
文/交通银行深圳分行 刘云 郑伯伟 谢云
随着银行数智化转型不断深化,人工智能已不再局限于流程线上化或基础数据分析工具,而是逐步嵌入核心业务环节,开始参与风险识别、专业判断与业务决策过程。尤其是在法律审查、授信尽调等高度依赖专业经验、文本理解与人工判断的场景中,传统模式面临效率瓶颈与一致性挑战,亟需通过智能化手段实现能力重构。为此,本文聚焦于AI法审助手与授信报告助手在银行内部的落地实践,剖析两者分别对应的法律合规与授信风控关键节点。它们代表了大模型在“专业审查型场景”与“知识密集型生产场景”中的典型应用,具有较强参考价值。
AI法审助手:面向保函业务与格式合同的智能法律审查
1. 场景痛点与应用定位
法律审查是银行各类业务风险防控的核心环节,广泛存在于保函业务、对公及零售业务合同与协议审查。长期以来,这项工作主要依赖人工对文本的逐条审核。从实践情况看,一份常规保函的人工审查时间通常在30分钟至1小时之间,而对于条款复杂、责权多样的合同文本,审查往往需要耗费更长时间。同时,人工审查在面对错别字、语序异常或表述不规范等细微问题时,识别难度较大,存在一定遗漏风险。人工核查不仅效率较低,也难以及时发现潜在差异。AI法审助手的功能定位,并非替代法律判断,而是作为法审前置筛查与一致性增强工具,通过对历史法审经验的结构化复用,承担初步风险识别、相似案例匹配与文本差异校验等工作,为专业人员提供稳定、可比对的结构化参考依据。
2. 技术架构与实现机制
AI法审助手整体采用“历史文本接入—知识检索—大模型推理—人工复核”的人机协同流程(如图1),将大模型能力嵌入既有法审作业链条之中,实现对法律审查环节的智能化支持。

图1 AI法审流程
一是存量法审知识的自动化沉淀。通过RPA技术在行内系统中自动抓取历史保函、合同文本以及对应的法审意见,对文本进行分段处理并生成Embedding向量,统一存储至向量数据库,形成可检索、可复用的法律知识底座。
二是基于检索增强的大模型法审推理。采用“检索增强生成(RAG)”架构,当用户提交新的保函文本时,系统先在向量库中召回高相似度历史案例,再由大模型结合召回内容以及最新的法律法规、银行制度等进行条款风险识别与合规性判断,输出结构化的初步法审提示,降低幻觉风险。
三是多模态文本比对与差异标注。在保函生效环节,引入OCR技术对扫描件进行文本识别,并将识别结果与电子版文本输入大模型进行语义级比对。模型不仅可以识别字面差异,还可提示金额、责任条款等关键要素的语义不一致,并在界面中进行差异高亮展示。
3. 应用成效
在实际运行中,AI法审助手已从最初面向保函业务与格式合同的专项工具,逐步拓展至一般合同法审场景,适用于对合同条款合规性、责任安排合理性及关键表述一致性的初步审查。系统可基于向量检索机制,自动匹配历史相似度较高的保函或合同法审意见,辅助法审人员快速定位审查重点;在合同法审中,还可结合相关法律法规与内部制度要求,生成结构化的初审提示意见。
从效率提升效果看,引入AI法审助手后,法审工作模式由传统的“人工逐条通读”转变为“机器前置筛查与人工复核相结合”的协同模式。实践数据显示,常规保函的法审准备与核对时间显著压缩,复杂合同的初审效率提升尤为明显。总体而言,法律意见出具的平均耗时较传统模式缩短60%以上,在业务高峰期有效缓解了人力瓶颈。同时,模型在语义层面的比对能力,使错别字、语序异常及条款前后不一致等问题更易被识别,进一步降低了因人工疏忽导致的操作风险,并提升了法律审查结果的一致性与稳定性。
授信报告助手:面向尽调与放款的智能文本生成与核验
1. 场景痛点与应用定位
授信报告撰写是典型的知识密集型工作,既需要大量事实信息,又依赖成熟的分析框架与风险表述逻辑。尽管银行内部积累了大量高质量存量报告,但受制于隐私与合规要求,难以直接复用,导致重复劳动严重。此外,在放款环节,对合同、发票与系统要素的逐项人工核对,也成为效率瓶颈。授信报告助手的核心定位在于构建一个可复用、合规的授信知识生产引擎,在确保数据安全与合规要求的前提下,实现授信经验的持续沉淀与专业能力的有效补充。
