语言越流畅,越容易骗过你的判断力
你有没有遇到过这样的情况:向AI提问,它用自信满满、逻辑清晰的语气回答了一大段,你几乎要照单全收,结果一查——错了?
你不是一个人。
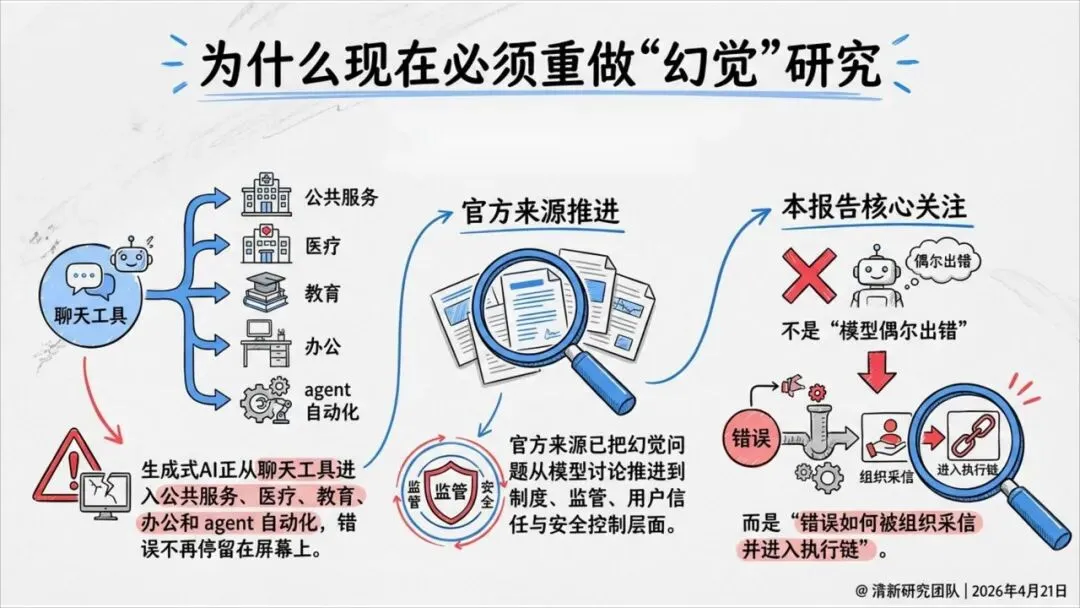
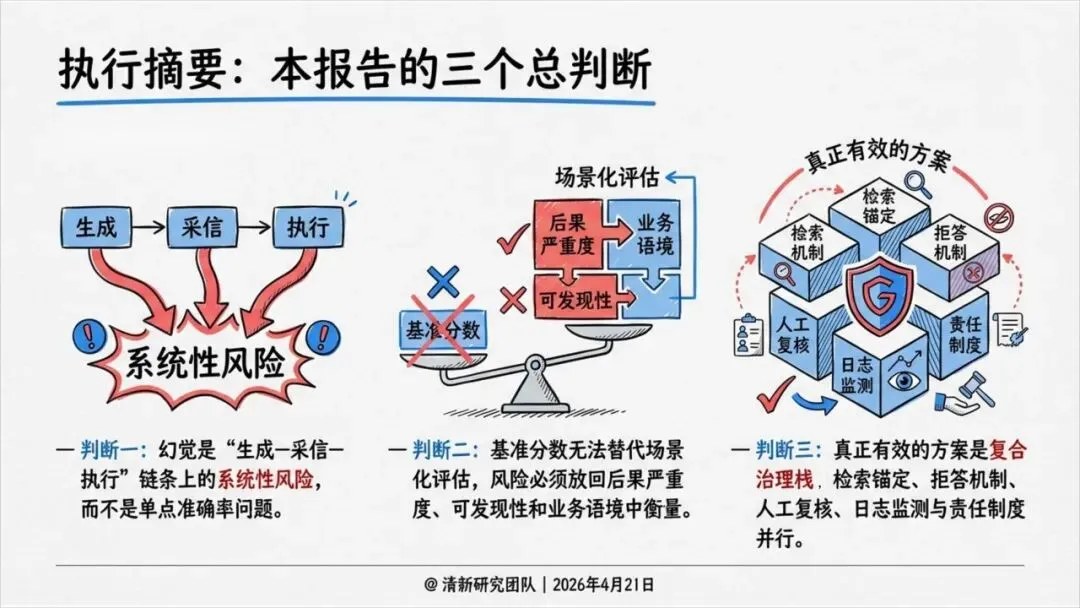
