
“2026AI幻觉深度研究报告:基于政府与监管来源核验的机制、风险、治理与抑制幻觉工程研究”由清华大学发布。报告基于多个政府与监管机构(如NIST、英国政府、FDA、NCSC、中国网信办等)的官方框架和案例,研究深入且具有实践指导意义。未来组织的核心竞争力不在于让AI“无所不知”,而在于能驾驭AI,使其在“不知道时停下来,在高风险时退后一步”。真正的治理对象不是单次错误输出,而是从生成到执行的整个链条,需要将证据、流程、审计与责任系统性嵌入。
本报告共计:75页。完整版PDF电子版报告下载方式见文末。
一、 核心结论与总判断
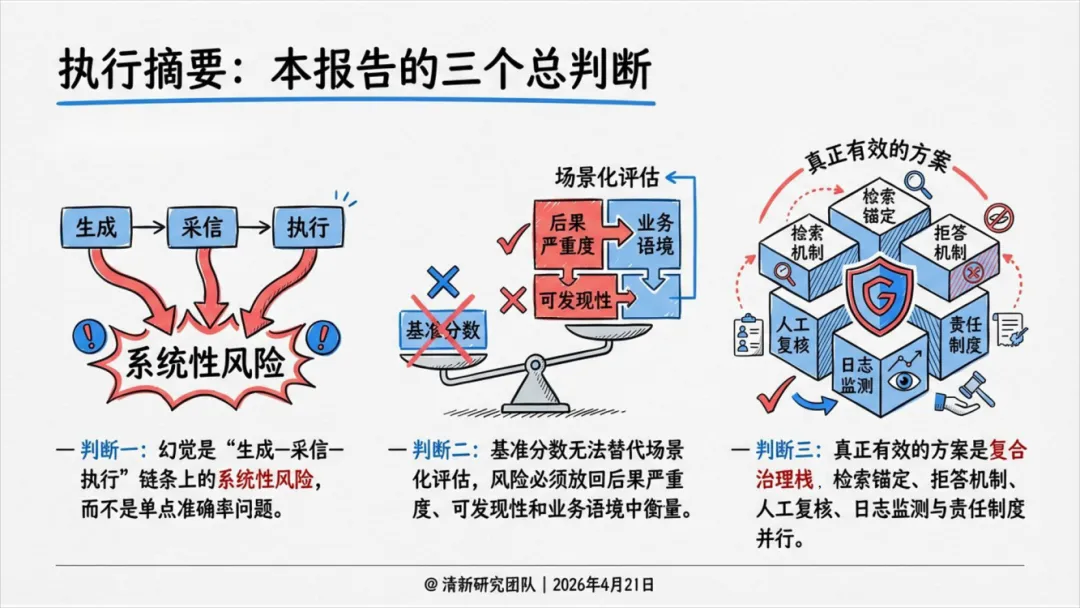
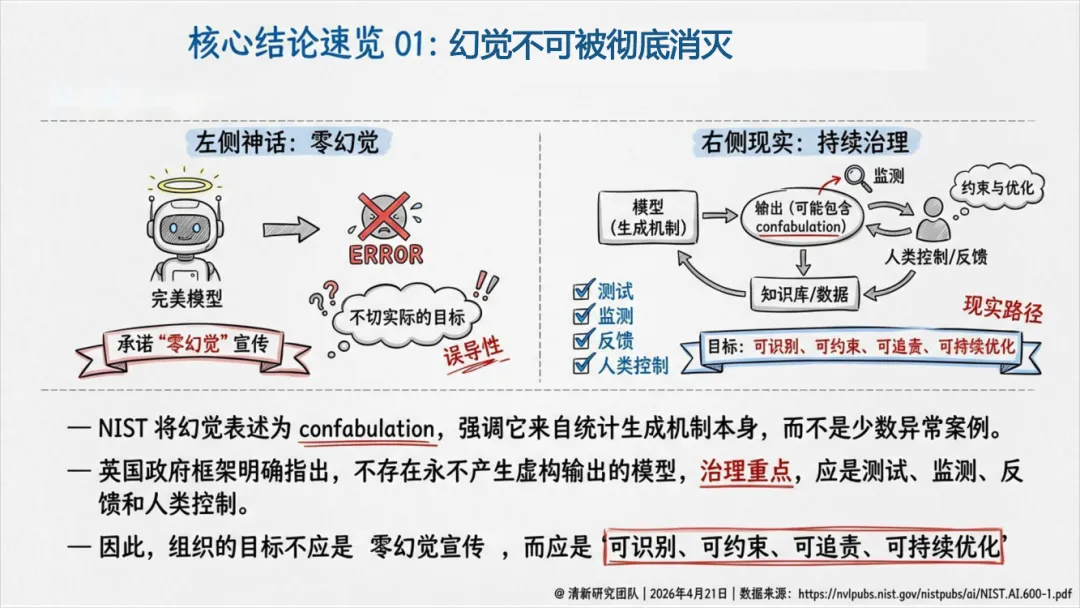
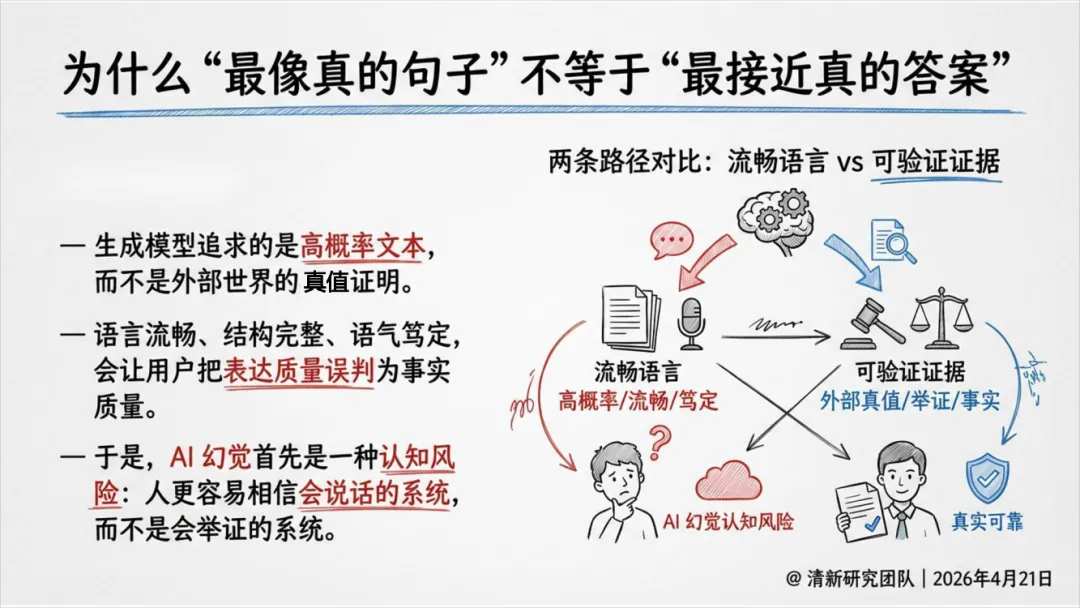