2. 技术架构与实现机制
授信报告助手通过知识复用与智能核验并行运行,提升授信尽调与放款审核的整体效率(如图2)。
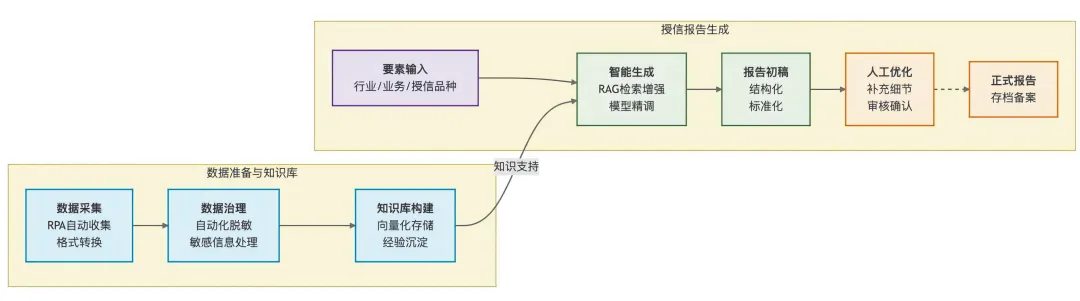
图2 授信助手流程
一是多源授信文本的结构化采集。通过RPA自动收集行内不同系统、不同格式的优秀授信报告,并借助OCR等内容识别、文本解析技术将PDF、Word、图片等统一转化为标准化文本,为后续处理奠定基础。
二是脱敏向量化与模型精调。在数据治理层面,对存量授信报告进行自动化脱敏处理,对客户身份、账户信息等敏感字段进行脱密。同时,将脱敏文本Embedding后存入向量库,并以此对大模型进行领域精调,使其学习授信报告的结构范式、行业分析逻辑与风险表述方式。
三是基于要素驱动的授信报告生成。在实际使用中,客户经理仅需输入行业、业务模式、授信品种等关键要素,系统即可在向量检索与模型生成的协同下,输出一份结构完整、逻辑规范的授信报告初稿,供人工补充与校验。
四是放款要素的智能核对。在放款审核阶段,通过OCR技术将合同、发票等资料转化为结构化数据,大模型则对关键信息进行语义级比对,自动识别金额、交易主体、日期等要素的不一致情况,辅助审核人员快速决策。
3. 应用成效
授信报告助手显著压缩了报告撰写与放款核验的时间成本,使优秀经验得以规模化复用。在实际运行中,单份授信报告的平均撰写时长明显下降,原本需要1—2天的工作,现在客户经理只需要2—3个小时即可完成,减少了大量的重复劳动,同时授信报告快速完成也进一步让放款核验环节的准确率与效率得到提升,为授信业务的规模化与标准化提供了有力支撑。
技术可复制性分析
在现有研究与实践中,人工智能在银行场景的应用多以单点案例或工具效果呈现,缺乏对“如何规模化复制、如何可控落地”的方法论总结。本文基于AI法审助手与授信报告助手的实践,进一步抽象出方法论,为银行推进大模型应用提供可复用的实施范式。
一是“专业判断前置化”的人机协同。本文案例强调将大模型前移至业务流程的前置环节,承担风险筛查、要素校验与一致性增强等工作,而最终决策仍由专业人员完成。既充分释放了人工智能在文本理解与模式识别上的效率优势,又有效避免了模型幻觉造成的风险,为高风险金融场景提供了一种稳健可控的智能化路径。
二是“检索增强+领域精调”的工程化落地范式。本文中的两个应用案例均未依赖通用大模型的端到端生成能力,而是通过向量数据库构建业务知识底座,在此基础上引入检索增强生成(RAG)机制,并结合脱敏后的领域数据进行精调。将模型能力嵌入既有业务经验与制度框架之中,使人工智能输出始终“有据可循、可被追溯”,从而显著提升结果的专业一致性与合规可解释性。
三是“数据治理先行”的设计原则。实践表明,大模型能否在银行场景中长期运行,关键不在模型本身,而在数据治理能力。本文通过对授信报告的自动化脱敏、权限隔离与向量化存储,探索出一条合规前提下实现经验复用的技术路径,证明了“先治理、后智能”是金融机构推进人工智能应用的必要前提,而非附加选项。
银行大模型应用的技术深化方向
人工智能在银行数智化转型中的发展趋势正逐步清晰。一是应用形态由单点工具走向任务级智能体。早期AI多作为辅助功能嵌入业务节点,而当前以大模型为核心的系统已具备跨步骤规划与执行能力,逐步向“端到端任务完成”演进,实现实质性减负增效。二是技术路线由模型能力转向工程体系。实践表明,单一大模型难以直接解决复杂业务问题,真正产生价值的是“LLM+RPA+OCR+向量数据库”等工程化组合,以及围绕数据治理、权限控制和审计机制构建的完整体系。三是智能化重心转向风险可控与专业一致性。在金融场景中,AI应用的关键不在于“快”,而在于“稳”。通过检索增强与领域精调,人工智能正成为专业能力的放大器。四是人机关系由替代走向共生。无论是法审还是授信场景,人工智能并非取代专业人员,而是将其从重复性劳动中解放出来,专注于更高价值的判断与决策。
(此文刊发于《金融电子化》2026年3月下半月刊)
金科焦点 • 推荐阅读