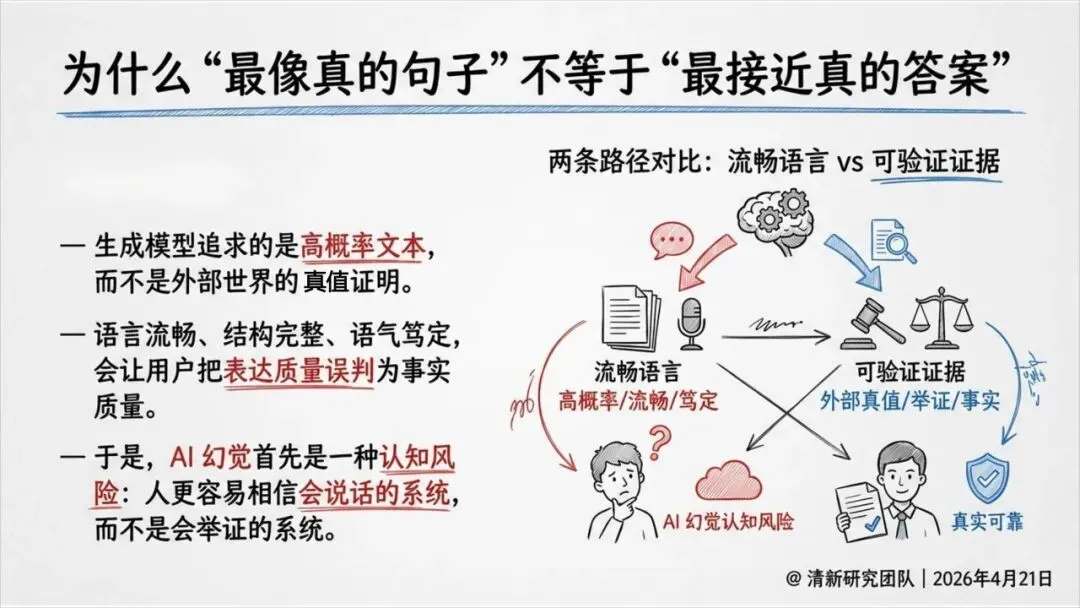
最近一份基于政府与监管机构来源的《AI幻觉深度研究报告》指出:幻觉不是“偶尔说错一句话”,而是从生成到采信到执行的系统性风险。更可怕的是,语言越像专家,用户越容易信以为真。
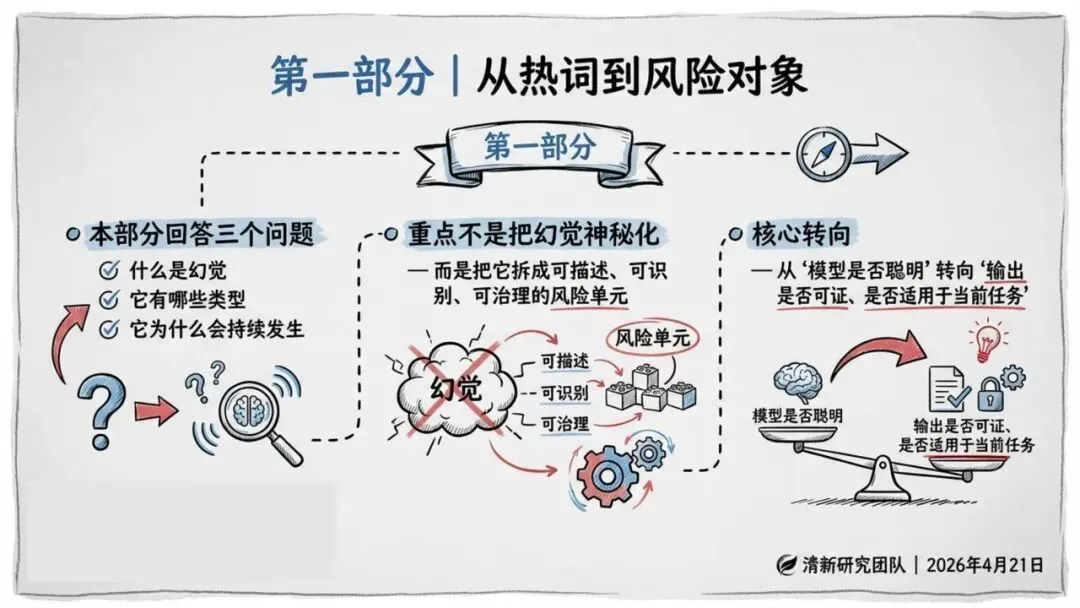
为什么AI会“一本正经地胡说八道”?
