
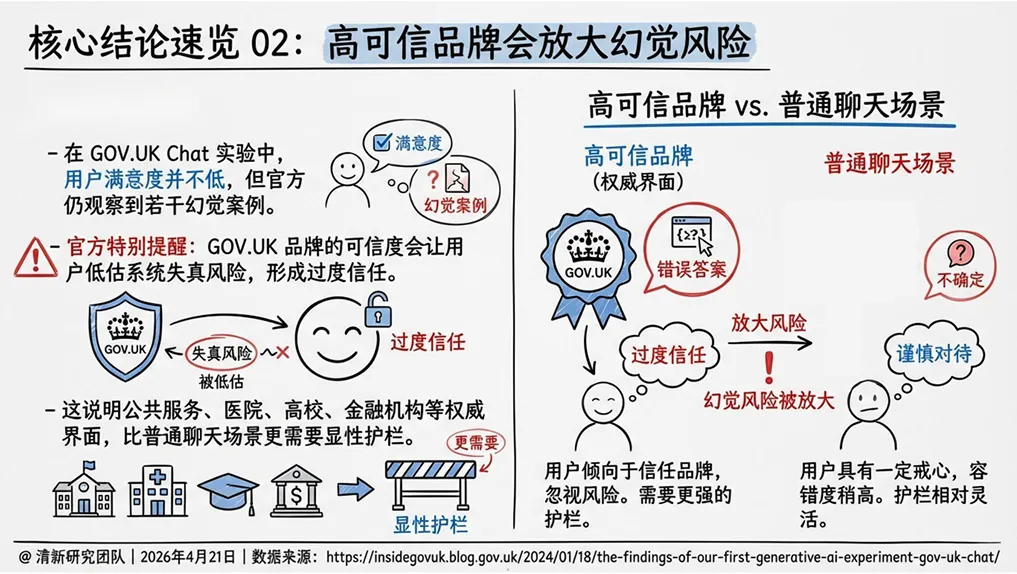
2025年,英国政府推出了GOV.UK Chat——一个基于AI的政府信息问答系统。近70%的用户认为回答“有用”,满意度不低。但官方同时观察到若干幻觉案例,并特别警告:GOV.UK品牌的可信度,会让用户低估系统失真风险,形成“过度信任”。
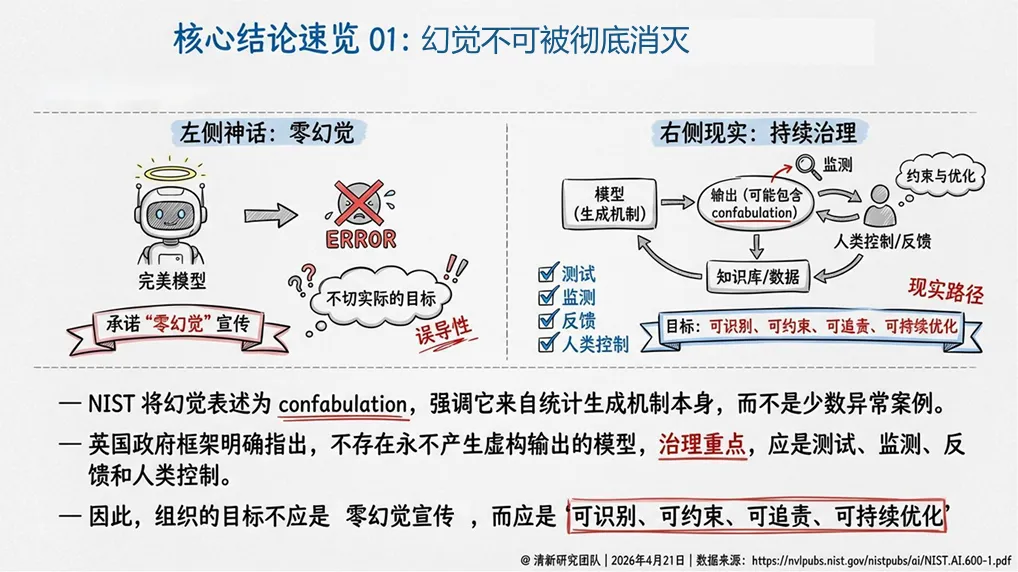
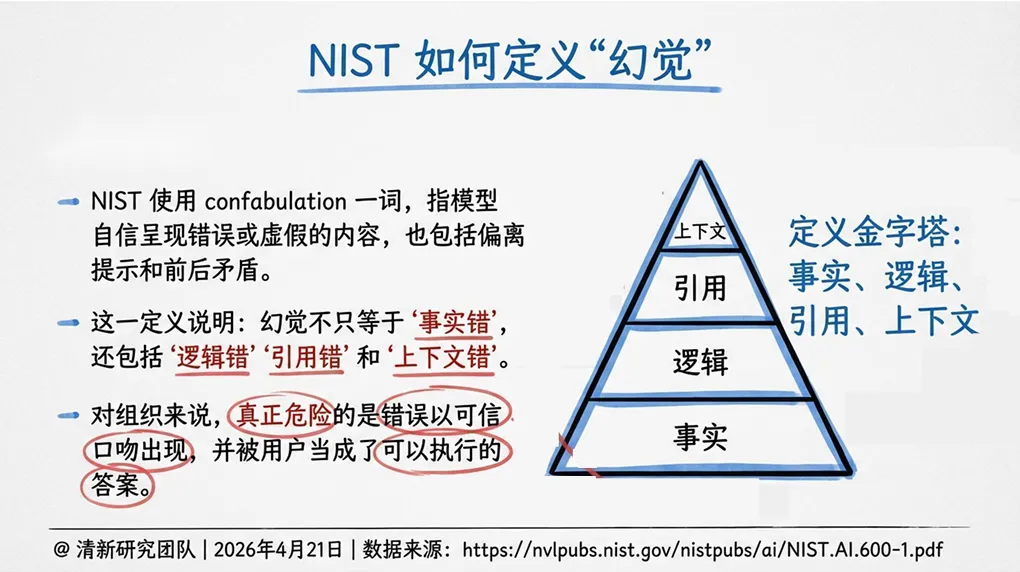
清华大学最新发布的《2026年AI幻觉深度研究报告》指出,幻觉不是单点准确率问题,而是“生成—采信—执行”链条上的系统性风险。NIST的定义也提醒我们:幻觉不只等于“事实错”,还包括“逻辑错”“引用错”和“上下文错”。真正危险的是,错误以“可信口吻”出现,并被用户当成了“可以执行的答案”。
这份报告基于政府与监管来源核验,系统分析了幻觉的定义、类型、根因、真实世界案例、治理框架与抑制幻觉工程。
本文将从风险本质、六大类型、五大根因、治理工程四个维度拆解内容,回答几个关键问题:为什么模型“说错”比“不说”更危险?为什么“拒答”反而是一种核心能力?为什么传统基准测试无法衡量真实风险?