幻觉不可根除,治理是目标:幻觉(报告采用NIST术语“Confabulation”)源于大模型统计生成的根本机制,而非偶然错误。“零幻觉”是不可能的,现实目标是实现幻觉的“可识别、可约束、可追责、可持续优化”。
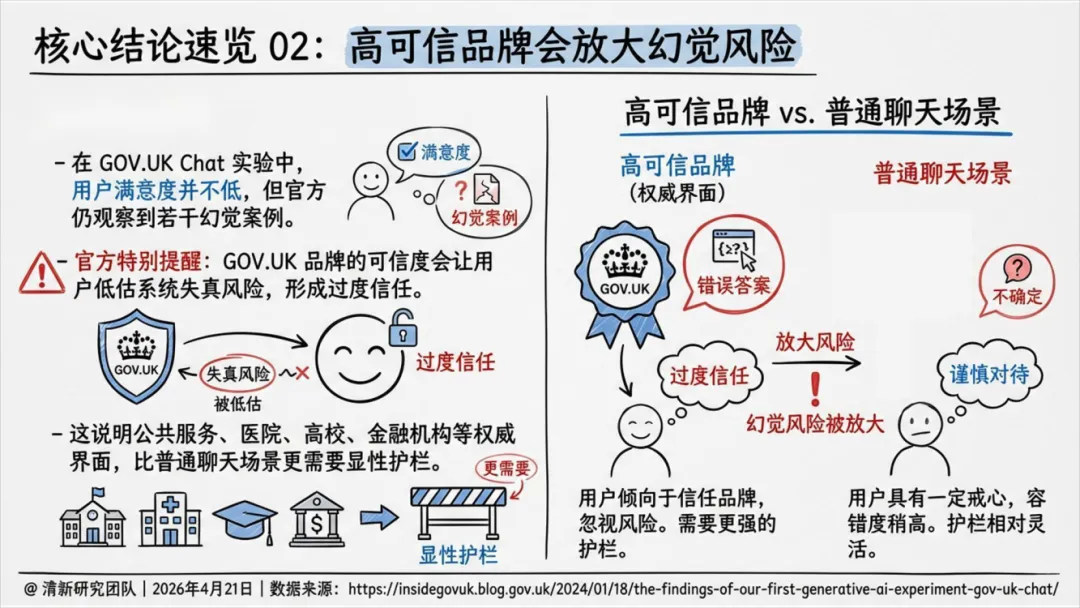
高可信品牌会放大风险:在政府、医院、高校、金融等高权威性界面上,用户会因信任品牌而降低对AI错误的戒心。因此,权威场景需要比普通聊天更严格、更显性的风险护栏。
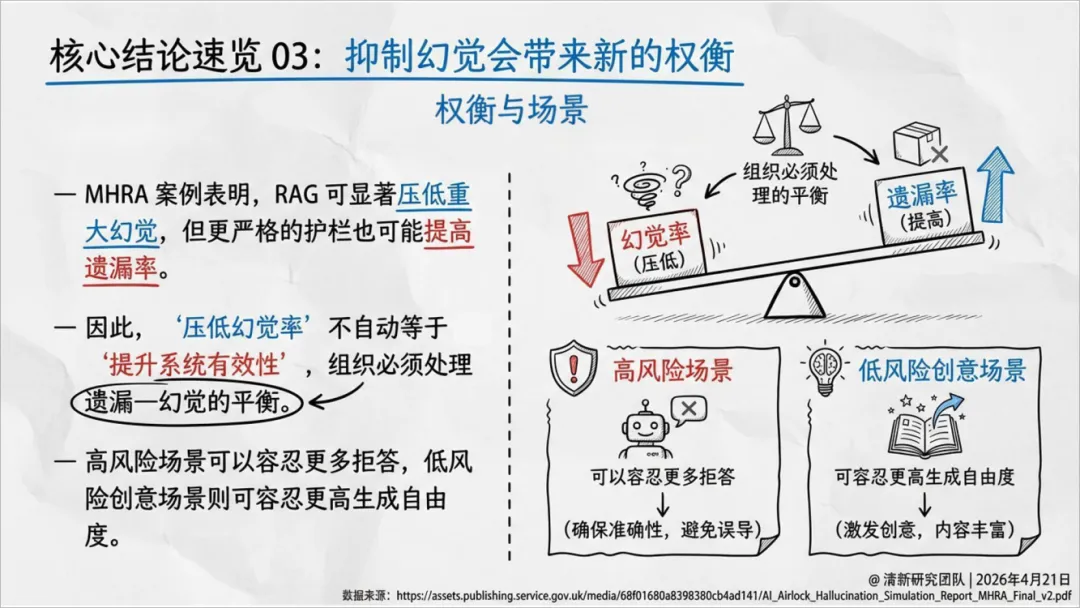
治理存在权衡(遗漏-幻觉跷跷板):一味压低幻觉率(如通过严格的RAG和护栏)可能导致拒答率或遗漏率上升(如MHRA医疗案例所示)。治理目标不是最小化幻觉,而是根据场景在“遗漏风险”和“幻觉风险”间取得最佳平衡。
