
AI科普馆部分垂类内容转移至?
【长三角人工智能联盟】公众号,快点进去瞧瞧!
清华大学清新研究团队发布的这份75页的《AI幻觉深度研究报告》和市面上其他"AI幻觉"文章不同,这份报告把"幻觉"拆成了可测量、可治理、可追责的系统性风险单元,并给出了一套完整的幻觉治理工程栈。结论很明确:幻觉问题不是"模型够不够聪明",而是"错误如何被组织采信并执行"。
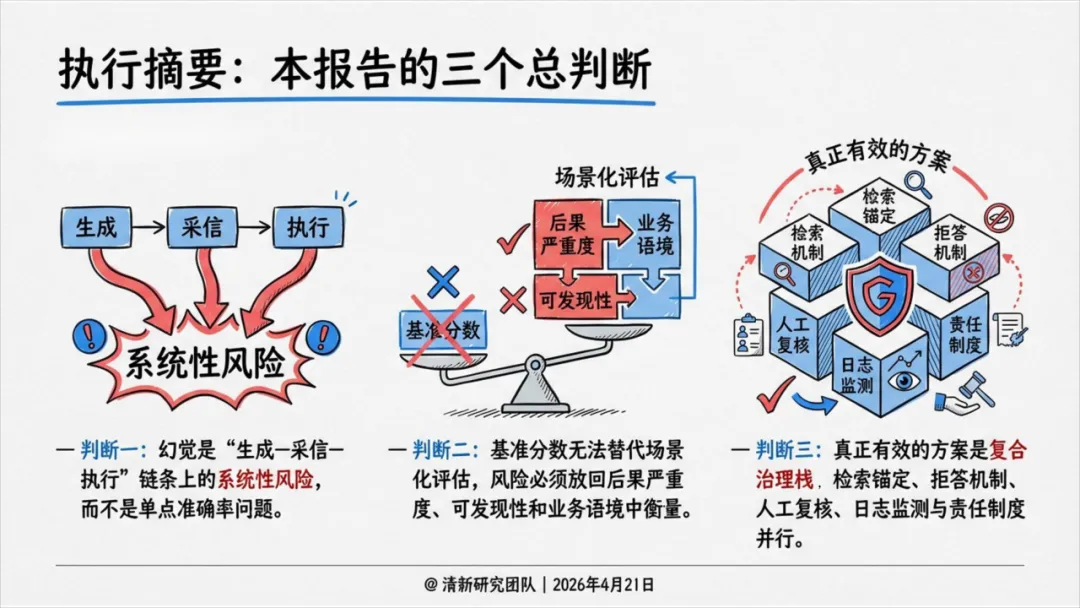
核心结论:三个总判断
报告开篇用三个判断定调:
判断一:幻觉是"生成—采信—执行"链条上的系统性风险,不是单点准确率问题。 真正危险的不是模型偶尔说错一句话,而是那句话被写进报告、进入决策、触发执行。
判断二:基准分数无法替代场景化评估。 同样5%的错误率,在娱乐问答里可以容忍,在医疗诊断里就是事故。风险必须在后果严重程度、可发现性和业务语境中衡量。
判断三:真正有效的方案是复合治理栈。 检索锚定、拒答机制、人工复核、日志监测与责任制度并行,而不是押宝某一个"零幻觉"模型。
一、六类幻觉:不只"说错话"
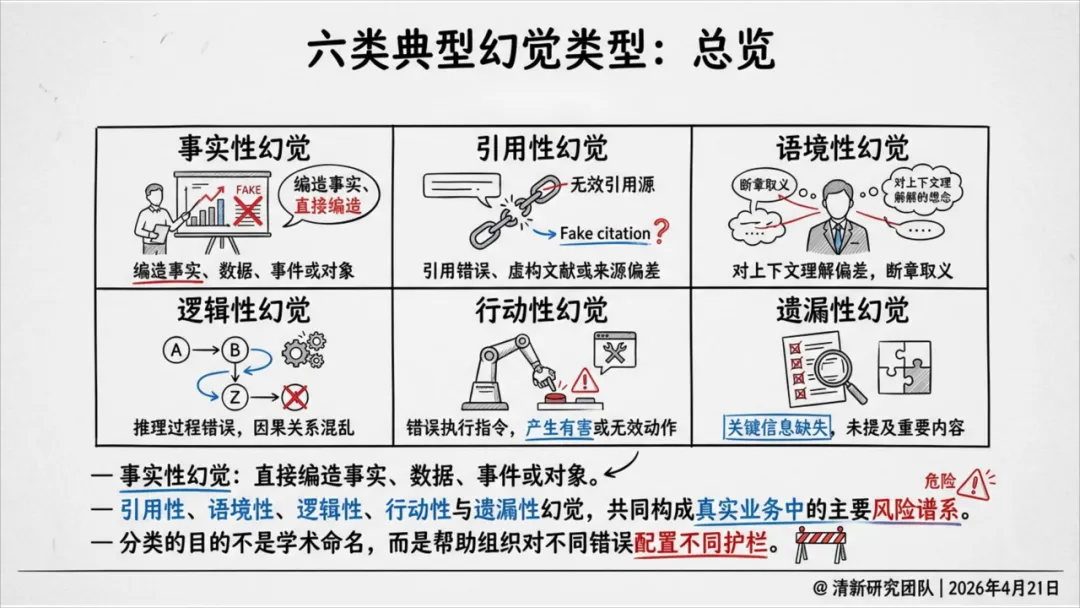
报告把幻觉拆成六类,这个分类是全文最重要的基础:
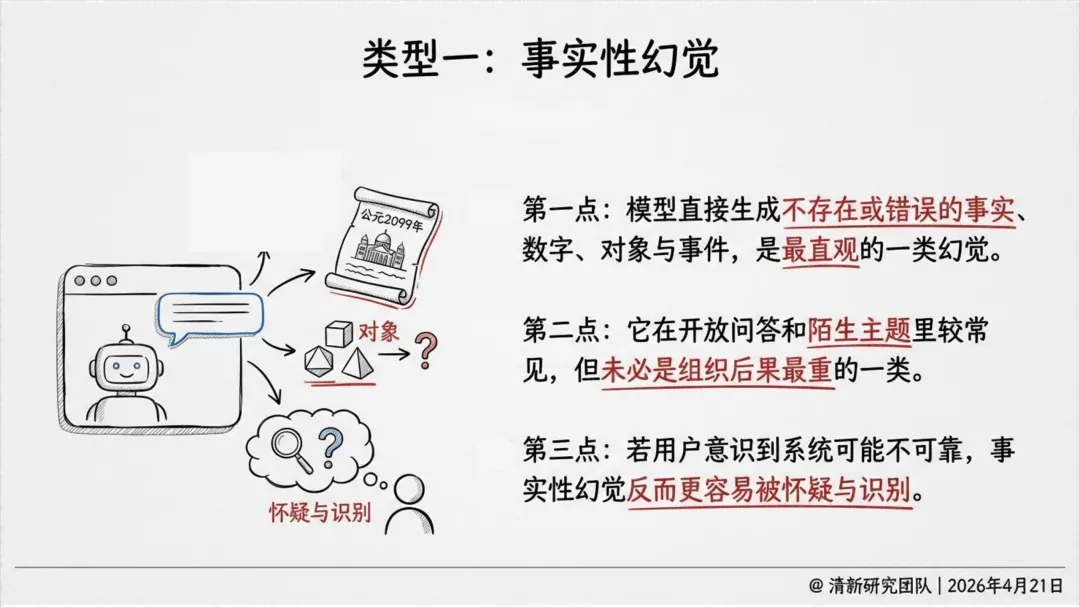