核心判断:
幻觉是“系统性风险”,不是“准确率问题”
报告开篇给出了三个总判断,贯穿全文。
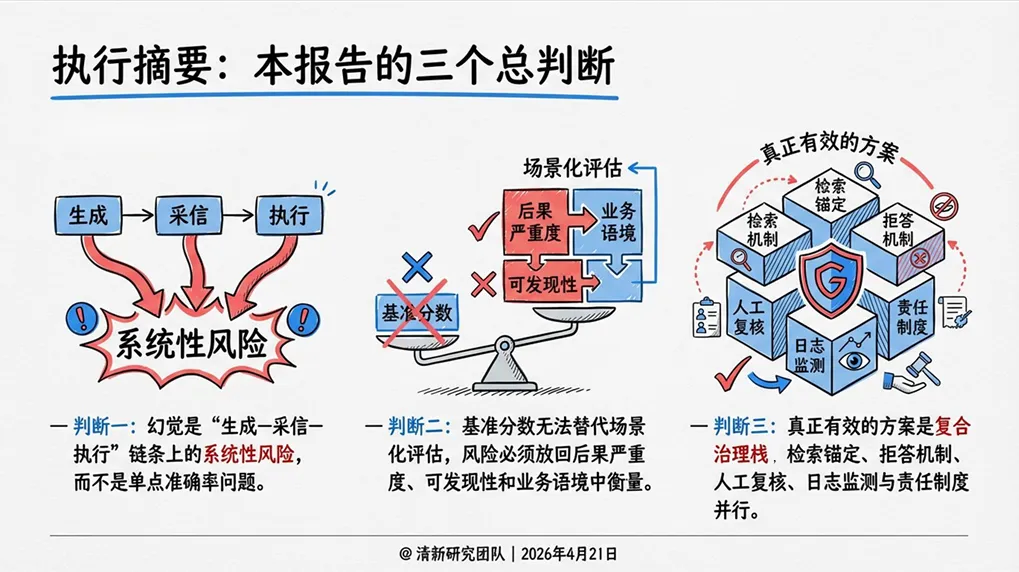
1. 判断一:幻觉是“生成—采信—执行”链条上的系统性风险
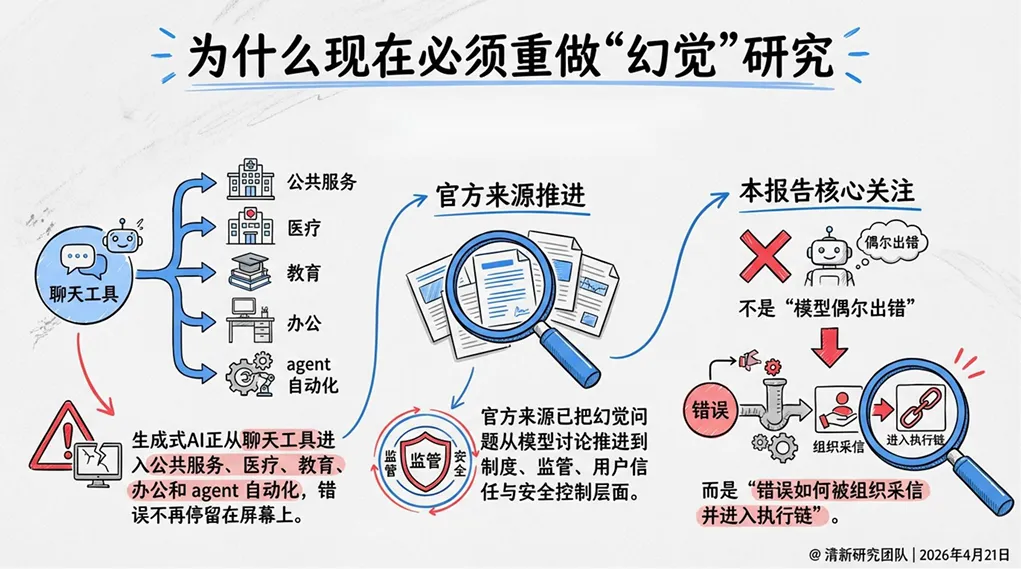
幻觉不只是模型输出了一句错话。真正危险的是:模型以自信口吻输出错误信息→用户基于权威界面(政府、医院、高校、金融机构)的信任采信了它→组织将其作为决策依据或执行指令。一旦错误进入流程,修正成本将指数级放大。
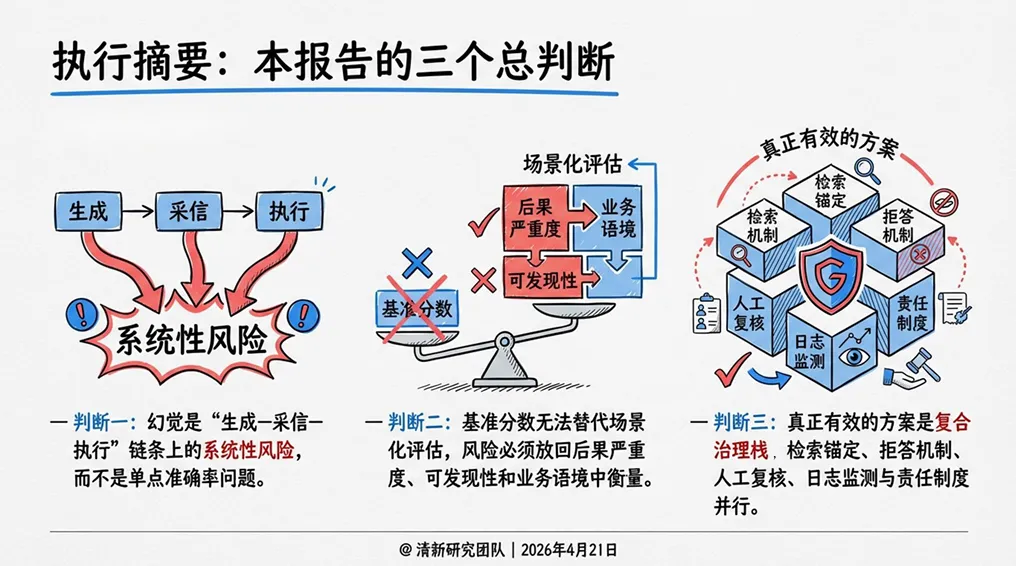
2. 判断二:基准分数无法替代场景化评估
一个模型在MMLU、GSM8K等榜单上得分再高,也不等于它在你的业务场景中可靠。NIST明确指出,实验室测试和真实世界使用之间存在显著测量缺口——离线基准无法完整覆盖提示模糊、信息更新、长链任务和用户多样性带来的风险。真正重要的不是单一榜单分数,而是具体业务语境下的持续评估。
3. 判断三:真正有效的方案是“复合治理栈”
没有单一技术能彻底消灭幻觉。真正有效的方案是:检索锚定+拒答机制+人工复核+日志监测+责任制度并行。六层治理栈共同构成控制链,而不是指望某个“万能模型”。
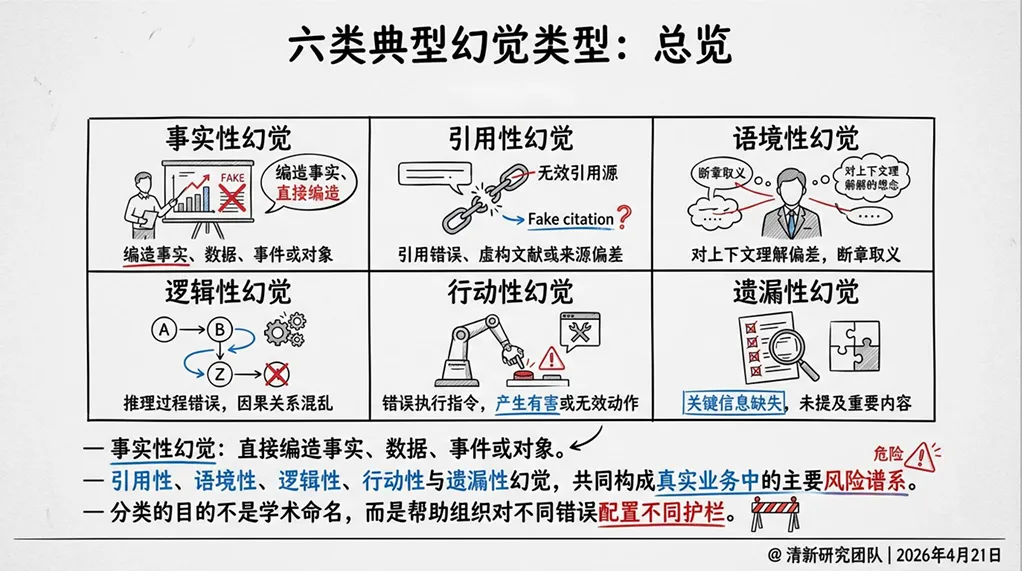
幻觉的六种类型:不只“事实错”
报告将幻觉细分为六种类型,每一种的治理逻辑都不同。
1. 事实性幻觉
最常被讨论的类型:模型陈述了与客观事实不符的内容。例如回答“北京的首都是天津”。这类幻觉相对容易被发现,但也最容易被品牌信任所掩盖。
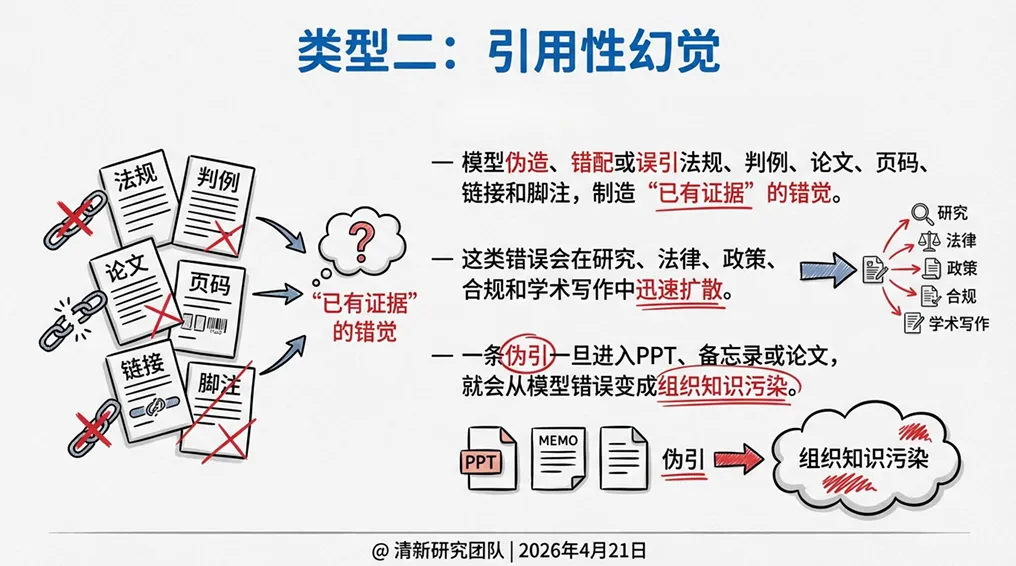
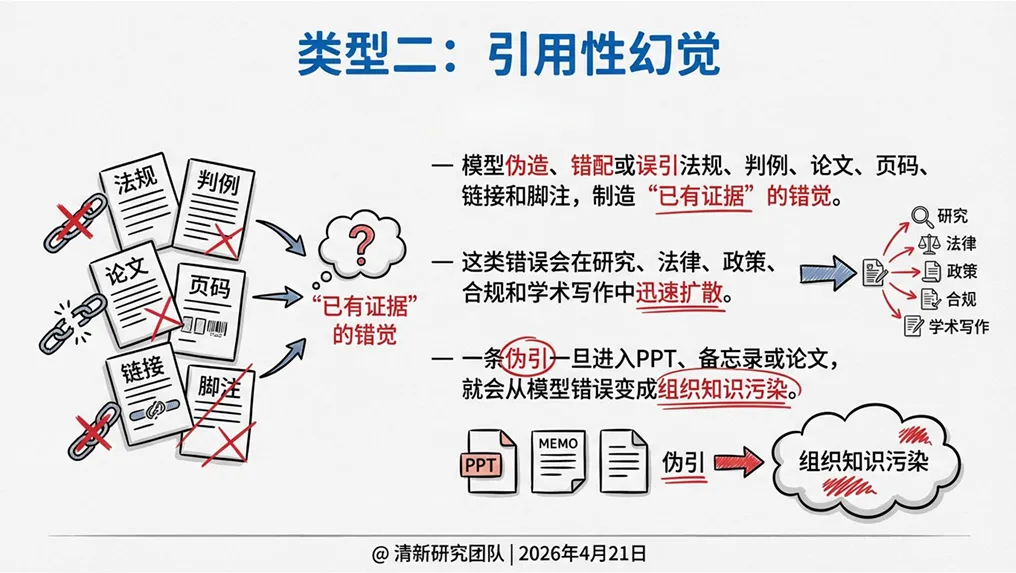
2. 引用性幻觉