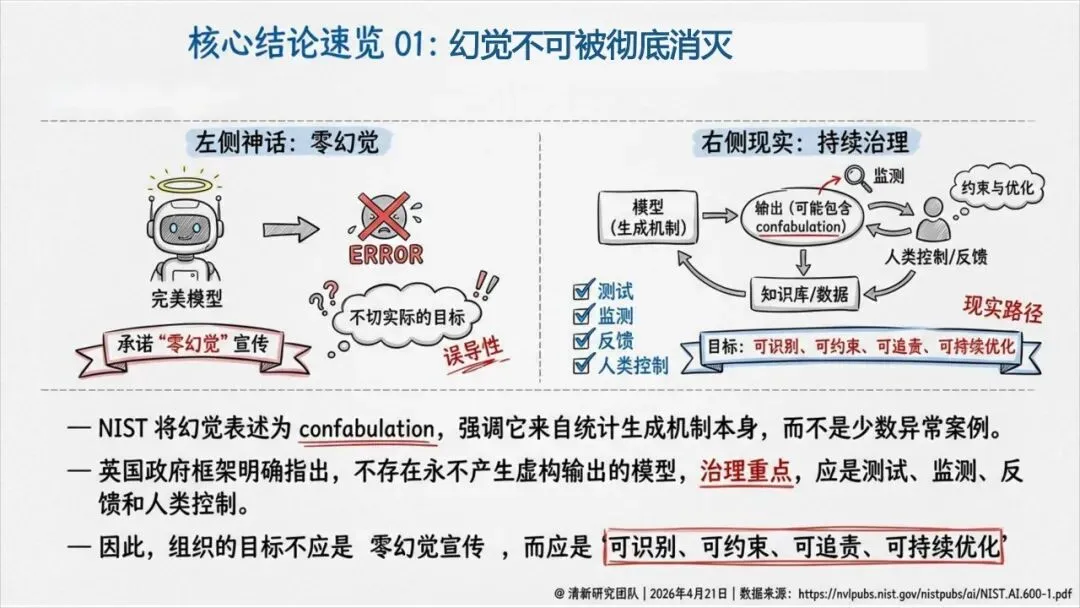
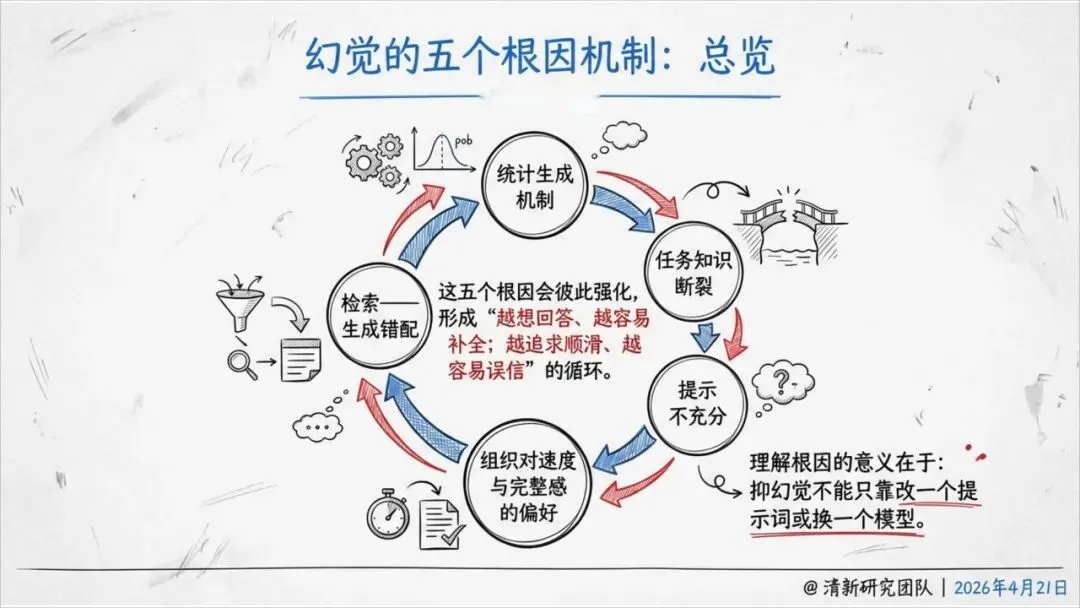
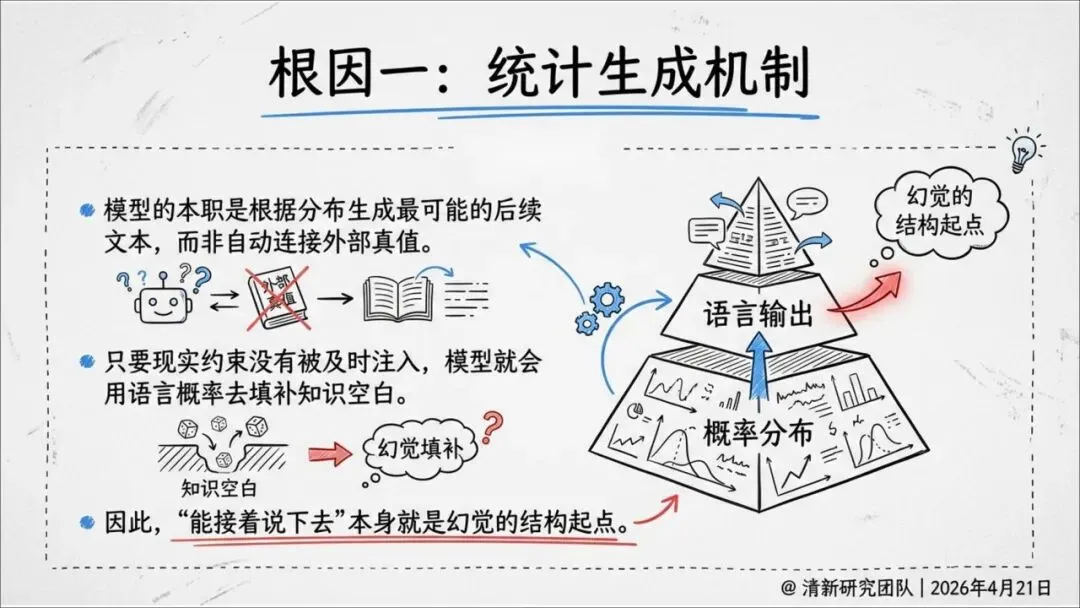
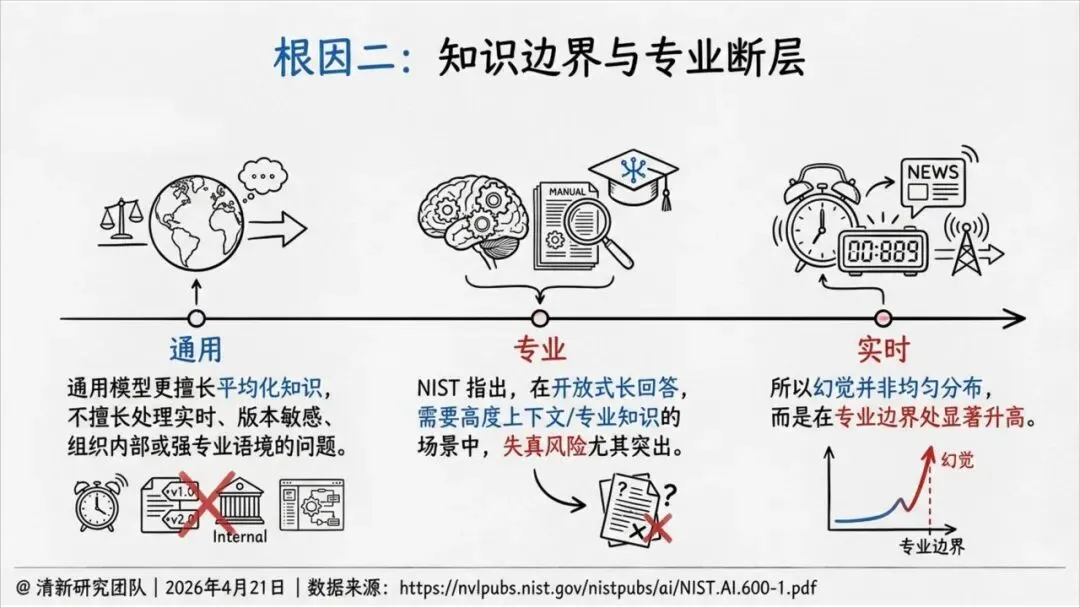
报告揭示了一个根本原因:AI的本质是预测最可能出现的下一个词,而不是证明外部世界的真值。
换句话说,它追求的是“像真话”,而不是“是真话”。