| 事实性幻觉 | ||
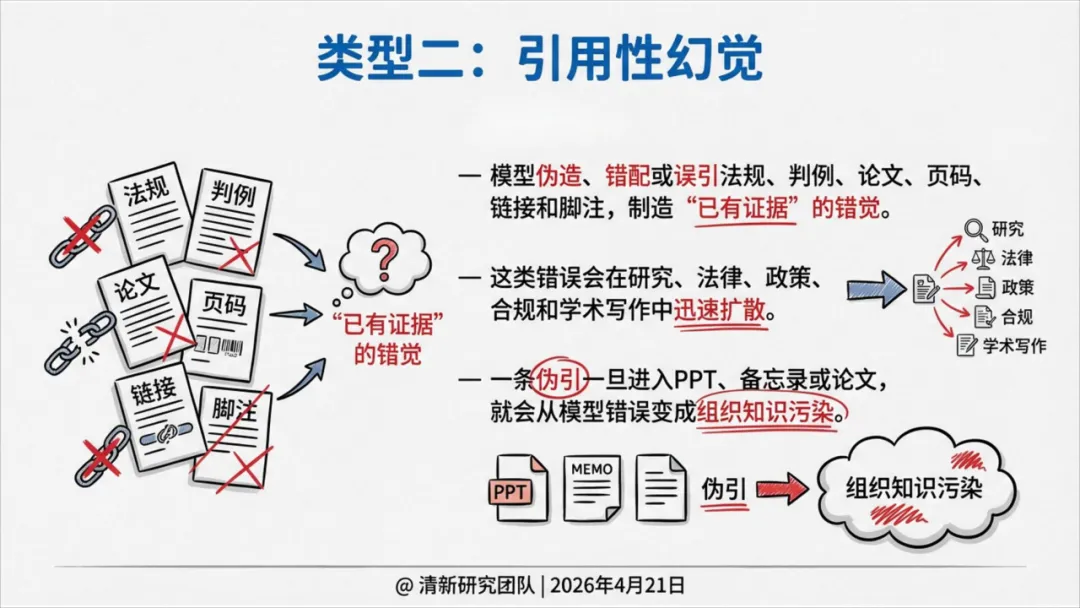
| 引用性幻觉 | ||
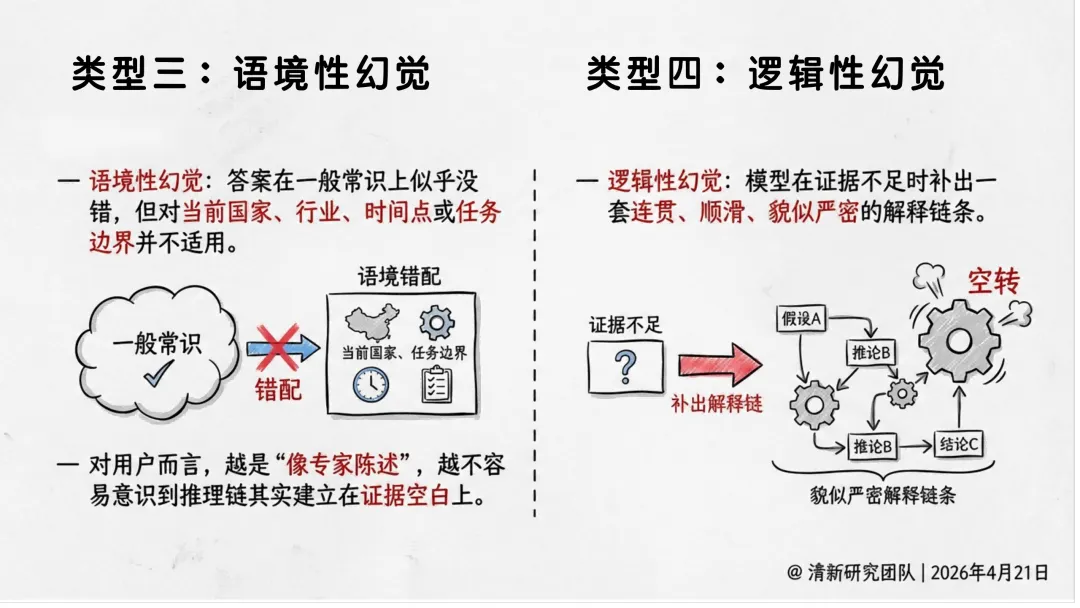
| 语境性幻觉 | ||
| 逻辑性幻觉 | ||
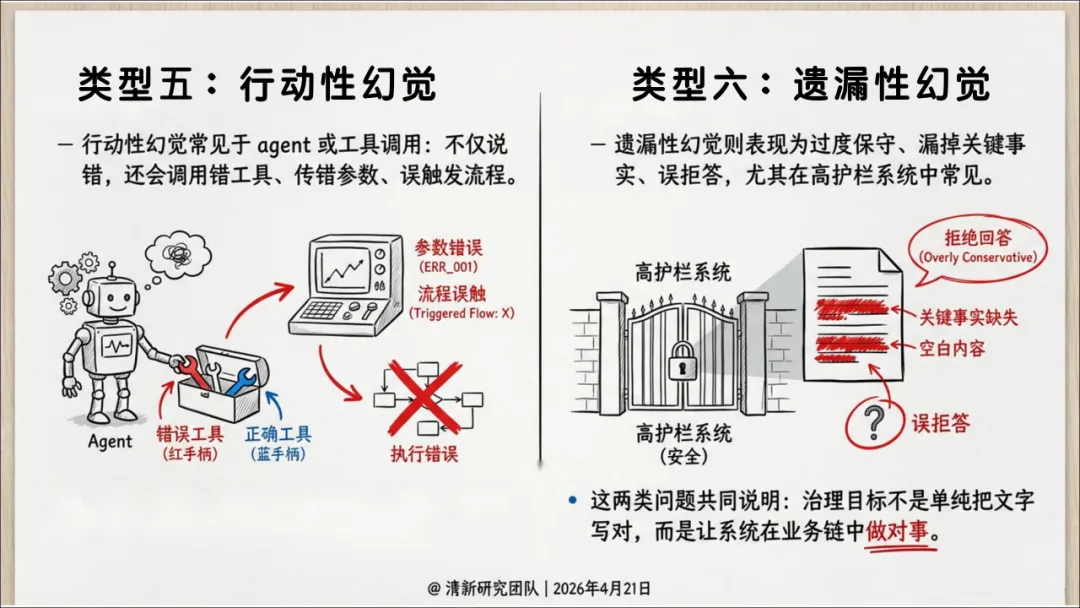
| 行动性幻觉 | ||
| 遗漏性幻觉 |
其中引用性幻觉被报告特别强调——一条伪引一旦进入PPT、备忘录或论文,就会从"模型错误"变成"组织知识污染",在机构内持续传播。
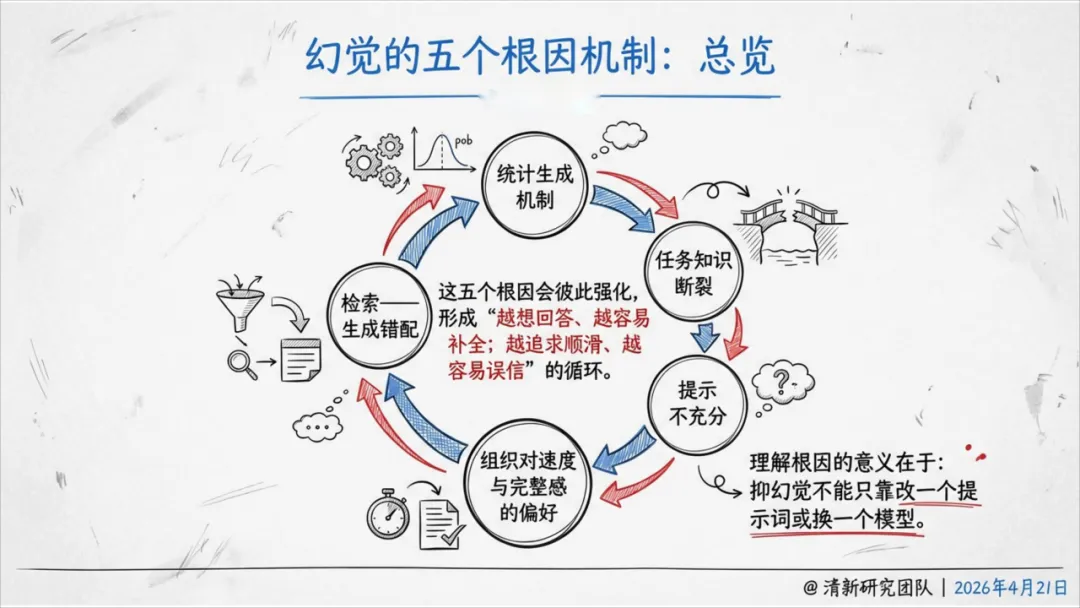
二、五个根因:为什么幻觉消灭不了
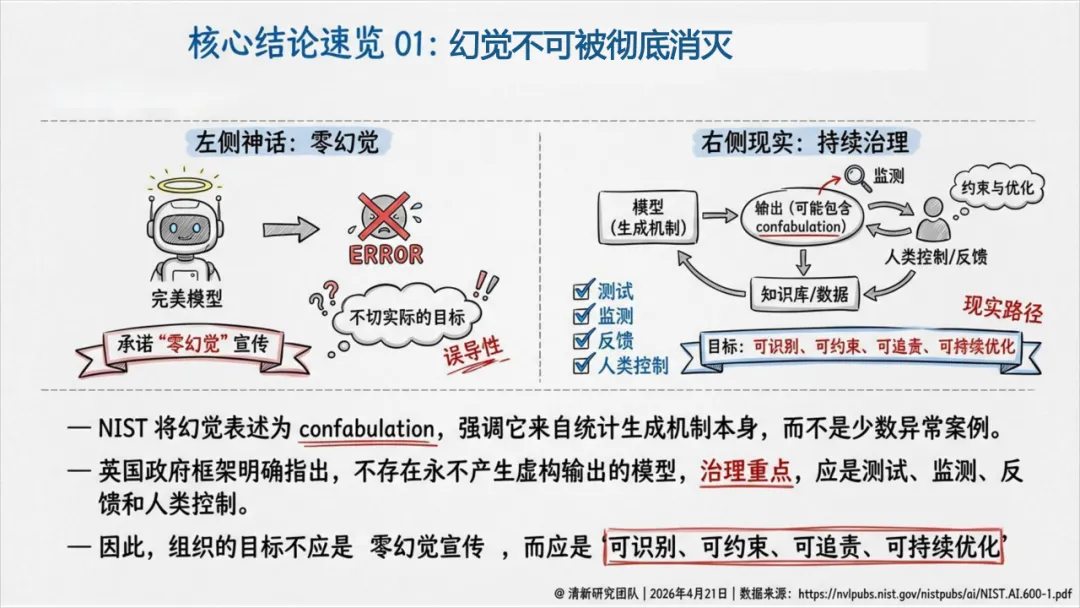
报告花了大量篇幅解释幻觉从哪来。结论很清醒:幻觉来自统计生成机制本身,不可能被彻底消灭。
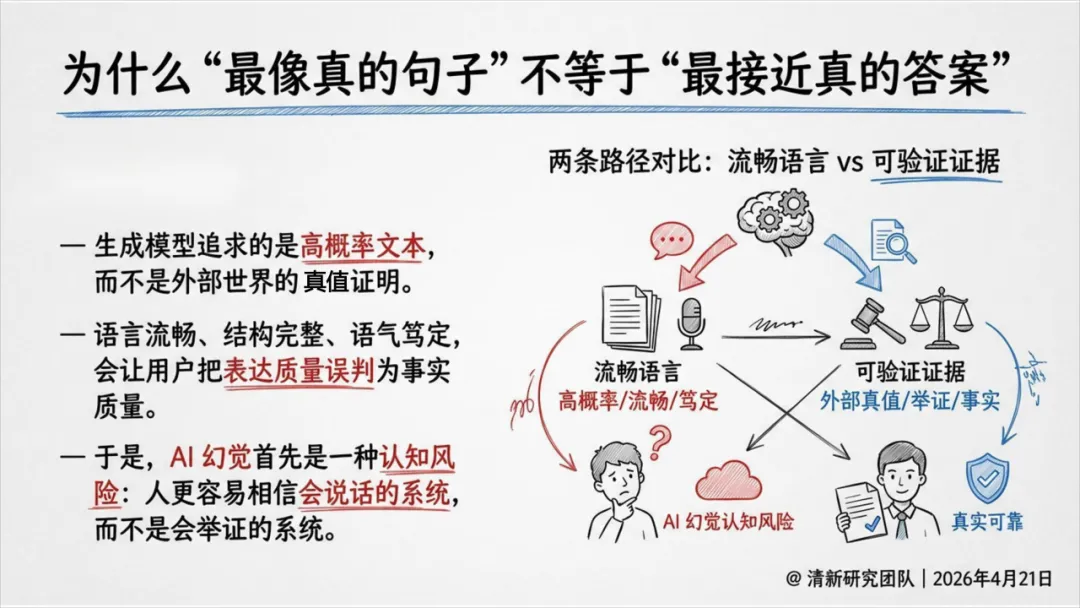
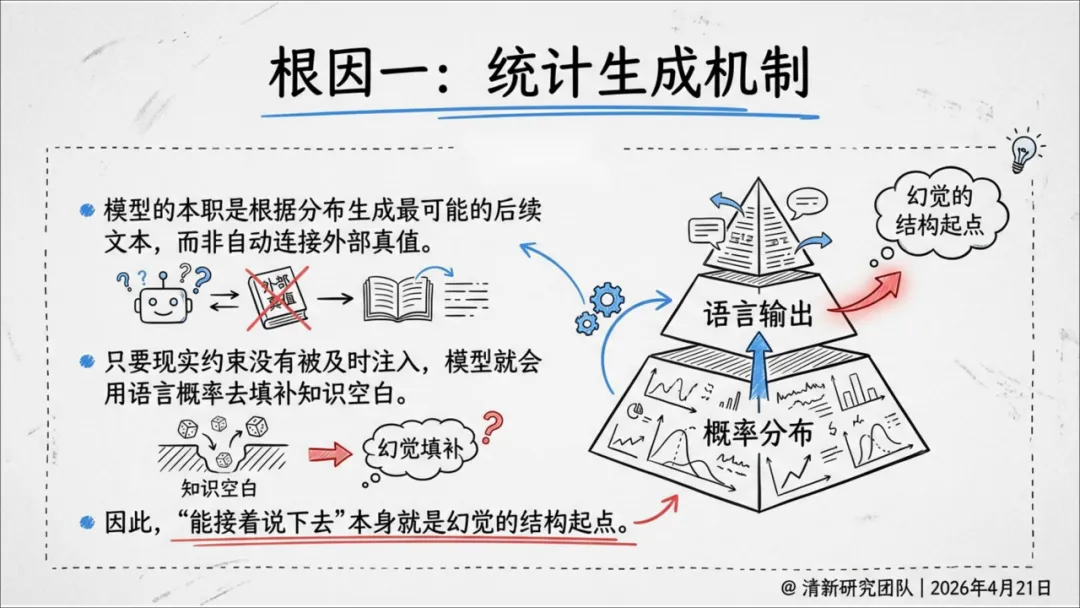
根因一:统计生成机制。 模型的本职是根据概率分布生成"最像真的"后续文本,而不是连接外部真值。只要现实约束没有被注入,模型就会用语言概率去填补知识空白。"能接着说下去"本身就是幻觉的结构起点。
