本篇行业报告可以通过扫下方知识星球下载。39元就可以下载星球所有报告,免费提供报告查找服务。

这份 100MW 超大规模 AI 数据中心架构方案,以 Tier III 可并行维护为标准,整合西门子工业电气、NVIDIA GB200 NVL72 算力平台与 nVent 液冷技术,面向高密度 AI 负载打造快速部署、高能效、高可用的基础设施,适配 UL 规范市场与全球多区域部署。
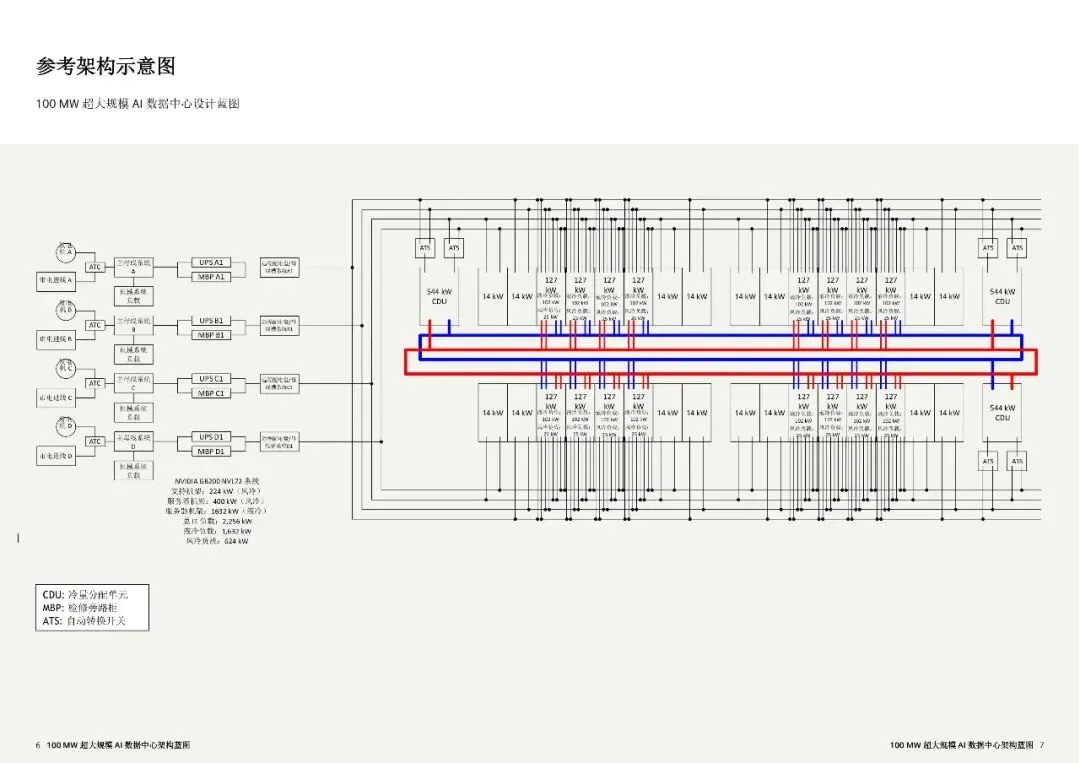
方案核心面向 AI 算力两大关键指标:缩短算力上线周期、提升每瓦算力产出。当前 AI 机架功率密度突破 100kW,传统风冷与配电难以承载,因此采用模块化 Pod 架构、高压直供、单相液冷与智能协同控制,实现性能、能效与扩展性的平衡。整体可承载 640 个服务器机架,总 IT 负载约 100MW,划分为 40 个 Pod 单元,每个 Pod 含 32 个机架,负载 2256kW,支持分阶段扩展并兼容下一代 GB300 平台。
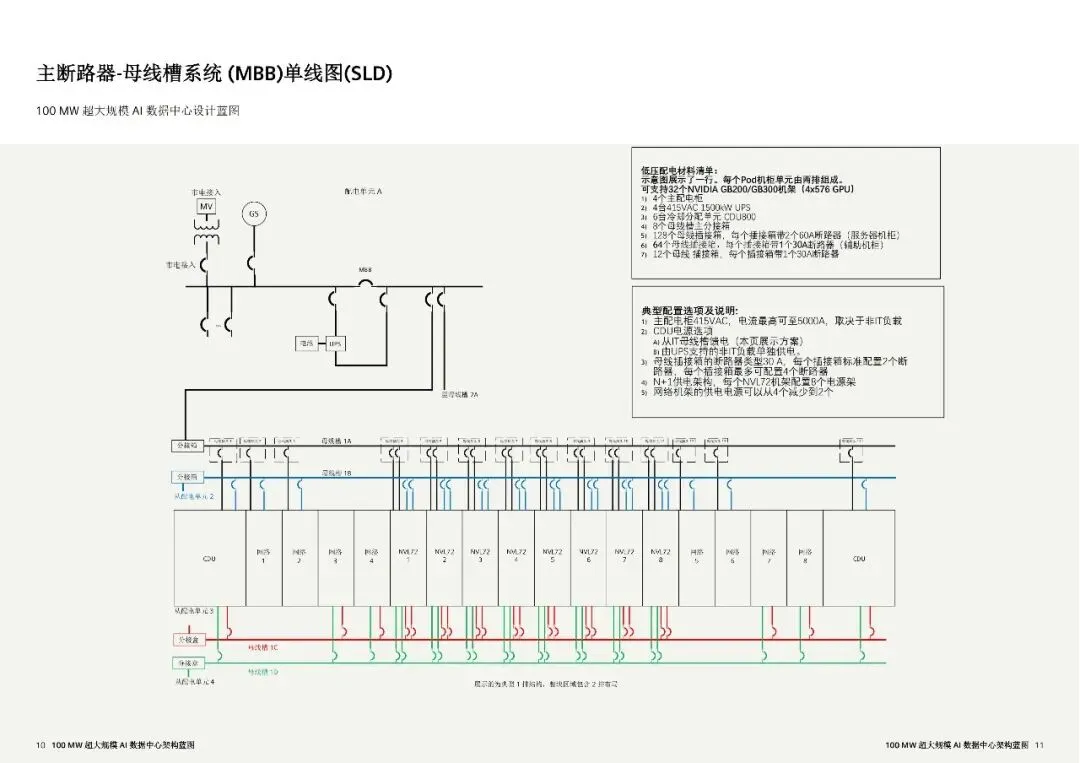
配电系统按 Tier III 设计,采用 4 取 3 冗余与 N+1 UPS 架构,中压 34.5kV 进线,低压直接以 415V 供至机架,减少配电层级、提升效率。单 Pod 配置 4 台 1500kW UPS 与主配电柜,通过架空母线槽分配电力;GB200 NVL72 机架配 8 路 60A 回路,满足 127kW 负载需求,网络与 CDU 分别配双路与四路 30A 回路,保障供电稳定与故障隔离。