模型伪造、错配或误引法规、判例、论文、页码、链接和脚注,制造“已有证据”的错觉。这是学术写作、法律文书和政策研究中“最危险”的幻觉——一条伪引一旦进入PPT、备忘录或论文,就会从模型错误变成组织知识污染,并在后续传播中被反复引用。
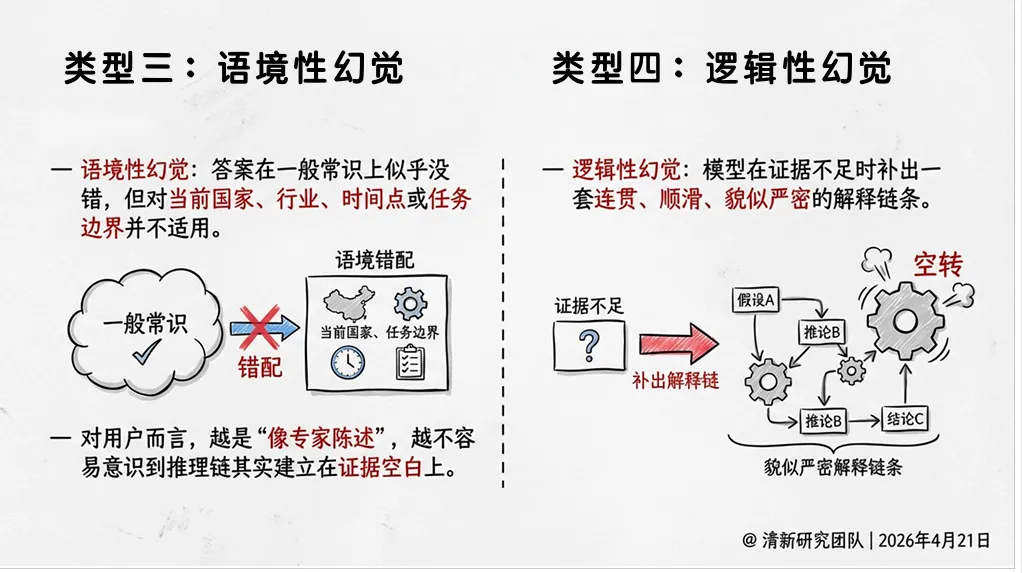
3. 语境性幻觉
答案在一般常识上似乎没错,但对当前国家、行业、时间点或任务边界并不适用。例如,模型给出了一份适用于美国的医疗指南,用户却在中国的医院里照着执行。对用户而言,越是“像专家陈述”,越不容易意识到推理链其实建立在证据空白上。
4. 逻辑性幻觉
模型在证据不足时,补出一套连贯、顺滑、貌似严密的解释链条。这种幻觉最隐蔽——因为它的内部逻辑自洽,用户很难发现起点就是错的。
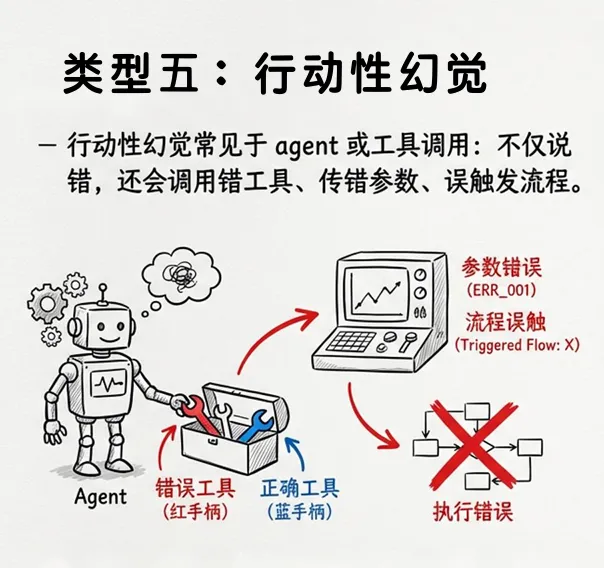
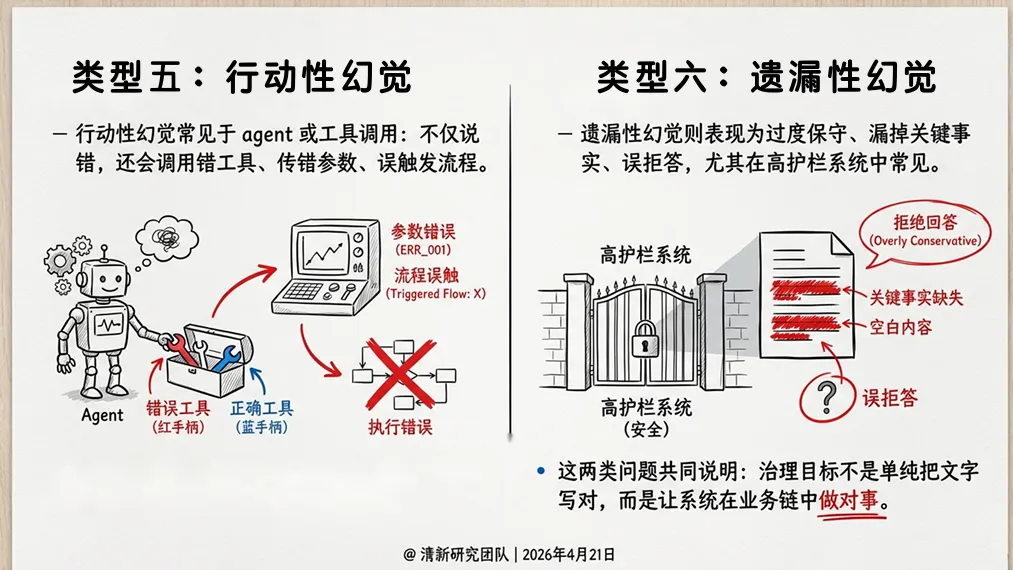
5. 行动性幻觉
常见于Agent或工具调用场景:不仅说错,还会调用错工具、传错参数、误触发流程。例如,模型在回答“帮我查一下账户余额”时,错误调用了转账接口。当模型能调用工具时,“说错”和“做错”之间的距离大幅缩短。
6. 遗漏性幻觉
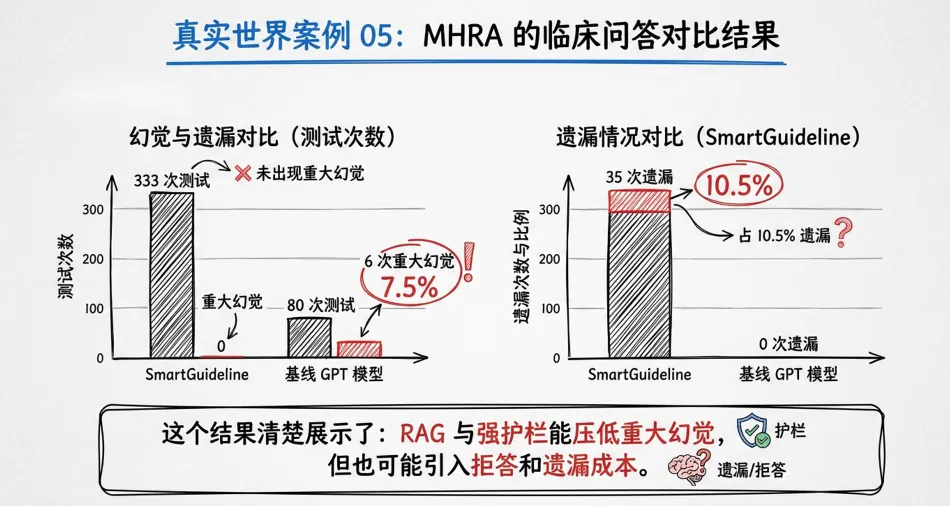
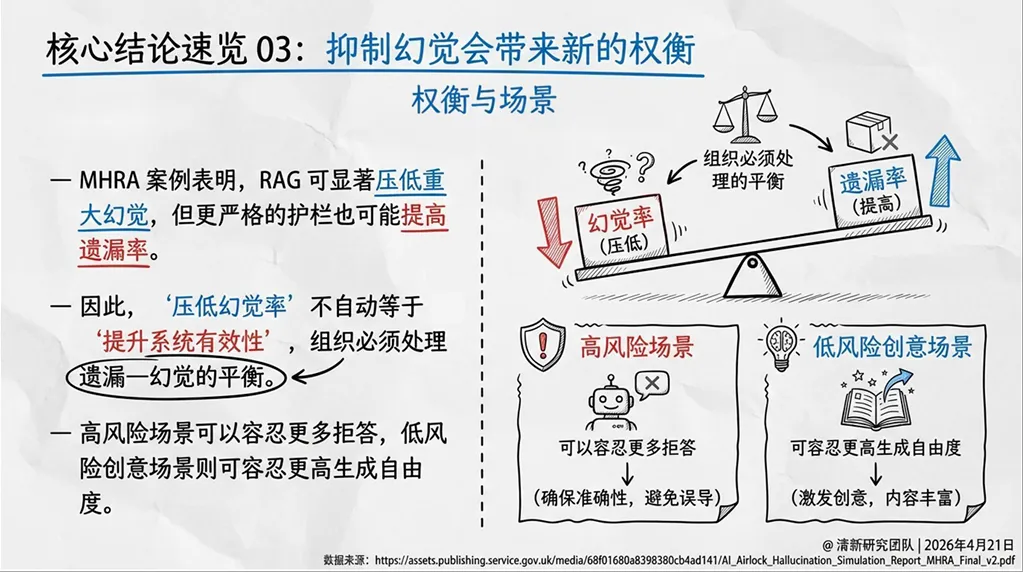
过度保守、漏掉关键事实、误拒答——尤其在高护栏系统中常见。报告引用的MHRA临床问答实验清楚展示了这一点:RAG与强护栏能压低重大幻觉,但也会提高拒答率和遗漏成本。“压低幻觉率”不自动等于“提升系统有效性”,组织必须处理“遗漏—幻觉”的平衡。
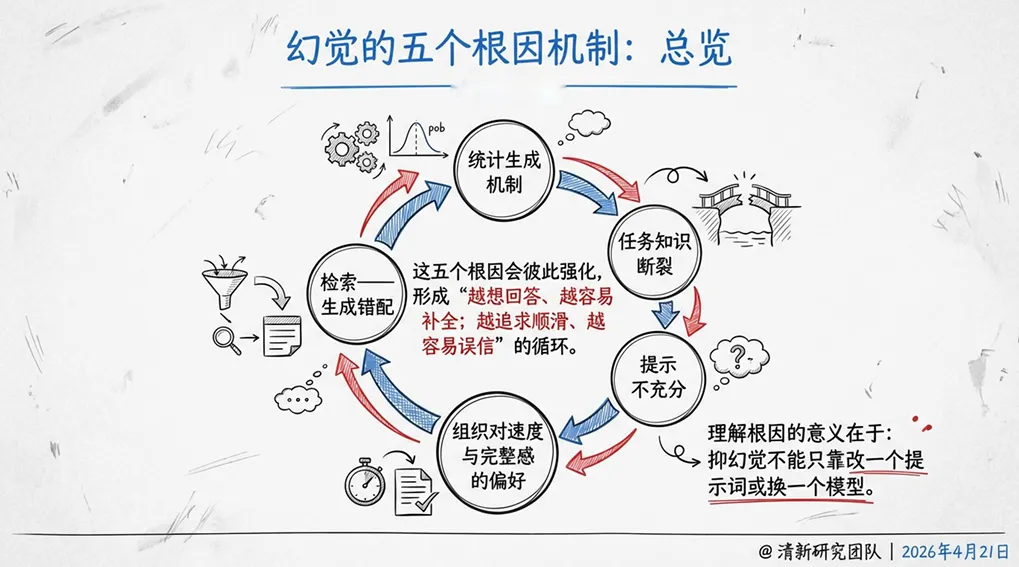
五大根因:为什么模型会“乱说”
报告将幻觉的根源归结为五个层面,从算法机制到组织管理。