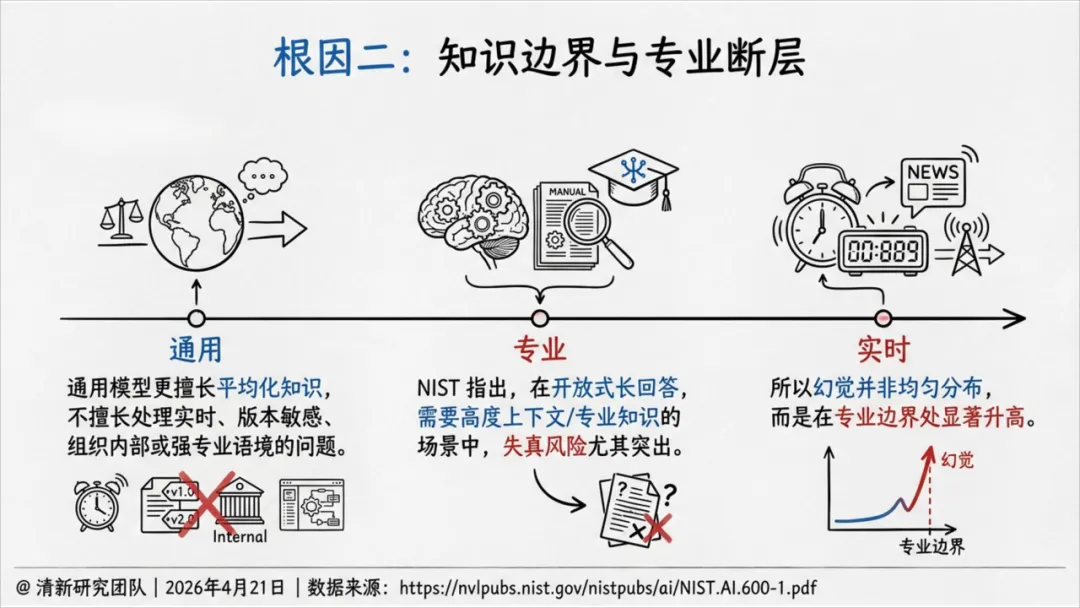
根因二:知识边界与专业断层。 通用模型擅长平均化知识,不擅长处理实时、版本敏感、需要高度专业语境的问题。幻觉在专业边界处显著升高。
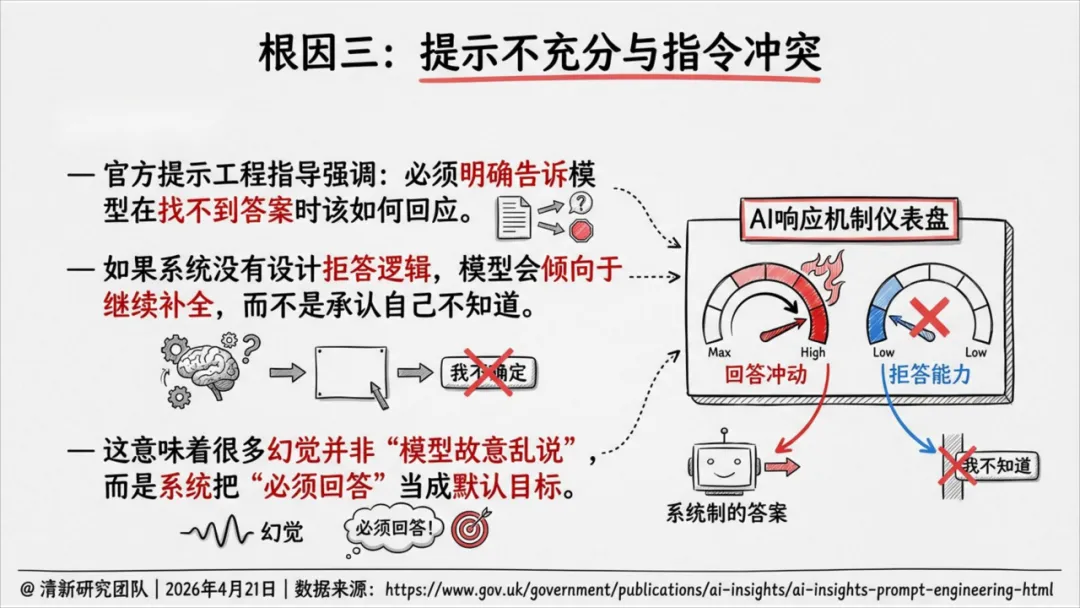
根因三:提示不充分与指令冲突。 如果系统没有设计拒答逻辑,模型会倾向于"继续补全"而不是承认自己不知道。很多幻觉并非"模型故意乱说",而是系统把"必须回答"设成了默认目标。
根因四:组织对速度与完整感的偏好。 很多团队把"回复快、看起来全、语气像专家"当作优秀体验,却忽略了可验证性。越像"聪明助手",越可能在关键时刻给出不该被执行的答案。
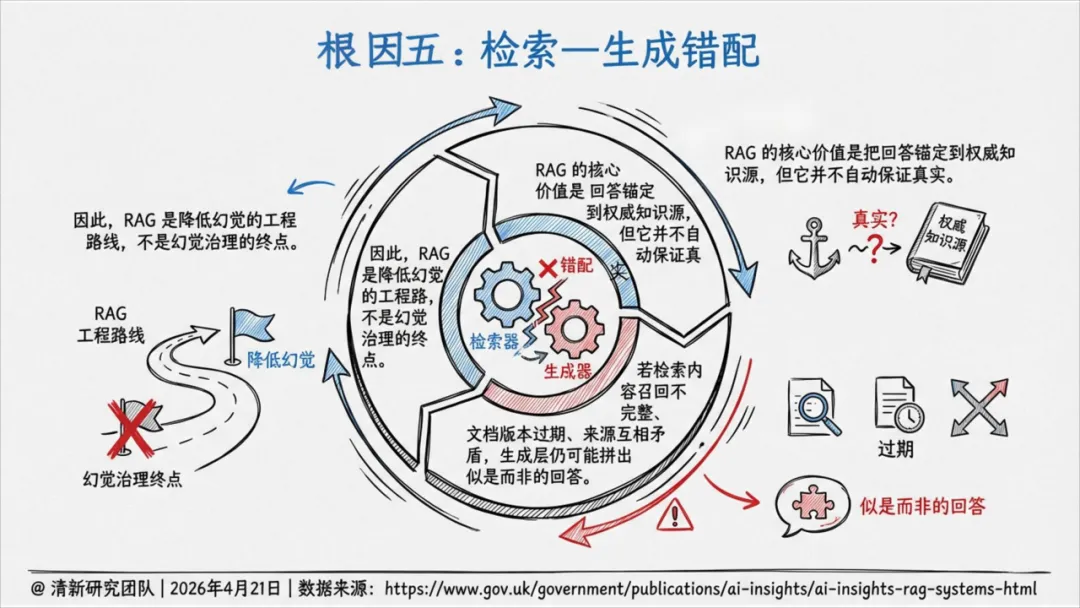
根因五:检索—生成错配。 RAG(检索增强生成)的核心价值是把回答锚定到权威知识源,但它并不自动保证真实。检索内容召回不完整、文档版本过期、来源互相矛盾时,生成层仍可能拼出似是而非的回答。
三、真实世界案例:幻觉已经造成后果
这是报告最扎实的部分,用五个真实案例说明幻觉如何从"屏幕上的错误"变成"组织中的风险"。
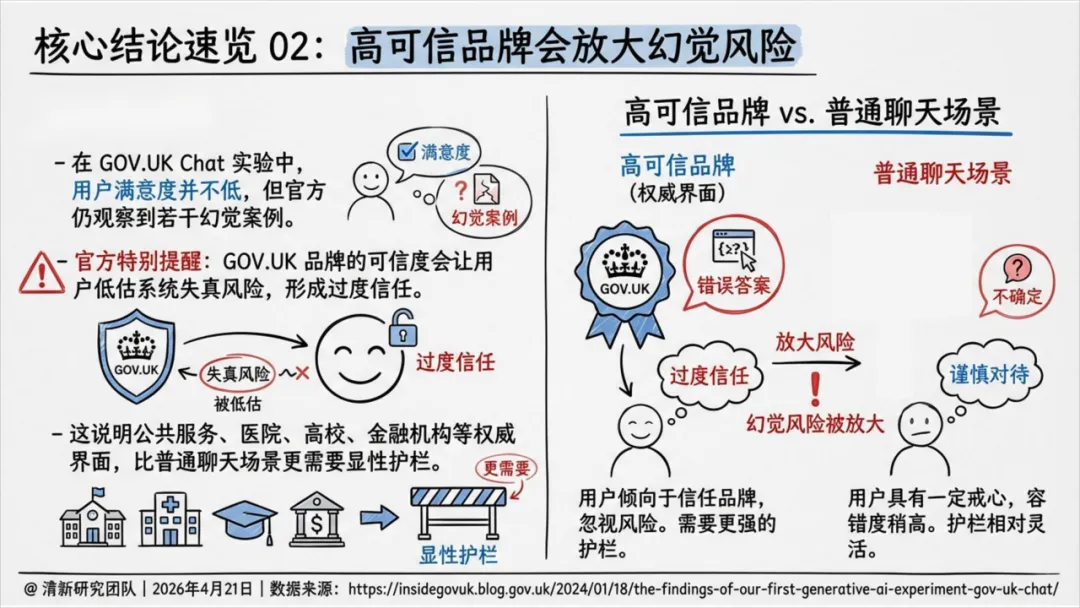