冷却采用 nVent 直达芯片液冷,遵循 ASHRAE W32–W45 温水标准,最大化自然冷源利用。每个 Pod 配 3 台 CDU800,单机柜液冷负载 102kW、风冷 25kW,总液冷负载 1.63MW。CDU 采用双泵双路独立供电,单部件故障不降低制冷能力,无需 N+1 冗余扩容,兼顾可靠性与效率,适配高温高湿或寒冷等不同气候。
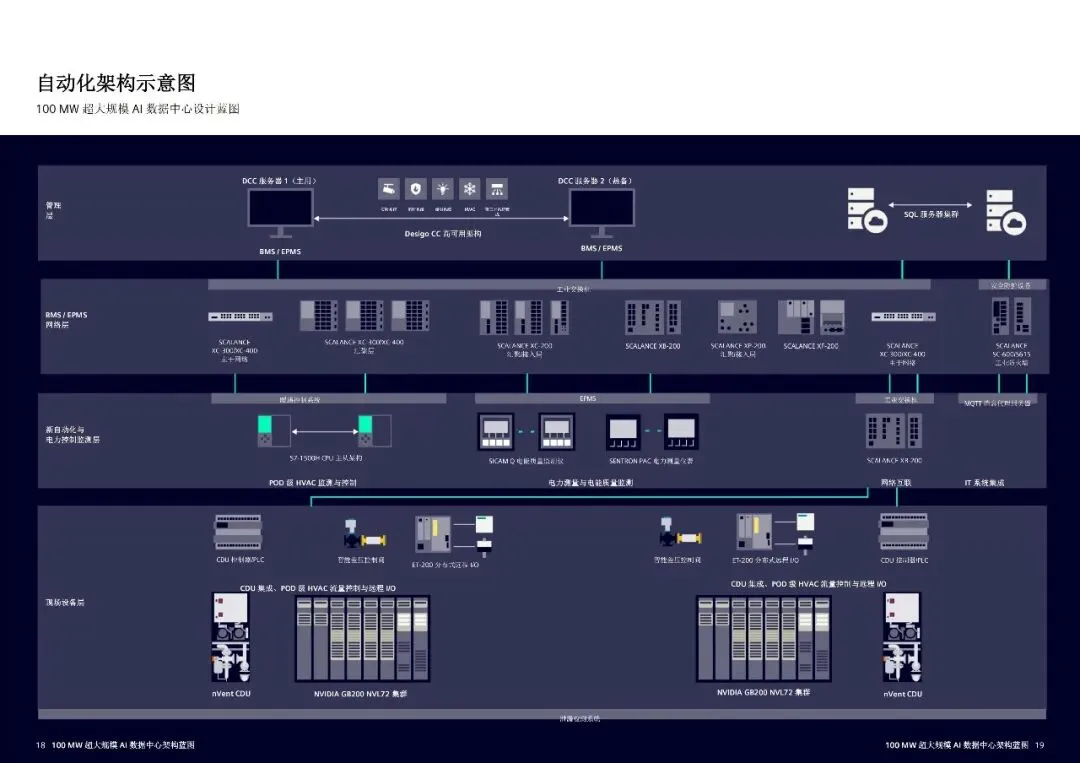
自动化与控制以 IDCMS 为统一平台,对接 NVIDIA Mission Control,实现 OT 与 IT 层无缝协同。采用 PLC 热备冗余架构,机柜级网关实时监测流量、温度、压力与泄漏,异常时自动隔离机柜,不影响整体运行。电力系统接入电能质量监测仪表,实现远程控制、动态负载管理与预防性维护。
该方案以模块化、高冗余、液冷协同与智能管控为核心,在保障运行连续性的同时降低 PUE,缩短部署周期,提升算力密度与能源效率,为超大规模 AI 算力设施提供可复制、可扩展的标准化架构,助力企业实现高效 AI 运营与可持续发展目标。
报告内容节选







免费报告查找,请添加微信:

免责声明:以上分享报告为公开合法渠道获得,内容大部分来源于网络,版权归原作者所有,如有侵权,请及时与我们联系,我们将第一时间保障您的权益。推荐内容仅供参考学习,不构成投资建议。