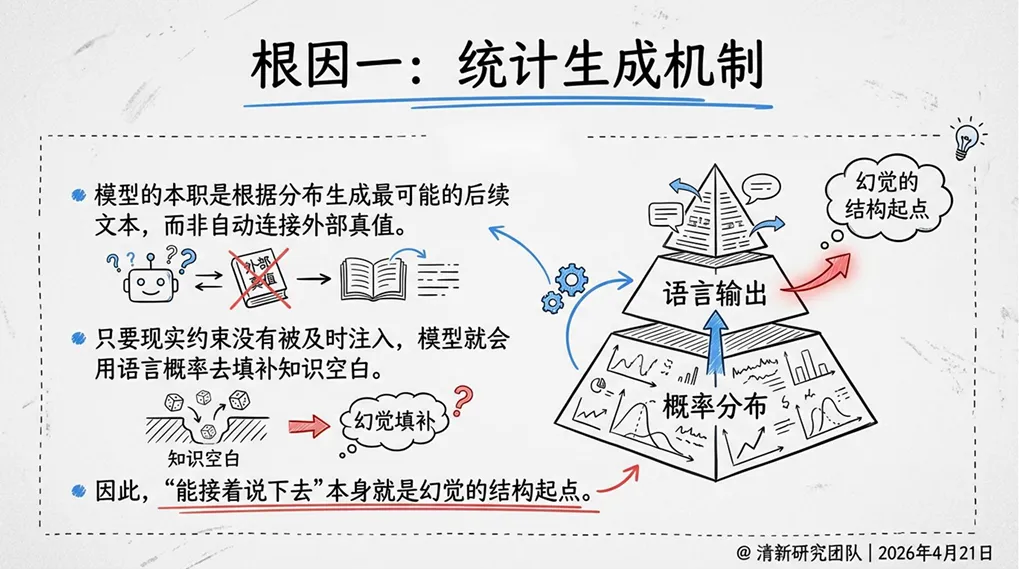
1. 统计生成机制
大模型的本质是根据分布生成“最可能”的后续文本,而非自动连接外部真值。只要现实约束没有被及时注入,模型就会用语言概率去填补知识空白。“能接着说下去”本身就是幻觉的结构起点。
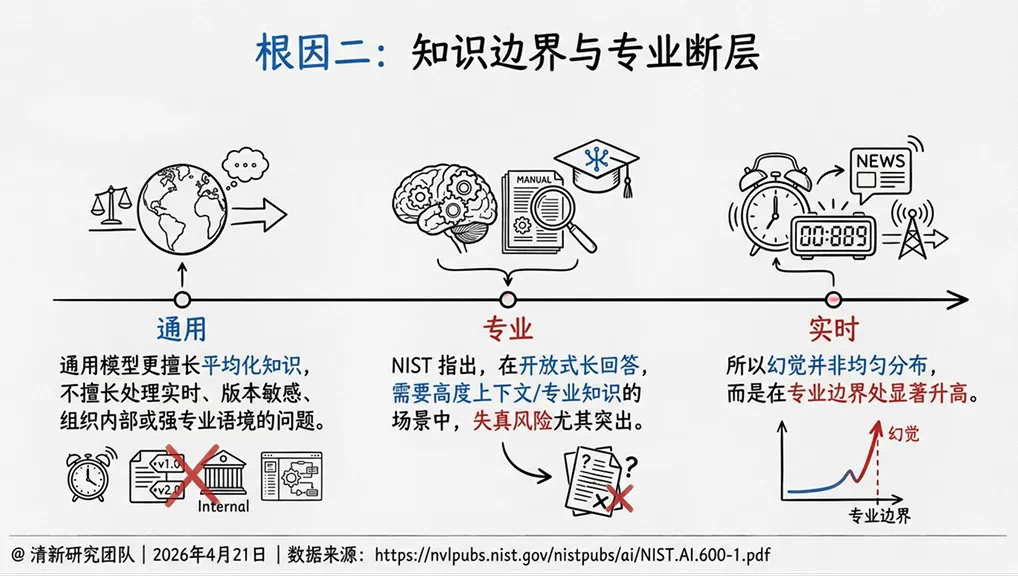
2. 知识边界与专业断层
通用模型更擅长“平均化知识”,不擅长处理实时、版本敏感、组织内部或强专业语境的问题。NIST指出,在开放式长回答、需要高度上下文和专业知识的场景中,失真风险尤其突出。幻觉并非均匀分布,而是在专业边界处显著升高。
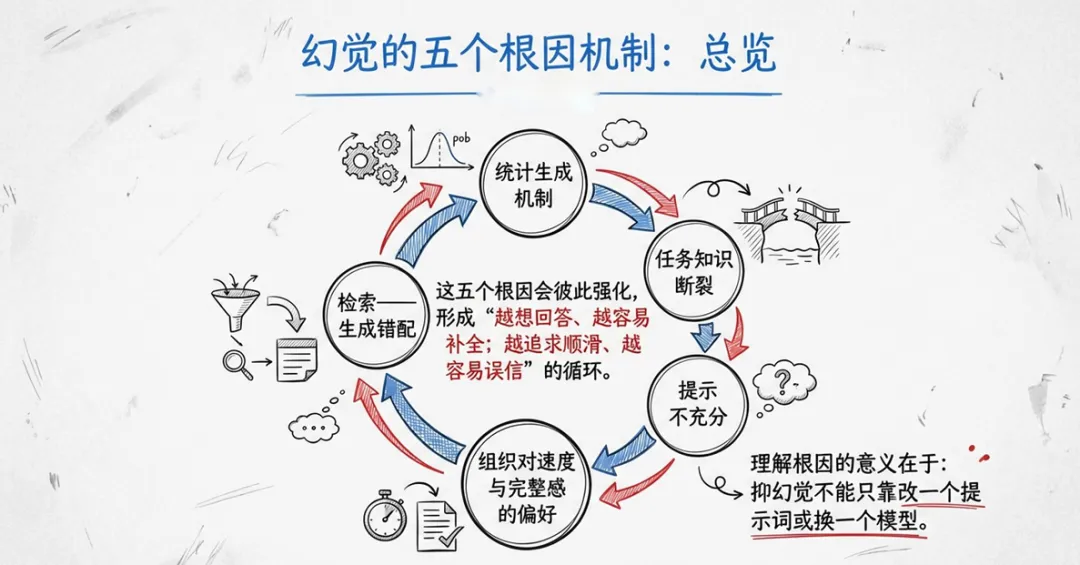
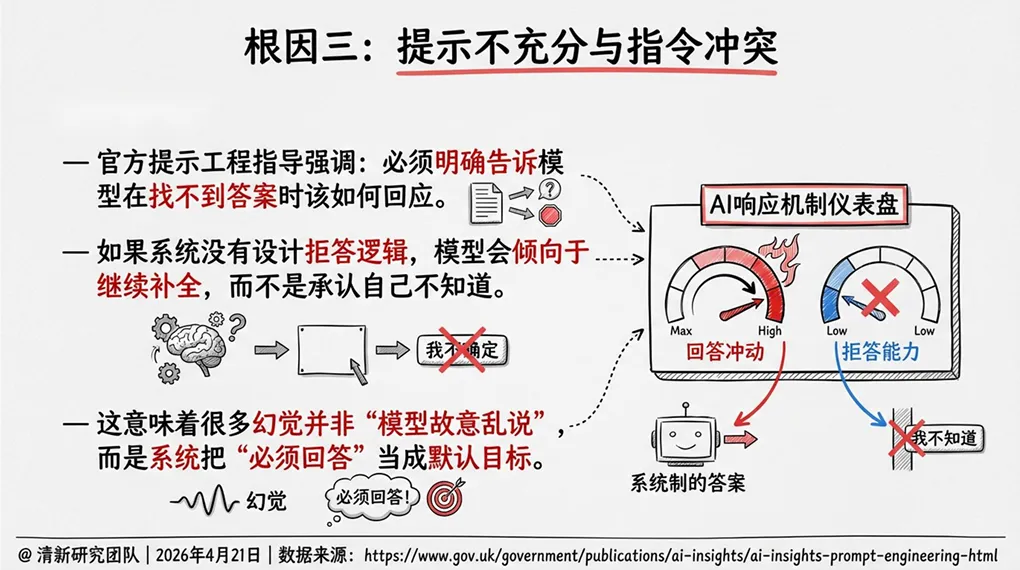
3. 提示不充分与指令冲突
很多幻觉并非“模型故意乱说”,而是系统把“必须回答”当成默认目标。官方提示工程指导强调:必须明确告诉模型在找不到答案时该如何回应。如果系统没有设计拒答逻辑,模型会倾向于继续补全,而不是承认自己不知道。
4. 组织对速度与完整感的偏好
组织内部往往更偏好“快速得到完整答案”,而非“准确但可能不完整的答案”。这种偏好会被传递到系统设计中,导致模型被迫在信息不足时继续生成。
5. 检索—生成错配
RAG系统虽然通过检索增强来减少幻觉,但检索到的内容与用户问题之间的匹配度、相关性、时效性都会影响生成质量。如果检索结果本身就有偏差,模型会在错误基础上继续构建回答。
真实世界案例:
从政府到医疗,风险正在规模化
报告引用了多个官方机构的真实案例,揭示幻觉风险已从实验室进入运营体系。
1. GOV.UK Chat:品牌信任是“放大器”而非“缓冲器”
英国政府推出的GOV.UK Chat,近70%用户认为回答有用,满意度不低。但官方同时观察到若干幻觉案例,并特别警告:对GOV.UK品牌的信任会让用户低估系统失真风险。政府、医院、高校和金融机构等权威界面,用户更容易把输出当成“官方说法”。品牌不是风险缓冲器,而是风险放大器。