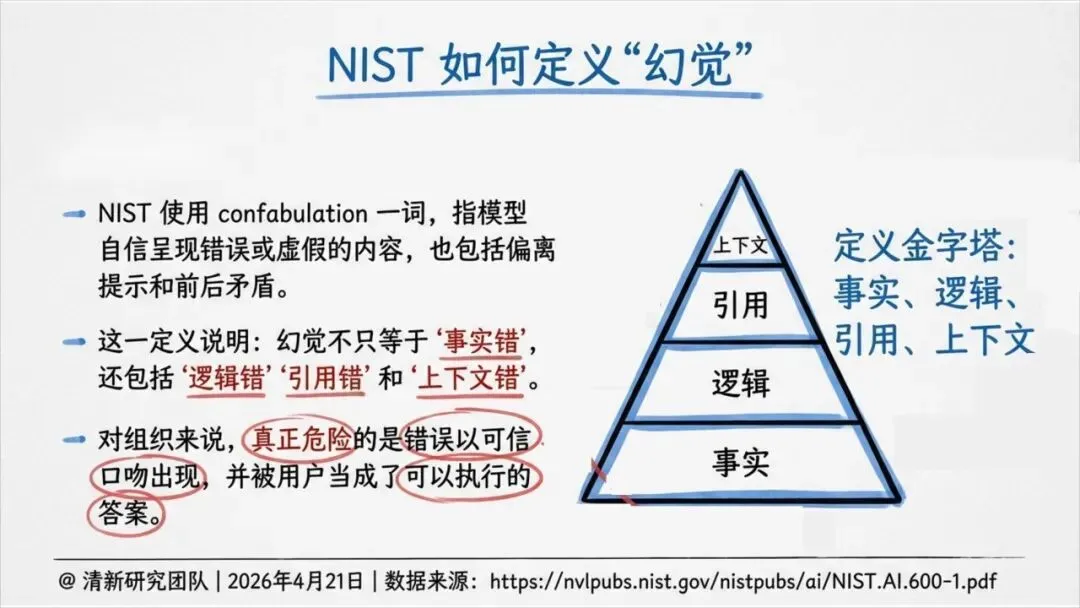
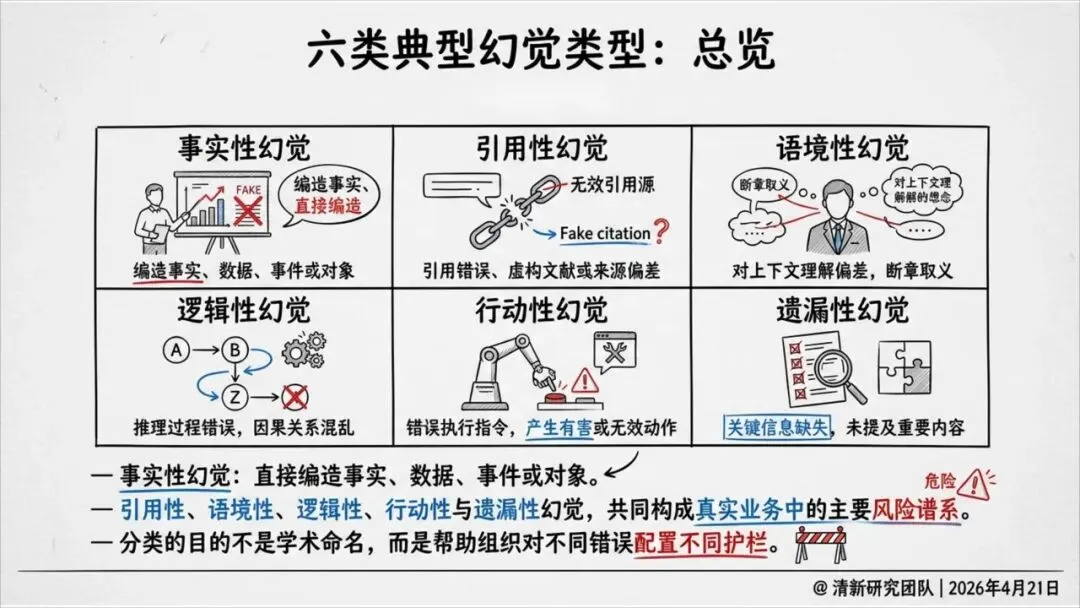
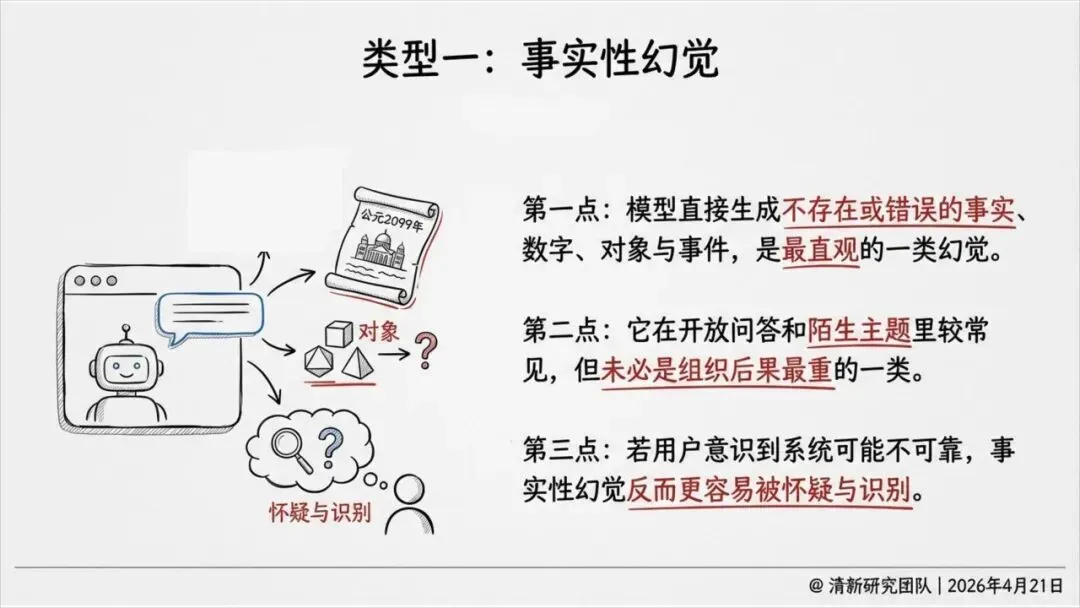
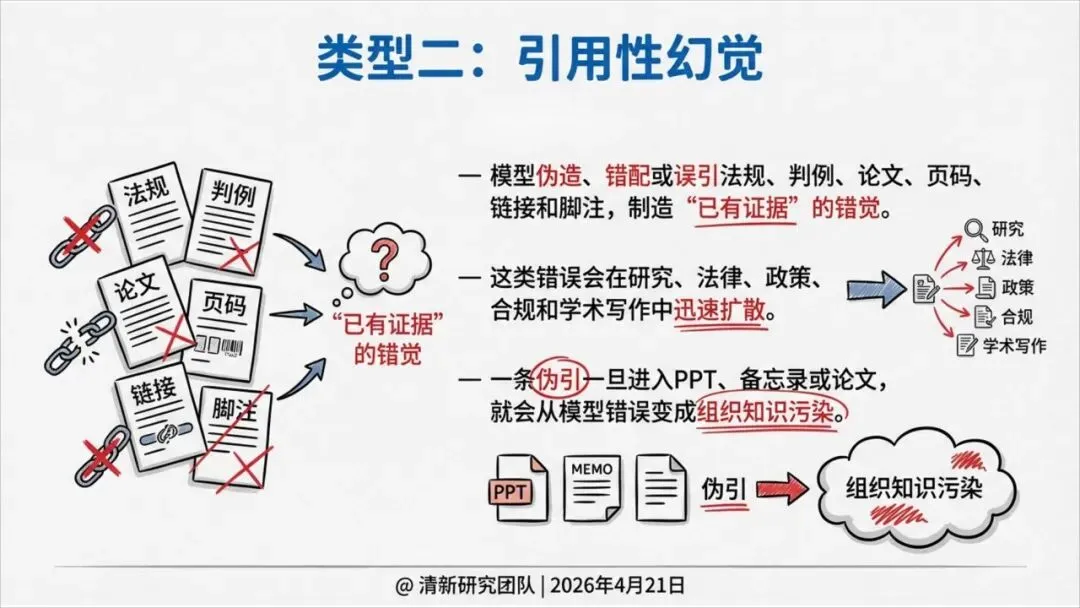
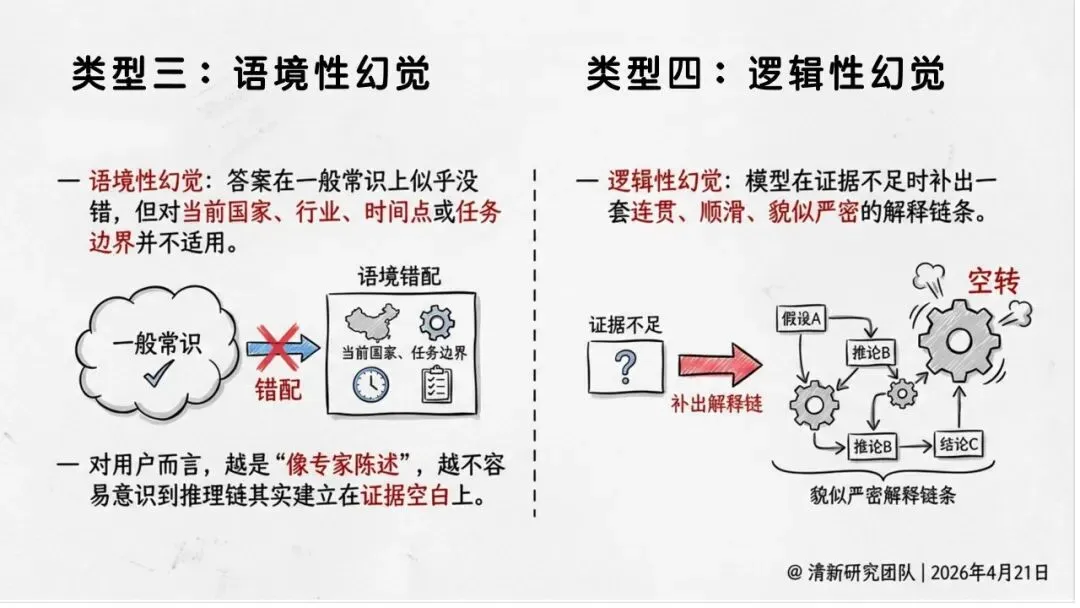