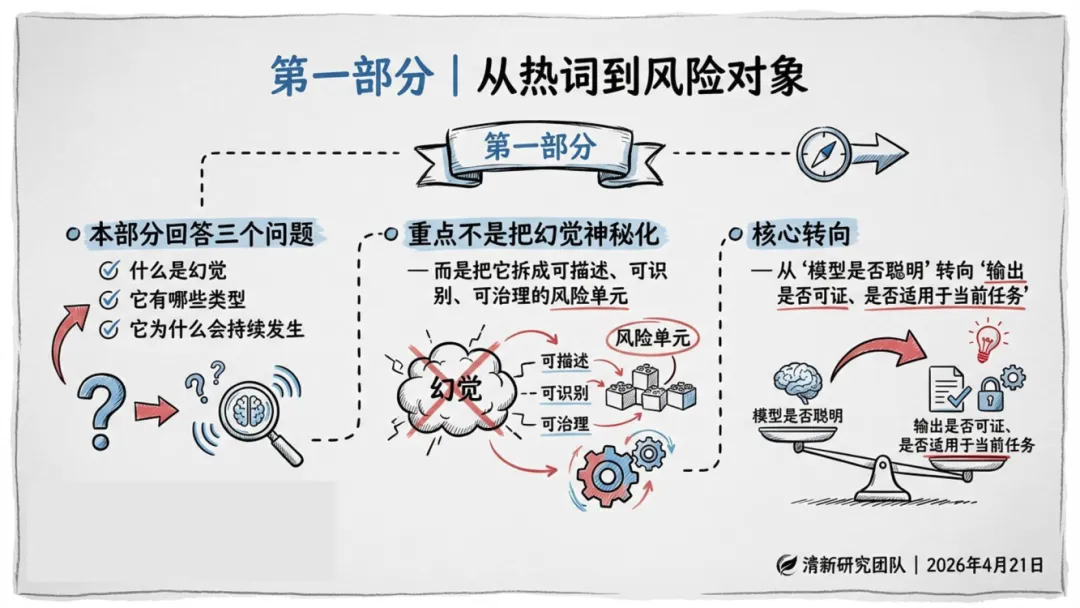
二、 幻觉的深度理解
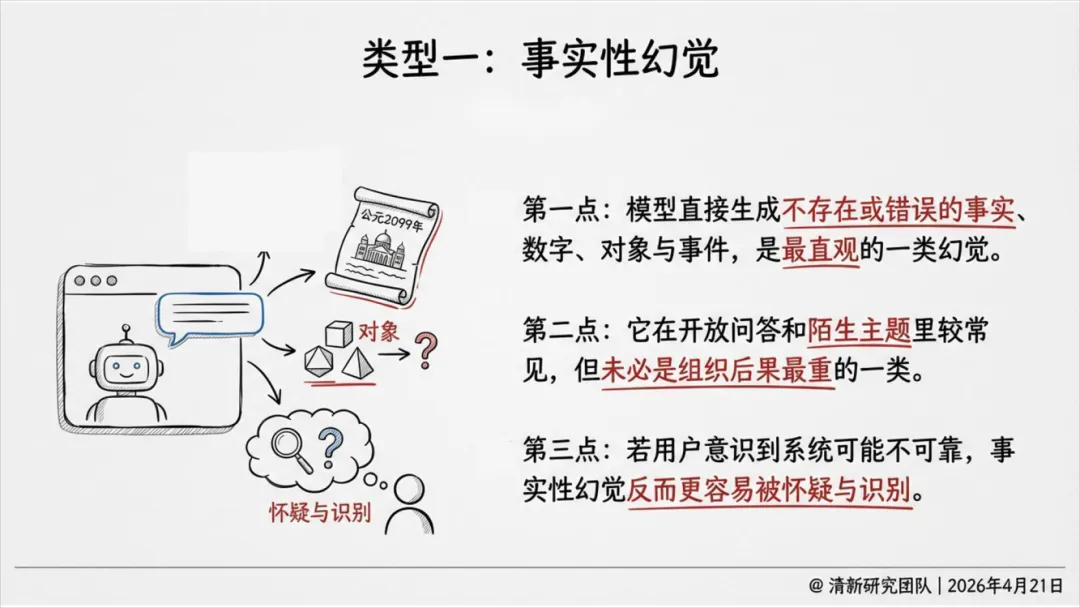
定义:幻觉不单指“事实错误”,而是模型自信地生成错误、虚假或未经证实的内容,包括事实、逻辑、引用、语境、行动指令等多个层面的不匹配。
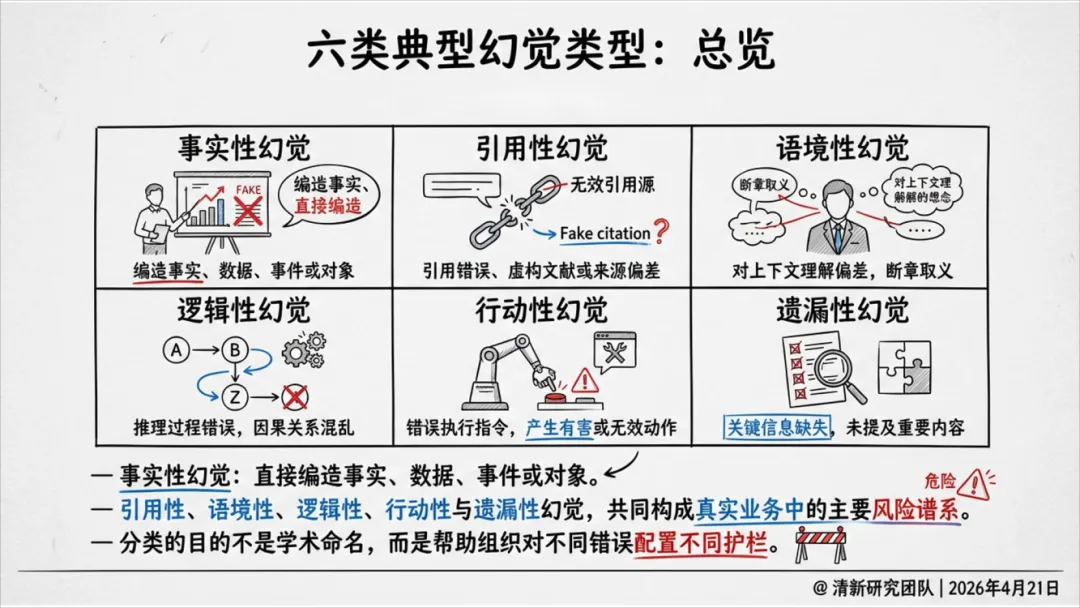
六大类型:
事实性幻觉:编造不存在的事实、数据、事件。
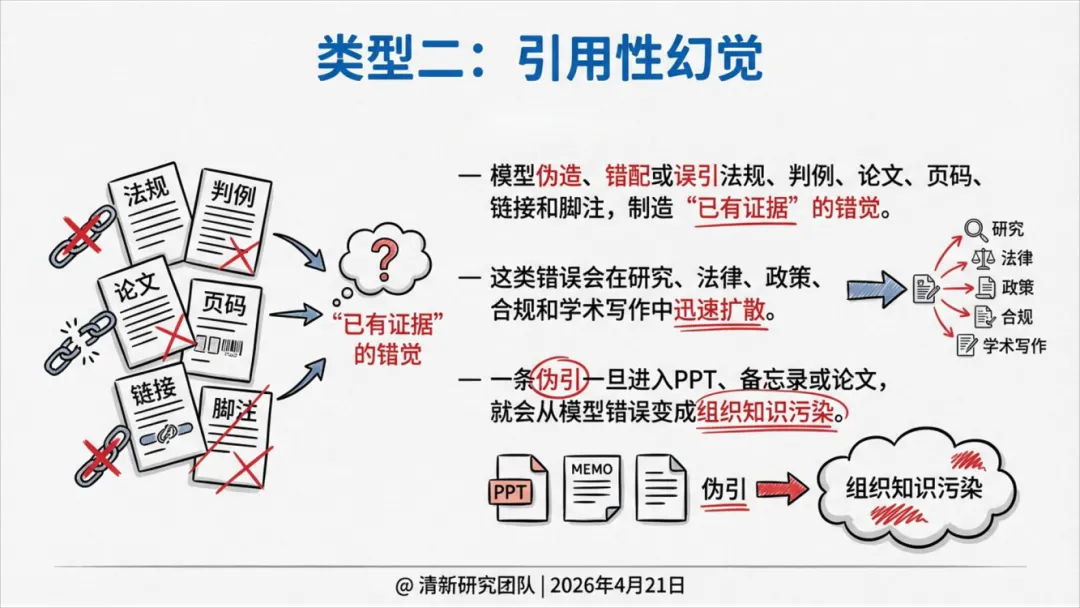
引用性幻觉:伪造、错配或误引文献、法条、来源等。
语境性幻觉:答案本身看似合理,但与当前具体情境(如国家、行业、时间)不符。
逻辑性幻觉:在证据不足时,生成一套看似连贯、合理的错误推理链条。