案例一:GOV.UK Chat——品牌会放大幻觉风险
英国政府官方AI聊天实验,近70%用户认为回答有用,但官方同时观察到若干幻觉案例。问题出在哪?GOV.UK的品牌可信度让用户低估了系统失真风险,形成过度信任。
报告的结论很尖锐:权威界面(政府、医院、高校、金融机构)不是风险缓冲器,而是风险放大器。用户倾向于信任品牌,反而会忽视风险,需要更强的显性护栏。
案例二:美国联邦机构——采用加速,治理滞后
GAO报告显示,2024年11个联邦机构报告的生成式AI用例为282个,较2023年的32个约增长9倍。但同期机构面临的难题包括合规约束、预算资源和使用政策维护。
当采用加速而治理滞后时,幻觉问题就会从试验风险变成运营风险。
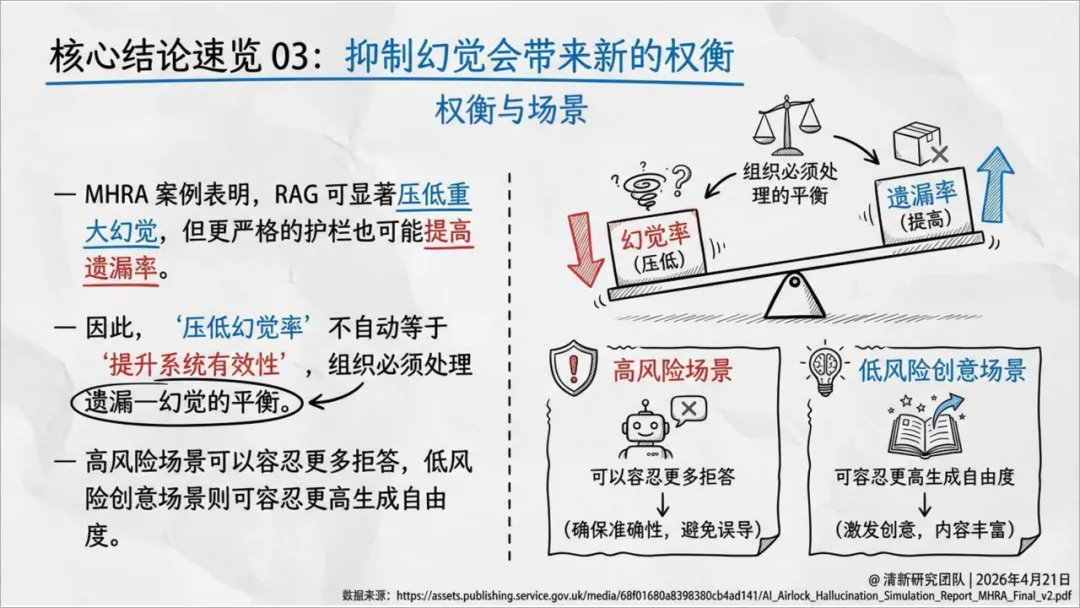
案例三:MHRA(英国药品和健康产品管理局)——遗漏有时并不比幻觉更轻
MHRA用RAG增强的GPT模型做临床问答测试:基线GPT模型在333次测试中出现了6次重大幻觉(约1.8%),但SmartGuideline版本出现了35次遗漏(约10.5%)。
这个跷板效应非常关键:收紧护栏能压低幻觉率,却可能抬高遗漏率、拒答率和信息不全率。 医疗场景中,如果系统为了安全而频繁不回答,临床人员可能错过关键提示;如果为了显得全面而继续补全,则可能直接误导临床决策。