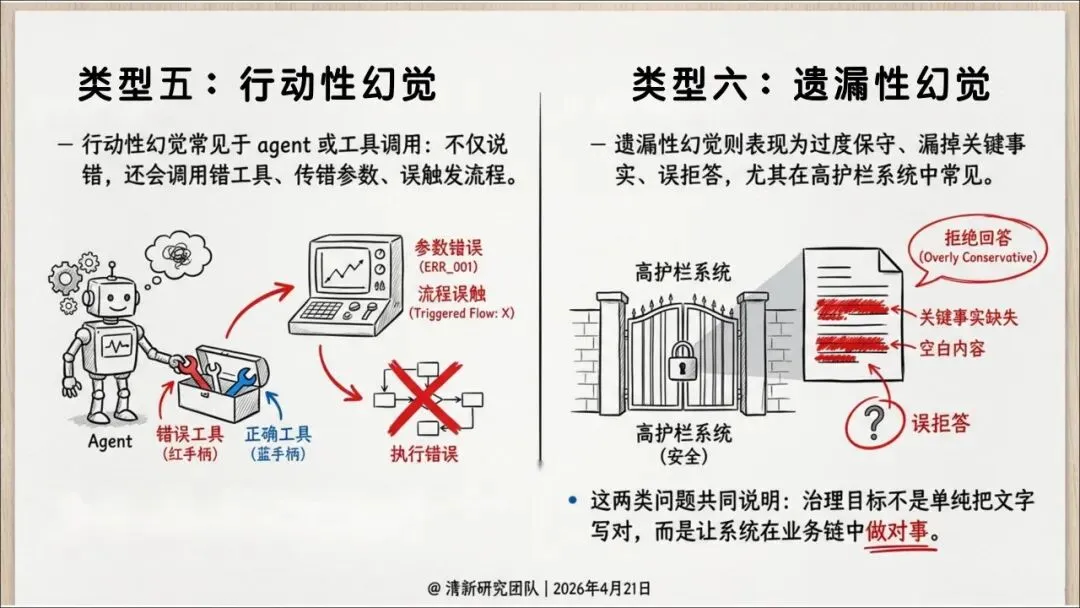
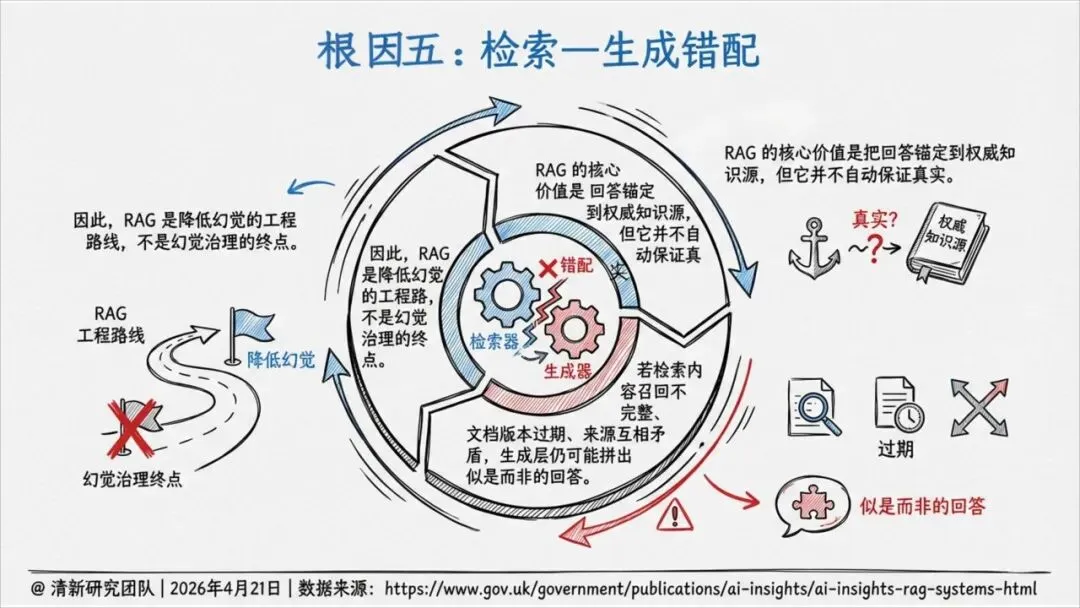
这就导致了六种幻觉——不只是事实错误,还包括伪造引用、逻辑断裂、语境错位、执行错误等。其中,引用性幻觉尤其危险:AI会伪造法条、判例、论文页码,把虚假证据包装得像模像样,一旦被写进PPT、备忘录或报告,就成了组织知识的污染源。
政府、医院、银行用AI,风险更大?