2. 美国联邦机构:生成式AI用例一年增长约9倍
GAO报告显示,2024年11个联邦机构报告的生成式AI用例为282个,较2023年的32个增长约9倍。282个用例中,61%集中在内部使命支持(写、读、搜、总、跟踪等日常流程),15%用于政府服务,9%用于健康医疗。当采用加速而治理滞后时,幻觉问题就会从试验风险变成运营风险。

3. FDA:AI医疗设备已超1200个,进入规模化监管阶段
FDA官员在2026年初表示,已授权超过1200个AI-enabled medical devices。这意味着高风险行业中的AI使用已不是零星试验,而是进入规模化监管阶段。当AI进入大规模临床和医疗设备体系,幻觉治理就必须具备制度级成熟度。
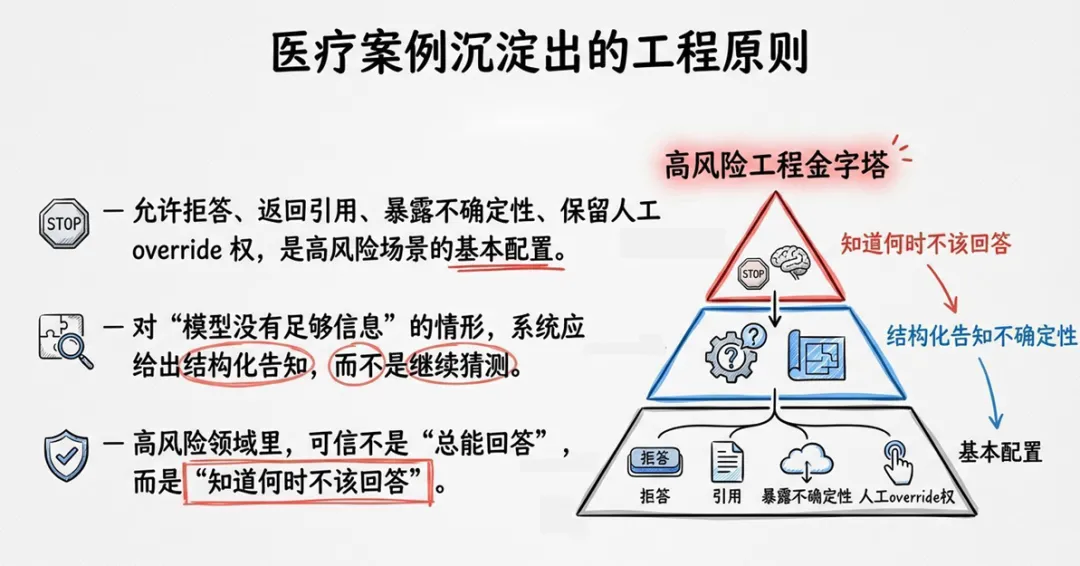
4. MHRA临床问答:护栏越严,拒答越多,如何平衡?
英国药品和健康产品管理局(MHRA)的临床问答实验显示:RAG与强护栏能显著压低重大幻觉,但也会提高拒答率和遗漏成本。如果系统为了安全而频繁不回答,临床人员可能失去效率,甚至错过关键提示;如果系统为了显得全面而继续补全,则可能直接误导临床决策。
这沉淀出一条工程原则:高风险领域里,可信不是“总能回答”,而是“知道何时不该回答”。 允许拒答、返回引用、暴露不确定性、保留人工override权,是高风险场景的基本配置。
治理工程:六层栈与“不用清单”
报告的核心贡献在于将幻觉治理落实为“可执行的工程栈”和“可操作的组织制度”。
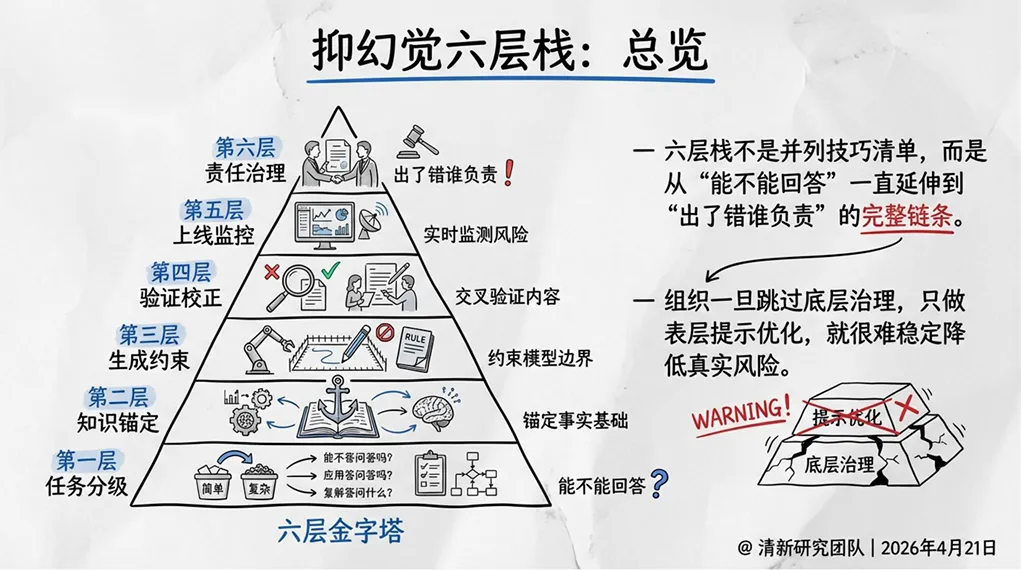
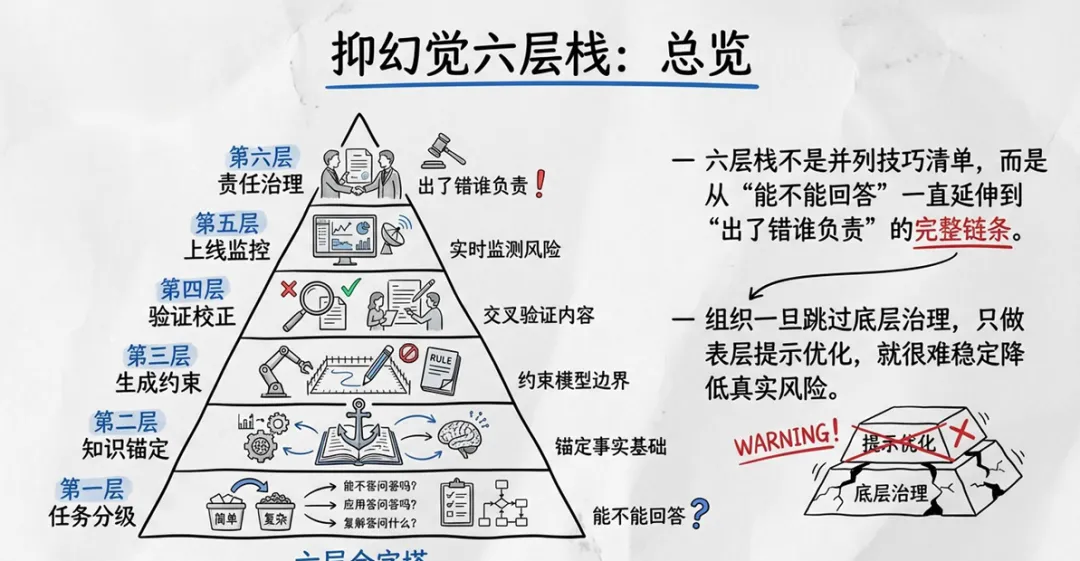
1. 抑幻觉六层栈
报告提出六层治理架构,从任务分级到责任制度层层递进:
第一层:任务分级。明确哪些场景可以用生成式AI、哪些场景禁用、哪些场景降格使用。
第二层:知识锚定。通过RAG将模型输出锚定到权威知识源,减少编造。
第三层:生成约束。设计拒答逻辑,允许模型说“我不知道”。
第四层:验证校正。对高风险输出做事实校验、引用核对、规则匹配、结构化比对。
第五层:上线监控与日志。持续监测输出质量,建立反馈闭环。
第六层:责任治理。明确谁对最终输出负责,建立可追溯的责任制度。
2. “不用清单”与“辅助使用清单”
报告建议组织明确两类清单:禁用清单——涉及健康、安全、权利、财务、法律后果的场景,不应让模型单独形成最终输出或动作;辅助使用清单——将模型降格为草拟、检索、解释或提要工具,并保留人工最终判断。真正成熟的组织,敢于明确哪里“不适合上生成式AI”。
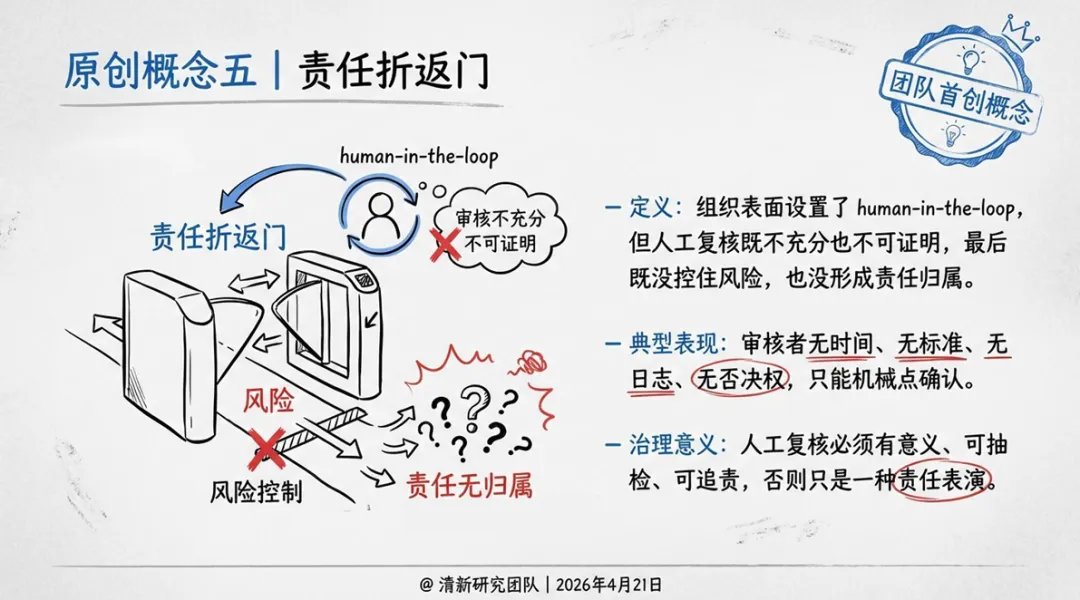
3. human-in-the-loop:不是“有个人看过”,而是“有否决权”
人工复核不是形式上的“有人看了一眼”。复核人需要明确职责、训练标准、升级路径与日志留痕,而不是机械点击确认。如果审核者无时间、无标准、无日志、无否决权,只能机械点确认——这就是报告提出的“责任折返门”:组织表面设置了human-in-the-loop,但既没控住风险,也没形成责任归属,只是一种“责任表演”。
三个原创概念:理解幻觉的新框架
报告提出了三个原创概念,帮助组织更精准地识别和管理幻觉风险。
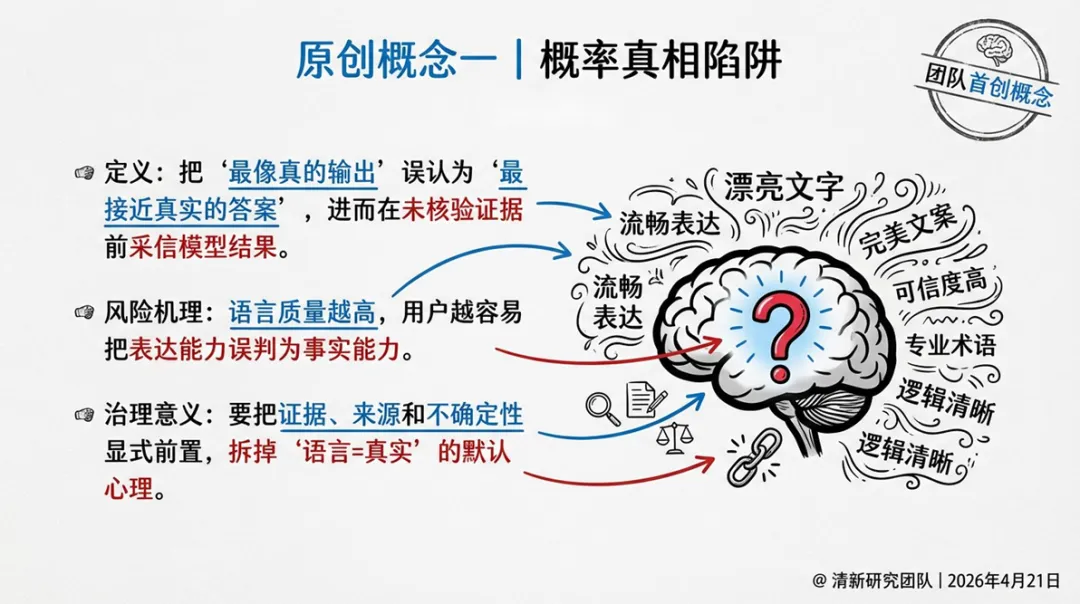
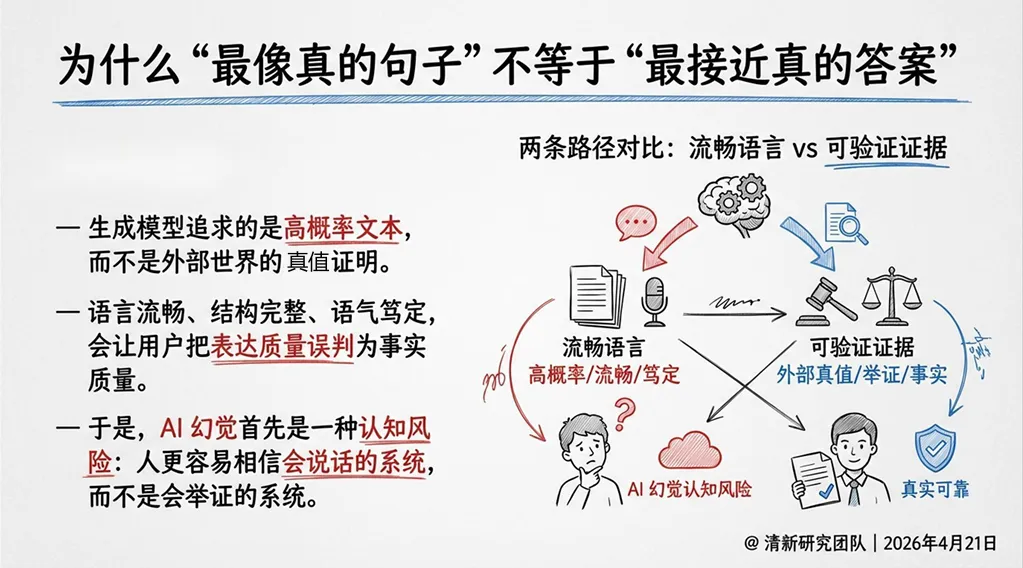
1. 概率真相陷阱
定义:把“最像真的输出”误认为“最接近真实的答案”,进而在未核验的情况下提前采信模型结果。
风险机理:语言质量越高,用户越容易把表达能力误判为事实能力。
治理意义:要把证据、来源和不确定性显式前置,拆掉“语言=真实”的默认心理。
