1. 全栈自研GPU,国产算力核心
1.1. 公司拥有全功能GPU布局
摩尔线程自2020年成立以来,以全功能GPU为核心,公司致力于向全球提供计算 加速的基础设施和一站式解决方案,为各行各业的数智化转型提供强大的 AI 计算 支持。公司的目标是成为具备国际竞争力的GPU领军企业,为融合AI和数字孪生 的数智世界打造先进的计算加速平台。摩尔线程在国内GPU领域处于领先地位,基 于自主研发的MUSA架构,公司率先实现了单芯片架构同时支持AI计算加速、图 形渲染、物理仿真和科学计算、超高清视频编解码的技术突破,有力推动了我国GPU 产业的自主可控进程。
云端业务是以全功能GPU芯片为核心的算力基础设施。云端产品线目前主要包括 云端智算板卡、智算一体机以及智算集群。1)基础算力层面,云端智算板卡(如MTT S5000、MTT S4000、MTT S3000 等)作为核心计算单元,为MoE混合专家模型、 多模态模型、世界模型等前沿模型预训练及集群化推理优化设计,具备良好的计算 性能与能效比;服务器层面,智算一体机(如D800等)服务于大规模AI训练与推 理场景,通过高密度算力集成和创新散热设计,实现单节点多卡高效协同。2)集群 层面,公司智算集群(夸娥KUAE集群)可扩展至万卡及以上规模,采用先进网络 架构和调度系统,满足 AI 研发机构和企业级智能化需求,支持超大参数模型预训 练、多租户云服务与分布式推理。

边缘和终端业务是基于自研SoC的行业下游应用。边缘与终端产品线边缘与终端产 品线目前主要包括桌面图形加速显卡、专业视觉加速卡、边缘 AI 计算模组以及个 人智算终端设备。其中,1)桌面图形加速显卡与专业视觉加速卡是个人电脑、图形工作站进行高质量图形渲染与多媒体处理的核心器件。MTT S80作为国内首款支持 Windows 操作系统及DirectX 11/12图形API的消费级显卡,主要为大众用户提供流 畅的3A 游戏体验与日常娱乐计算支持;MTT X300则面向专业级市场,凭借其卓 越的实时渲染与计算能力,深度赋能GIS(地理信息系统)、CAD(计算机辅助设 计)、BIM(建筑信息模型)及非线性编辑等专业应用,解决国产终端在复杂三维 展示中性能不足的痛点。2)边缘AI计算模组主要面向机器人与边缘计算市场。该 类产品基于公司自研的“长江”SoC芯片,采用创新的模块化设计,将全功能GPU、 高性能 CPU、NPU 与 VPU 等异构算力高度集成。MTT E300 模组可提供高达 50 TOPS 的INT8边缘AI算力,可以为无人机、AI智能体终端设备、工业机器人等边 缘侧设备提供高性能、低延迟、强可靠的本地化 AI 推理与智能感知决策能力。3) 在个人智算领域,公司推出了以MTT AIBOOK为代表的系列个人智算终端设备。 该产品搭载自研“长江”SoC芯片,通过集成全功能GPU算力核心,实现了办公应 用与AI计算任务的异构协同。依托内置的MT AIOS操作系统及配套AI开发工具 链,该终端支持端侧大模型及智能体的本地化部署与运行。4)在技术实现层面,针 对主流智能体框架,公司通过优化底层推理引擎与内存管理机制,提升了硬件对多 步推理、长文本处理及实时交互任务的响应速度。同时,公司通过提供标准化的软 硬协同部署接口,简化了模型量化、环境配置及接口调用流程,降低了开发者的使 用门槛。该方案在保障数据隐私安全的同时,有效支持了端侧智能体的应用开发, 进一步拓展了公司全功能GPU在个人终端及边缘计算场景的应用边界。

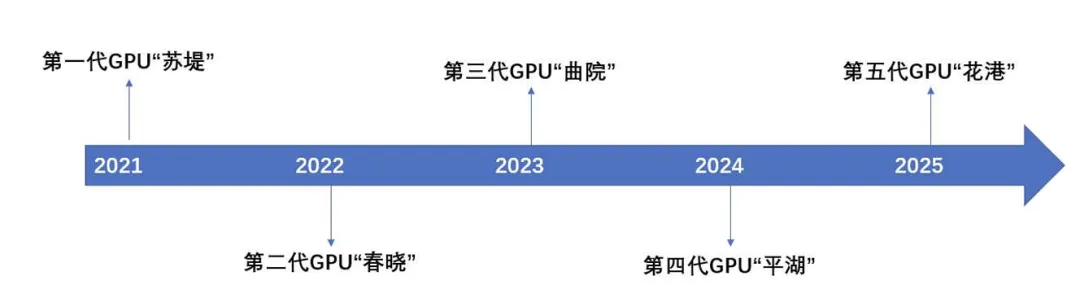
公司 GPU 芯片已更新至第五代。截止 2025 年年报,基于自主研发的 MUSA 架构,公司目前已推出五代 GPU 架构芯片。
1.2. 股权结构集中稳固,核心团队与产业资本深度绑定