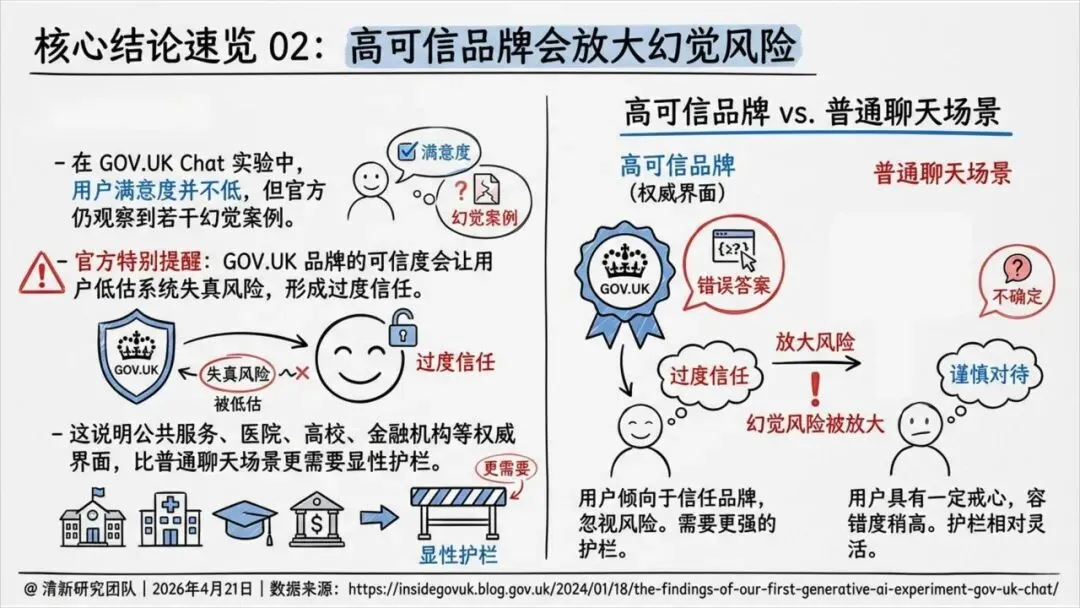
是的,恰恰因为品牌可信度高。
报告以英国 GOV.UK Chat 为例:用户满意度近70%,但官方仍发现了若干幻觉案例。官方特别提醒:用户因为信任GOV.UK品牌,反而低估了系统出错的可能。
也就是说,权威界面不是风险缓冲器,而是风险放大器。越是公共服务、医疗、金融场景,越需要显式护栏。
怎么办?三个关键动作
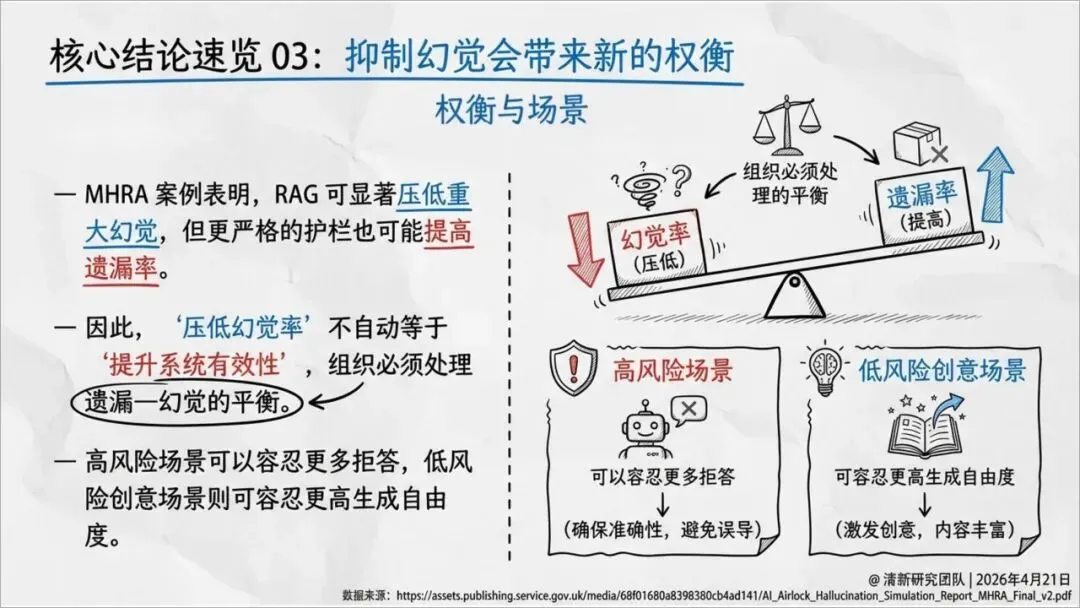