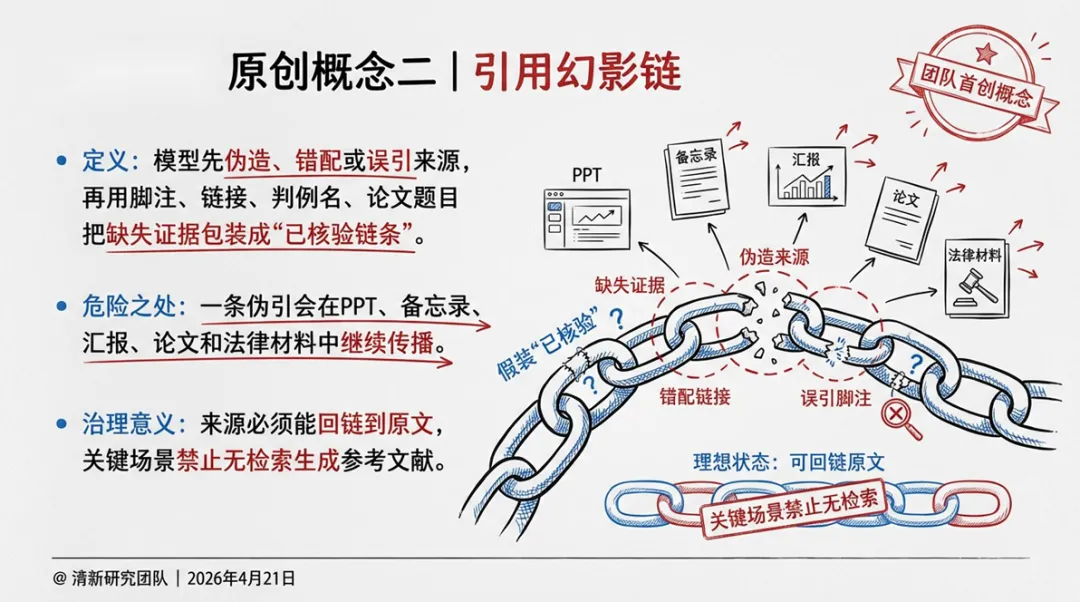
2. 引用幻影链
定义:模型先伪造、错配或误引来源,再用脚注、链接、判例名、论文题目把缺失证据包装成“已核验链条”。
危险之处:一条伪引会在PPT、备忘录、汇报、论文和法律材料中继续传播,从模型错误变成组织知识污染。
治理意义:来源必须能回链到原文,关键场景禁止“无检索生成参考文献”。
3. 低置信高伤害区
定义:模型自己并无稳定依据,组织却让它介入高后果任务,形成“模型低置信、用户高依赖”的危险带。
识别方法:关注健康、安全、权利、财务、合规与公共影响类任务。
治理意义:对这些区域,要么禁用生成式AI单独处理,要么把它降格为辅助工具。
行动路线图:30天、60天、90天
报告给出了具体的时间表,供组织参考。
30天:先把最危险的任务识别出来,明确哪些场景属于“低置信高伤害区”,哪些该纳入禁用清单。
60天:补上知识锚定与拒答机制,让RAG成为标准配置,让模型学会说“我不知道”。
90天:把人工复核和日志做成制度,让human-in-the-loop从“表演”变成真正的风险控制节点。
从“会用模型”到“驾驭模型”,分水岭不是模型能力本身,而是组织是否建立了从任务分级、知识锚定、生成约束、验证校正、上线监控到责任治理的完整控制链。
结语
AI幻觉治理的对象不是一句错话,而是一整条从“生成”到“采信”再到“执行”的链条。真实世界案例已经证明:政府、医院、高校、金融机构等权威界面,品牌信任不是风险缓冲器,而是风险放大器。
未来真正有竞争力的组织,不是让模型“看起来无所不知”,而是让模型在不知道时停下来、在高风险时退后一步。当证据、流程、审计与责任被同时嵌入,组织才算从“会用大模型”迈向“驾驭生成式AI”。
报告节选



面对瞬息万变的市场,精准决策需要专业信息支持。三个皮匠报告提供全球核心研究资源,八大核心板块,助您高效获取深度洞见。