实控人集中控股,团队利益深度绑定。摩尔线程股权结构稳定清晰,公司由创始人 张建中担任实际控制人,通过直接持股并联合多家员工持股平台形成一致行动关系, 合计掌控较高表决权,对公司经营战略与重大决策具备主导能力。前十大股东汇集 头部私募、产业基金及国资背景资本,机构股东阵容雄厚;同时设置多家员工持股 平台深度绑定核心技术与管理团队,利益协同机制完善。整体股权架构呈现实控人 集权稳固、核心团队深度绑定、专业机构与产业资本加持的特点,治理结构成熟, 为公司全功能 GPU 研发及全栈 AI 业务长远发展提供坚实治理保障。
深耕英伟达产业积淀,高管团队引领国产算力突破。摩尔线程高管团队兼具国际巨 头深耕背景与本土产业实战经验,核心成员多源自英伟达关键岗位,形成 “战略 - 技术 - 市场 - 运营” 高度互补的豪华阵容。创始人张建中拥有 30 余年科技行业 履历,曾任英伟达全球副总裁,深度主导中国区业务,凭借丰富的行业资源与战略 眼光掌舵公司全功能 GPU 研发与生态布局;联合创始人张钰勃、杨上山等核心技 术骨干均为前英伟达 GPU 架构师,主导 MUSA 统一架构研发与四代芯片迭代, 保障技术自研与产品快速落地能力;周苑、王东等高管则在市场生态搭建与政企客 户拓展方面经验深厚,助力公司快速构建产业链协同与商业化落地体系。整体团队稳定性强、利益绑定紧密,兼具技术攻坚硬实力与产业资源整合软实力,为摩尔线 程在国产 GPU 赛道实现技术突破与生态崛起提供核心人才保障。
1.3. 营收增长强劲,加速扭亏
营收大增,得益于全功能GPU产品实现规模化商业落地,市场渗透加速。2025年 公司实现营业收入15.06亿元,同比增长243.37%,云端产品线贡献14.61亿元,占 总收入97%,带动毛利率达65.57%,毛利规模9.87亿元,虽受原材料成本激增影 响毛利率小幅承压,但高价值产品结构支撑强劲技术溢价能力;摩尔线程2026年第 一季度实现营业收入7.38亿元,同比大幅增长155.35%,主要得益于全功能GPU产 品实现规模化商业落地,市场渗透加速。
盈利能力加速修复,2026Q1首次实现单季度盈利。2025年度公司净利润亏损收窄 至-10.01 亿元,同比收窄 38.16%,扣除股份支付后净亏损为-6.48 亿元,同比收窄 56.65%,经营效率显著优化,叠加IPO募资超75亿元,为持续研发与产能扩张提 供坚实资本保障;2026年一季度,伴随收入端强劲增长,公司归属于上市公司股东 的净利润由上年同期-1.12亿元扭亏为盈,达2936万元,基本每股收益由-0.28元升 至0.06 元,加权平均净资产收益率提升2.79个百分点至0.26%,显示盈利能力实质 性改善。公司扣除非经常性损益后的净利润仍为-5428 万元,表明主业尚未实现完 全盈利,盈利改善主要依赖7006万元政府补助及1333万元金融资产公允价值变动 等非经常性收益支撑。我们认为公司 2026 年 Q1 实现成立以来首次单季度盈利, 归母净利润转正或预示公司进入业绩拐点期。
AI 智算或为后续核心主力,云边场景搭建完善全栈业务版图。2022-2024 年,摩尔 线程主营业务按产品划分为 AI 智算产品、专业图形加速产品、桌面图形加速产品 及智能 SoC 产品四大类。2022 年营收规模较小,以专业图形加速与桌面图形加速 产品为主;2023 年营收结构相近、规模小幅增长;2024 年 AI 智算产品收入 3.36 亿元、占总营收 77.54%,成为第一大收入来源,专业图形加速、桌面图形加速及 SoC 产品合计占比约 22.46%。2025 年公司调整主营业务分类口径,按应用场景分 为云终端产品、边缘与终端产品及其他业务:其中云终端产品(对应原 AI 智算及 部分企业级图形业务)实现收入 14.61 亿元,占总营收 97.04%;边缘与终端产品 (涵盖原桌面图形、智能 SoC 及边缘计算板卡等)收入 0.26 亿元,占比 1.69%; 其他业务收入0.19亿元,占比 1.27%;公司采用直销与经销并存的销售模式,内部 设有专门的销售团队同客户进行及时接洽,并通过经销商网络扩大客户覆盖。报告 期内,直销收入的占比为72.86%,经销收入的占比为27.14%。