案例四:教育场景——学生面对的是知识还是错觉
英国教育指导明确提醒:生成式AI会给出荒谬、错误或虚假但像事实一样的话。问题不只是正确率,而是知识习得方式是否被错误地重塑——如果学生先接受"流畅但未经核验的答案",批判性阅读与证据意识都会被削弱。
案例五:网络安全场景——从文本幻觉走向系统边界失守
NCSC(英国国家网络安全中心)提醒:LLM既不稳健区分"指令"和"数据",又易受提示注入和数据投毒影响。当模型被嵌入工作流、邮箱、表单、Agent和外部系统时,幻觉就会升级为边界失守。
提示注入(Prompt Injection)为什么特别危险?因为它不是SQL注入的简单翻版——只要Agent系统摄入了外部文本,就可能把恶意内容当作新指令执行。Agent场景的核心不是"回复内容像不像人",而是"系统边界能不能守住"。
四、六层治理栈:从"能不能回答"到"出了错谁负责"
报告第四部分给出了迄今最完整的幻觉治理工程框架——六层治理栈,从底层到顶层依次是:
第一层:任务分级。 先画任务风险地图——哪些任务允许模型直接回答?哪些必须附证据?哪些需要人工审核?哪些禁止自动执行?只有先做任务分级,才知道护栏强度该放在哪里。
第二层:知识锚定。 优先使用受控知识源、版本化文档、内部知识库与RAG,让答案尽量回到可验证证据上。英国RAG指导认为,RAG的重要价值不是让回答更长,而是让回答更能被追溯。