报告库:拥有庞大的500万份+行业研究报告数据库,覆盖国内外TOP级咨询公司与机构,致力于保障信息的时效性与高质量,核心优势:
1.每日更新:每日新增报告超过900份,确保信息始终处于行业前沿。
2.来源严选:报告来源于广泛的专业机构与智库,经过系统性收录与整理,保障内容的专业性与参考价值。
3.报告合集:提供按行业、产业或关键概念(如“十五五规划”、“银发&养老”、“低空经济”等)的报告合集,每个合集内包含近两年内市面上经人工挑选的优质中英文报告/研报等,一键打包下载,动态维护更新。
英文报告库:收录全球TOP咨询公司、知名研究所、顶级国际智库原版英文报告,并提供AI智能翻译与总结,实现中英对照高效阅读。
研报库:严选国内外顶级券商与投行的深度分析报告,直接服务于价值判断与市场预判。
顶级外资投行:摩根士丹利、摩根大通、巴克莱、瑞银、高盛GS、德银、杰富瑞、美银、汇丰、晨星Morningstar、星展银行、法兴、野村等……
企业财报库:系统收录全球主要上市公司的官方年报、季报及招股说明书(IPO文件),涵盖A股、港股、美股等全球主要股市。
数据图表库:从海量报告中深度提取、清洗和归类了超过1200万份核心数据与图表,涵盖市场规模、竞争格局、财务趋势、技术路径等关键可视化信息,支持一键下载使用。
会议峰会:实时汇聚从国内行业峰会到国际专业论坛的会议嘉宾演讲资料,将嘉宾的核心演讲PPT整合成专题,一键打包下载。
政策库:及时收录国家及地方各级产业政策。更有专题/汇编两大特色服务,精准定位行业政策。
1.政策专题:提供按行业、产业或关键概念(如“新能源汽车”、“碳中和”、“人工智能”)的政策全景视图,方便了解从国家到各个地区关于这些领域的相关政策。
2.政策汇编:提供热门概念及重点产业核心政策文件汇编(如国家部委发文、地方政府条例等)。
自研报告库:聚焦前沿技术与新兴产业,提供独家、深度的原创研究,输出具有前瞻性的市场洞察。