报告提出了一套“抑幻觉工程”框架,最核心的三条是:
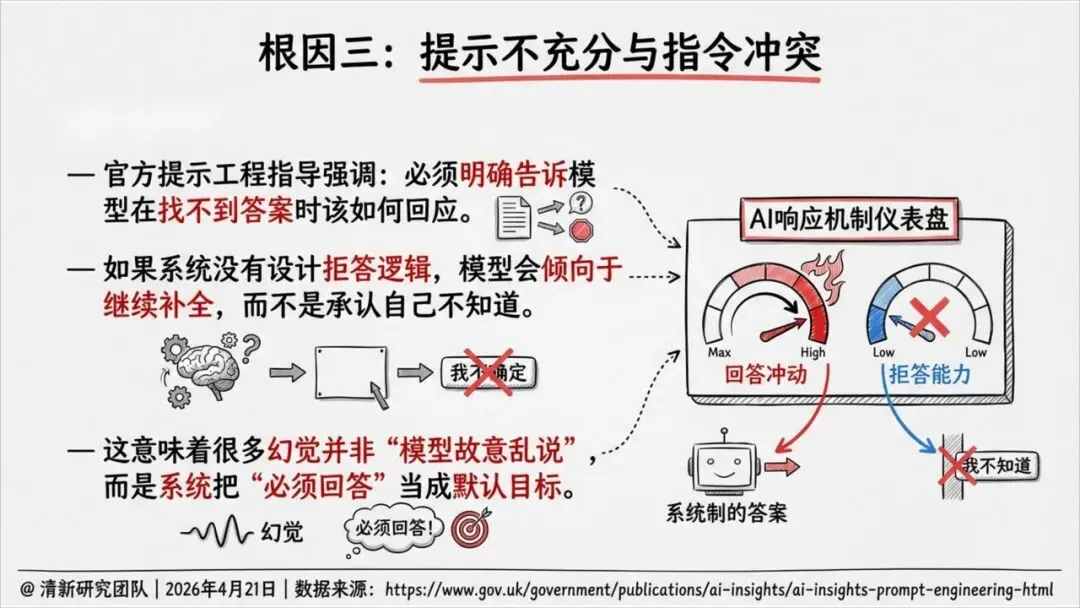
第一,允许AI说“不知道”。 一个不能拒答的系统,必然会用语言填补空白。对医疗、法律、政策等高风险场景,“不答”远胜“乱答”。
第二,人工复核必须有意义。 不是“有人点个确认”,而是有否决权、有时间、有标准、有留痕。
第三,高风险任务直接禁用或降格使用。 涉及健康、安全、权利、财务、法律后果的场景,不应让AI单独形成最终输出。
写在最后
报告中有句话值得反复读:真正的分水岭,不是会不会用模型,而是能不能驾驭模型。
未来有竞争力的组织,不是让AI无所不知,而是让它在不知道时停下来、在高风险时退后一步。
你信AI,AI才危险。你保持判断力,AI才只是工具。

清华信息
清华大学2025人工智能治理年度报告迈向可衡量的AI治理19页.pdf
清华大学2025年AIGC发展研究报告4.0版152 页.pdf
清华大学&华为:AI终端白皮书-AI与人协作、服务于人.pdf