第三层:生成约束。 明确规定"答不出来时如何回应",是避免响应链路幻觉的重要措施。生成约束的关键不在于提示写得多华丽,而在于是否把边界写清楚。
第四层:验证校正。 对高风险输出做事实校验、引用核对、规则匹配、结构化比对和异常检测。【正式文稿】与【对外材料】,要求关键事实必须能回链到【原始来源】。
第五层:上线监控与日志。 记录提示、模型版本、检索来源、回答文本、人工修订、用户反馈和异常案例。没有日志,组织就无法回放错误链条,也无法判断问题出在模型、检索、提示还是流程。
第六层:责任治理。 最后一道护栏永远不是模型,而是组织如何分配权力与责任。明确业务owner、模型owner、审核责任人、供应商边界、升级通道与事故响应机制。
报告特别强调:在Agent场景中,抑幻觉工程必须和安全工程合并。 "说错"和"做错"之间的距离被大幅缩短,系统需要具备最小权限、外部内容标注、关键动作确认、确定性校验和可熔断设计。
五、五个原创概念:把幻觉讨论变成组织语言
报告第五部分提出了五个原创概念,用于把零散的幻觉讨论压缩成更适合组织理解和执行的风险语言:
概念一:概率真相陷阱。 把"最像真的输出"误认为"最接近真实的答案"。语言质量越高,用户越容易把表达能力误判为事实能力。治理方法是把证据、来源和不确定性显式前置。