研发投入维持高位强度不减,高研发人才储备筑牢技术壁垒。2023-2026Q1,摩尔线 程持续维持高强度研发投入,2023-2024 年研发费用分别为 13.34 亿元、13.59 亿 元,累计超 38 亿元;2025 年研发费用 13.05 亿元,占营收 86.68%;2026Q1 研 发投入 3.69 亿元,同比增长约 50%,占营收比例降至 50% 左右,主要系营收增 速更快。研发费用率自 2022 年的 2422.51% 逐年回落至 2025 年的 86.68%,但绝 对投入规模始终保持高位,重点用于 MUSA 架构迭代、AI 智算芯片及软件生态建 设。截至 2025 年末,公司研发人员达 1009 人,占员工总数 79.20%,其中硕士及 以上学历占比超 77%,高学历人才密集,为全栈技术攻坚与产品快速迭代提供核心 支撑。 各项费用率持续下行优化,营收放量摊薄成本凸显规模效应。2025 年及 2026 年 Q1,摩尔线程营收规模快速扩张,各项费用率均呈现明显下行趋势,规模摊薄效应 突出。研发费用率 2025 年为86.68%,2026 年 Q1 回落至50.00%,公司始终保持 高额研发绝对投入,支撑芯片架构与 AI 智算产品迭代升级;销售费用率 2025 年 15.44%、2026 年 Q1 约 10.36%,渠道与市场投放效率持续优化;管理费用率 2025 年25.57%、2026 年 Q1 约 9.91%,内部运营管理精细化程度不断提升;财务费用 率维持低位小幅波动,对整体盈利扰动有限。各项费用率同步走低带动综合费用率 明显下行,费用结构持续改善,叠加产品结构升级,有力推动公司亏损持续收窄并 在 2026 年 Q1 实现单季度盈利拐点。
1.4. 26Q1存货及应收账款大增,出货预期明确
截至 2026 年一季度末,摩尔线程应收账款达 6.38 亿元,较 2025 年末的 4.34 亿 元增长 47.0%,主要系营收规模扩张、信用销售占比提升所致;存货余额攀升至 21.95 亿元,较 2025 年末的 13.32 亿元大增 64.8%,显著高于营收增速,体现公 司为匹配下游算力需求而实施的主动备货策略。应收账款与存货双双创下历史新高, 我们认为这并非经营压力的体现,而是公司对 2026 年出货节奏与订单落地具备强 信心的直接印证,后续随着智算集群等核心业务持续放量,资产周转效率有望进一 步优化,业绩增长动能充足。
2. AI高速发展催生算力需求激增,国产GPU正当时
2.1. 双重因素共振,国产替代崛起
2.1.1. 国外地缘倒逼,国内政策加持
国际地缘政治格局的演变与国内利好政策的双重加持,推动人工智能芯片领域的国 产替代进程不断提速。地缘政治因素倒逼国内相关客户转向国产 GPU 产品,这在 一定程度上助力国产 GPU 厂商与本土客户、供应商构建紧密的合作关系,进而推动自身技术与产品的快速迭代升级。相关出口管制政策势必会造成市场供给缺口, 下游智算中心的采购需求有望向国产厂商倾斜,国产 GPU 企业将迎来发展契机。 同时,国家和各级地方政府不断通过产业政策、税收优惠政策、成立产业基金等方 式支持人工智能和集成电路产业发展,有望带动行业技术水平和市场需求不断提升, 加速国产替代进程。
2.1.2. AI高速发展,算力为基
