表明,语言生成的绝对质量不再被“负对数似然”(NLL)这一单一指标所垄断,非自回归生成同样能够基于强缩放定律(Scaling Laws)实现智能涌现。
5.2 大规模离散掩码扩散(LLaDA)的对照映射
作为极具代表性的对照组,LLaDA(Large Language Diffusion with mAsking)坚持在离散词表空间操作,将规模扩展至前所未有的 8B 参数,实现了与 LLaMA3 8B 媲美的性能。
LLaDA 的原理建立在全局掩码模拟之上:在预训练期间,其以 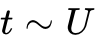 的均匀分布比例随机掩码序列中的所有 Token;在监督微调(SFT)期间,系统仅对响应 Token 进行掩码。推理时,模型从全掩码状态起步,随时间步长同步预测所有缺失掩码,并支持灵活的重新掩码操作。其进阶变体甚至整合了方差减少策略(VRPO)和混合专家(MoE)架构(LLaDA-MoE-7B-A1B-Base),在仅占用 1B 激活参数的情况下,展现了匹敌 Qwen2.5-3B-Instruct 的实力。
的均匀分布比例随机掩码序列中的所有 Token;在监督微调(SFT)期间,系统仅对响应 Token 进行掩码。推理时,模型从全掩码状态起步,随时间步长同步预测所有缺失掩码,并支持灵活的重新掩码操作。其进阶变体甚至整合了方差减少策略(VRPO)和混合专家(MoE)架构(LLaDA-MoE-7B-A1B-Base),在仅占用 1B 激活参数的情况下,展现了匹敌 Qwen2.5-3B-Instruct 的实力。
更关键的是,LLaDA 成功解决了 AR 模型固有的“反转诅咒”(Reversal Curse),在反向诗歌补全任务中超越了 GPT-4o。这一结果从侧面论证:指令遵循、上下文学习(ICL)等高阶认知能力源自生成式概率建模,而非自回归机制本身。
相比 LLaDA 直接在离散标记层面进行硬性的概率开闭,连续潜在扩散模型(如 TextLDM 和 Cola DLM)通过物理向量空间的平滑传输,在捕捉极其复杂的语法微调与渐进语义变化上,展现了更具解释性的数学结构与更柔性的容错空间。
六、 连续潜在扩散语言模型的二阶洞察与认知转向
在海量的实证数据与数学方程背后,连续潜在扩散架构的成熟预示着 NLP 领域底层认知范式的系统性更迭。
6.1 认知机制的进化:物理态语义规划的确立
传统的自回归解码本质是一场“无向后修正权限的概率盲跑”。由于生成被严格限定为依赖左侧上下文,模型必须在输出每个词的瞬间做出最终决定,这导致系统在长篇幅生成中容易陷入局部最优,难以进行跨度极大的非单调逻辑调整。
连续潜在扩散通过 VAE 映射实现了文本逻辑向高维物理流形(Manifold)的转移。在这个流形空间内,生成过程变成了全局语义轮廓的逐步显影。模型在真正产生第一个离散单词之前,已经在一个语义连续统(Semantic Continuum)内,通过双向上下文完成了对复杂语法、句法边界和文章主旨的多次迭代修正。这意味着语言模型具备了类似人类写作时的“腹稿打底”与“全局统筹”能力,离散的词汇仅仅是最终落笔的显式副产物。
6.2 训练评价体系的解构与非自回归的 Scaling 独立
长久以来,业界普遍将预测下一个词的困惑度(Perplexity)视为衡量模型智能的唯一黄金准则。然而,连续扩散语言模型的崛起彻底解构了这一迷信。
正如 Cola DLM 和 Cosmos 所展示的,生成质量、上下文理解深度和缩放行为可以直接通过优化物理概率路径(流匹配积分误差降低)来实现,而无需依赖严格的似然拟合。随着计算规模扩展至 2000 EFLOPs,模型并没有遇到架构瓶颈,反而证实了非自回归归纳偏置能够以不同于 AR 的轨迹建立起自身独立的 Scaling Laws,在非单调任务(如文本修复、逆向逻辑推演)中甚至具备更高维度的智能天花板。
七、 未来演进轨迹与技术前瞻
尽管在理论与局部任务中展现出颠覆性潜力,连续潜在扩散语言模型在迈向 AGI 的工业级部署途中,仍需在计算维度、硬件适配及多模态融合上寻求突破。
7.1 面向复杂系统的“无限推理空间”计算(Space-time Compute)
自回归模型受限于固定的前馈深度,每个 Token 的计算消耗基本恒定。而基于 ODE 连续状态解算的扩散模型天然具备“空间-无限推理”(Spatial Infinite Reasoning)属性。系统能够在推理阶段投入不设上限的计算步数,通过对同一输出序列的反复双向自纠错,提纯逻辑链条。
在高度形式化的科学发现领域,这一特性已被用于符号回归(Symbolic Regression)。例如 DiffuSR 框架,通过连续扩散语言模型底座,将离散的数学符号注入连续潜空间,结合交叉注意力机制引入数值约束,并通过遗传编程注入 Logit 先验。实验证实,其在发现复杂数学方程式时,不仅打破了庞大搜索空间的限制,更生成了极具解释性的高阶物理规律表达式。未来,模型可通过动态预估任务难度,自适应分配流匹配步数,实现计算资源对复杂系统级逻辑任务的非线性倾斜。
7.2 推理延迟的架构级终结:并行解码与 KV Cache 重塑
推理速度一直是限制扩散模型文本应用的核心痛点。Cosmos 模型虽然在算法侧通过 8 倍的极致空间压缩实现了超过两倍的推理加速,但这主要建立在减少隐层数据流吞吐的基础上。
硬件层面的架构级优化正在成为新的突破口。针对非完全平滑网络的优化算法相继问世,例如 fast-dLLM(或 Mercury 架构)等无需重新训练的加速方案,成功在扩散语言模型中激活了 KV 缓存(KV Cache)机制和并行解码管线。未来,结合 Cola DLM 的块因果(Block-causal)特性,连续模型有望在块之间复用类似 Seq2Seq 的缓存状态,而在块内部全速执行流匹配的矩阵并行运算,从而使其首字延迟(TTFT)和每秒吞吐量逼近甚至超越当前的生产级 vLLM 架构系统。
7.3 多模态不可知论:走向物理世界的统一模拟器
连续潜在扩散在 NLP 领域的彻底打通,吹响了模态大一统(Multimodal Unified Architecture)的最后集结号。TextLDM 的视觉配方迁移证实了文本与图像能在高度相近的 DiT 架构中进行平滑流匹配;英伟达发布的 Cosmos 1.0 Tokenizer(CV8x8x8)已经将 8 倍时间压缩与  空间压缩的连续自编码器范式推行至超高清视频流的潜在建模中。
空间压缩的连续自编码器范式推行至超高清视频流的潜在建模中。
这意味着,人类语言极其复杂的句法结构和修辞隐喻,已经能够被无损压缩至与图像像素流、视频帧序列、乃至机械臂动力学反馈完全相同的连续潜在矢量空间中。未来,独立类别的“大语言模型”与“视觉生成大模型”边界将逐渐消解,所有的离散与连续数据流都将在统一的整流流积分公式与去噪先验下进行高维概率建模,最终汇集为一个无视模态界限的“物理世界与人类知识通用模拟器”。