概念二:引用幻影链。 模型先伪造来源,再用脚注、链接、判例名把缺失证据包装成"已核验链条"。一条伪引会在PPT、备忘录、论文和法律材料中继续传播。治理方法是来源必须能回链到原文,关键场景禁止无检索生成参考文献。
概念三:低置信高伤害区。 模型自己并无稳定依据,组织却让它介入高后果任务,形成"模型低置信、用户高依赖"的危险带。对健康、安全、权利、财务、合规与公共影响类任务,要么禁用生成式AI单独处理,要么把它降格为辅助工具。
概念四:遗漏—幻觉跷板。 收紧护栏能压低幻觉率,却可能抬高遗漏率。不同场景必须配置不同参数值,不能用一套参数治理所有任务。
概念五:责任折返门。 组织表面设置了human-in-the-loop,但人工复核既不充分也不可证明,最后既没控住风险,也没形成责任归属。人工复核必须有意义、可抽检、可追责,否则只是一种"责任表演"。
六、H3M成熟度模型:从"会用模型"到"驾驭模型"
报告提出了幻觉治理成熟度模型(H3M),分为五个等级:
- L1 试用级:个人经验驱动,零星试用,无系统治理
- L2 规则级:开始积累规则,有基本提示工程和输出核查
- L3 流程级:流程标准化,有任务分级、人工复核节点和日志留痕
- L4 工程级:工程自动化,六层治理栈部分或完整落地,有持续监测