生成式人工智能AIGC涌现,推动算力硬件资源发展。随着技术的不断进步和市场 的日益成熟,AIGC产业在全球范围内呈现出迅猛发展的态势。以ChatGPT、Deepseek 等为代表的大模型人工智能技术浪潮席卷全球,国内互联网巨头、人工智能领域的 领军企业、顶尖高校及科研机构纷纷投入类似ChatGPT乃至功能更强大的大模型研 发中。随着AIGC与互联网、大数据、实体经济等领域的深度融合,以及多模态生 成式模型的不断发展,AI技术的应用正迅速释放到工业、医疗、教育等多个领域。 人工智能正在迎来快速发展的黄金时期,受益于数据资源的不断丰富、算力硬件资源的需求增长以及大模型技术的突破发展,根据艾瑞咨询的预测,中国AIGC产业 规模将持续增长。2028年,我国AIGC产业规模预计将达到7,202亿元,到 2030年 有望突破万亿元,2023-2028年,中国AIGC产业规模的年均复合增速达115.06%。
算力发展由 “主权” 阶段进阶至 “平权” 阶段,Scaling Law 的赋能将助推 GPU 产业迎来全面的放量增长。伴随人工智能技术的持续突破,DeepSeek 的横空出世掀 起了新一轮人工智能发展浪潮,DeepSeek 通过算法层面的深度优化,大幅降低了模 型训练与推理的成本;同时凭借开源模式,推动行业格局从 “算力主权” 向 “算 力平权” 演进。尽管短期内,训练效率的提升可能会对 GPU 芯片市场造成一定影 响,但在杰文斯悖论的作用下,大模型的快速迭代以及 AI 应用的巨大增长潜力, 将为 GPU 行业的长期发展注入强劲动力。 Scaling Law 是人工智能训练的基石和载体,驱动 GPU 需求持续增长。1)预训练 阶段:Scaling Law 是大模型发展的核心遵循,其核心逻辑在于:模型参数、训练数 据、计算资源这三大要素的增长,能够直接转化为模型智能水平的跃升。在通用基 础大模型的攻坚期,模型参数向着更大量级演进,预训练数据量呈指数级增长,GPU 作为算力核心硬件,顺势在预训练赛道实现爆发式增长。中国信通院《中国算力发 展白皮书(2023)》的统计数据显示,GPT-3 参数规模约 1746 亿,GPT-4 则达到 1.8 万亿,算力需求增幅高达 68 倍。DeepSeek 的开源举措,将进一步驱动头部大 模型厂商加速拓展通用基础大模型的能力边界。xAI 旗下 Grok-3 采用 20 万卡训 练集群实现性能突破,更是直观证明了预训练 Scaling Law 对人工智能发展的长期 基石作用。作为 AI 算法的源头与基础设施的底座,预训练直接决定了通用基础大 模型的智能上限。另一方面,在文本大模型生态日趋繁荣的背景下,多模态大模型 (涵盖图像、视频等领域)正迎来发展黄金期。这类模型对数据规模和结构复杂度 的要求更高,将持续催生新的算力需求。2)后训练:依托通用基础大模型的坚实底 座,全球人工智能算法已迈入全新发展阶段 —— 聚焦提升模型在垂直场景的适配性与智能表现。2024 年 9 月,OpenAI 首次公开提出将强化学习(RL)应用于大 模型后训练环节,成功实现模型以思维链(CoT)模式开展推理;而 DeepSeek 则 在预训练模型的基础上,创新性采用 GRPO 算法完成大规模强化学习训练并取得 显著成效。后训练阶段的算法技术突破,为后训练 Scaling Law 的落地奠定了核心 基础。3)推理:高性能、低成本且开源的轻量化模型持续涌现,将大幅拉低模型调 用门槛,推动海量 AI 终端应用加速落地。AI 终端的爆发式增长,会进一步催生更 多训练与推理算力需求,反哺人工智能产业形成良性循环的发展态势。在推理阶段 的 Test-time Scaling Law 作用下,大模型将逐渐成为人工智能时代的基础性可用资 源,其稀缺属性会不断弱化,商品化特征则日益凸显。我们认为,算法创新持续降 低人工智能技术的使用门槛,模型发展重心正逐步从预训练阶段向后训练、推理阶 段转移,更多中小企业得以便捷获取先进技术,积极投身 AI 应用开发与产业转型。 全新的 Scaling Law 将逐步落地生效,为整体算力需求的持续增长提供强劲支撑。
2.2. 集成电路市场持续高景气
报告全文可扫描下方图片二维码进入星球社群查阅下载

(报告来源:东北证券。本文仅供参考,不代表我们的任何投资建议。如需使用相关信息,请参阅报告原文。)