行动性幻觉:错误地理解或执行指令,触发错误工具调用或流程。
遗漏性幻觉:因过度保守而漏掉关键信息,或不当拒答。
根本成因:统计生成机制、知识边界、提示不充分/冲突、组织对“完整回答”的偏好、检索-生成(RAG)错配。
三、 真实世界的风险与挑战
实验室测试≠上线可靠:离线基准无法覆盖真实世界的提示模糊、信息更新、长链条任务和用户多样性。必须进行真实场景下的持续评估和红队测试。
品牌风险:GOV.UK案例表明,用户对高可信度官方服务的信任,反而会降低其对AI输出错误的警惕性,形成“过度信任”。
规模化应用加速风险:美国GAO报告显示政府AI用例一年内激增约9倍,但治理能力(合规、政策、培训)未能同步跟上,使“试验性风险”快速转为“运营风险”。
高风险行业的特殊挑战:
医疗(FDA、MHRA):AI已进入规模化监管。RAG能减少重大幻觉,但必须权衡由此带来的遗漏风险。高风险场景的基本原则是 “知道何时不该回答” ,并保留人工复核权。
法律、学术:引用性幻觉危害最大,一条伪造的引文会污染整个知识链条。
网络安全(NCSC):在Agent场景中,提示注入会将文本幻觉转化为系统边界安全问题。模型不擅长区分“指令”和“数据”,外部恶意输入可能被当作命令执行。
四、 治理框架与组织行动
官方框架共识:
承认不可消灭:接受幻觉是持续风险,需持续治理。
强制人类复核:高影响场景(法律、健康)必须设置有意义的人类介入,复核人需有明确的否决权、能力和责任。
内容可追溯:中国监管要求对生成内容进行标识,并建立投诉反馈机制,为责任追溯和审计提供基础。
组织治理三步法:
第一步:绘制任务风险地图。根据任务后果(健康、财务、法律等)和AI角色(草拟、问答、执行等),定义不同的护栏强度。
第二步:设定禁用与降格规则。明确哪些高风险场景禁止AI单独输出,哪些场景只能将其作为辅助工具。
第三步:确保“有意义”的人工复核。复核必须是可证明、可抽检、可追责的,而非形式化的“责任表演”。
抑幻觉工程六层栈:
任务分级:识别风险,确定护栏强度。
知识锚定:使用RAG等技术,将回答锚定在可控、可验证的权威知识源上。
生成约束:在提示工程中明确“允许拒答”的规则,防止模型强行补全。
验证校正:对高风险输出进行事实核对、引用回链、规则匹配。
上线监控:建立使用日志、反馈循环和持续评估机制。
责任治理:明确AI系统所有者、开发者和使用者的责任。
Agent场景的特殊性:当AI能调用工具并执行操作时,抑幻觉工程必须与安全工程合并。需采用最小权限、外部内容标注、关键动作确认、熔断设计等手段,防止“说错”演变为“做错”。
幻影视界整理分享报告原文节选如下:


 戳“阅读原文”下载报告。
戳“阅读原文”下载报告。