- L5 治理级:制度能力,幻觉治理嵌入组织制度和责任分配
成熟度越高,组织越能把幻觉从"偶发事故"转化为"可度量运营风险"。
七、行动路线图:30-60-90天
报告最后给出了可执行的行动路线图:
30天内: 先找"低置信高伤害区"——标出哪些输出会进入正式文稿、数据库、审批流程或自动执行链。先识别最危险的任务,再谈模型扩展。
60天内: 为高风险问答场景接入受控知识源、版本化文档与RAG;把"找不到就拒答""必须附来源""引用不可伪造"写进系统指令与产品规则;把错误反馈入口产品化,形成可追踪的工单和案例库。
90天内: 明确谁审、审什么、怎么升级、如何留痕,避免责任折返门;对关键输出建立抽检、复盘、回放与红队测试流程;让每次幻觉事件都能被解释、被归因、被修正。
结语: 报告的最终判断——未来真正有竞争力的组织,不是让模型看起来无所不知,而是让模型在不知道时停下来、在高风险时退后一步。 幻觉治理的对象不是一句错话,而是一整条从生成到执行、从证据到责任的链条。当证据链、流程控制、审计机制与责任分配同时嵌入,组织才算从"会用大模型"迈向"驾驭生成式AI"。
本文基于清华大学清新研究团队《AI幻觉深度研究报告》撰写,更多详细内容请查阅原文。
以下是内容节选↓↓↓ 文末点击链接免费下载pdf,扫二维码加入交流群


AI科普馆:打开AI世界之窗

