点击蓝字 关注我们



你有没有想过,为什么ChatGPT能写诗、能编程,但让一个机器人帮你倒杯水,它却可能把杯子捏碎?
这不是因为算法不够强,而是因为——它缺少“动手”的经验。
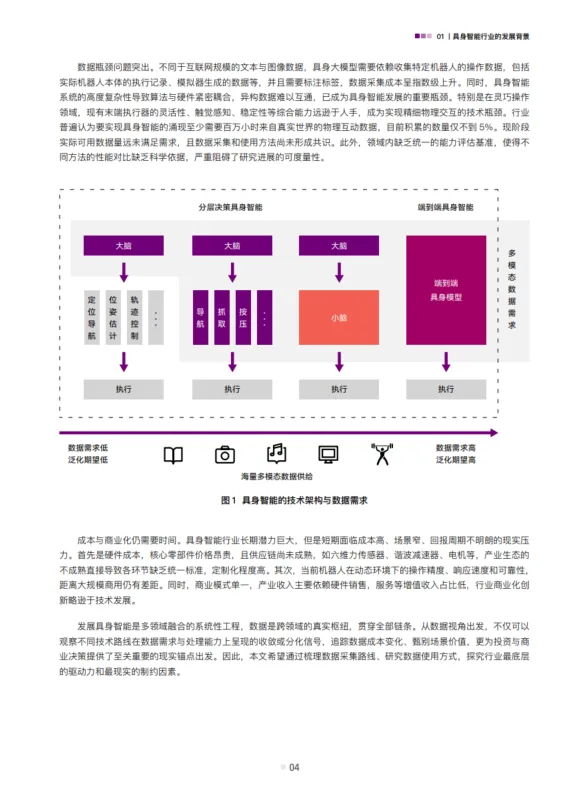
这份由国先中心发布的《2026具身智能数据行业研究白皮书》,首次系统揭示了机器人“学不会”的秘密:数据,才是具身智能真正的瓶颈。
?没有高质量数据,机器人永远只会“发呆”
1
核心要点
01 具身智能:给AI装上身体
我们常说的人工智能,大多活在屏幕里。
而具身智能,是让AI拥有一个“身体”——可以是人形机器人、机械臂、机器狗,去真实世界里感知、决策、行动。
简单说:传统AI:你说“倒水”,它写一段倒水的代码。具身智能:它真的拿起水壶,找准杯子,控制力度,稳稳地倒进去。
但问题是——它怎么学会这些?
02 机器人不会“天生会倒水”
人类孩子通过无数次尝试学会抓杯子,机器人也一样。
但它不能像我们一样“试错”——试一次摔一次,成本太高。
所以,目前主流的方法是:人类手把手教。
白皮书总结了三类“教学方式”:
1️⃣ 遥操作:像提线木偶
人类通过操控杆、VR设备、外骨骼,远程控制机器人做动作。
? 数据质量高
? 成本高、效率低,一位专家一天只能采几百条数据
2️⃣ 动作捕捉:让人“穿”成机器人
人类穿上动捕服,做各种动作,系统记录下每一个关节的角度、力度。
? 数据真实、自然
? 设备贵、数据迁移难
3️⃣ 视频学习 & 合成数据:让机器人“看视频自学”
机器人看人类视频,模仿动作。
? 数据量大、成本低
? 精度差,容易学歪
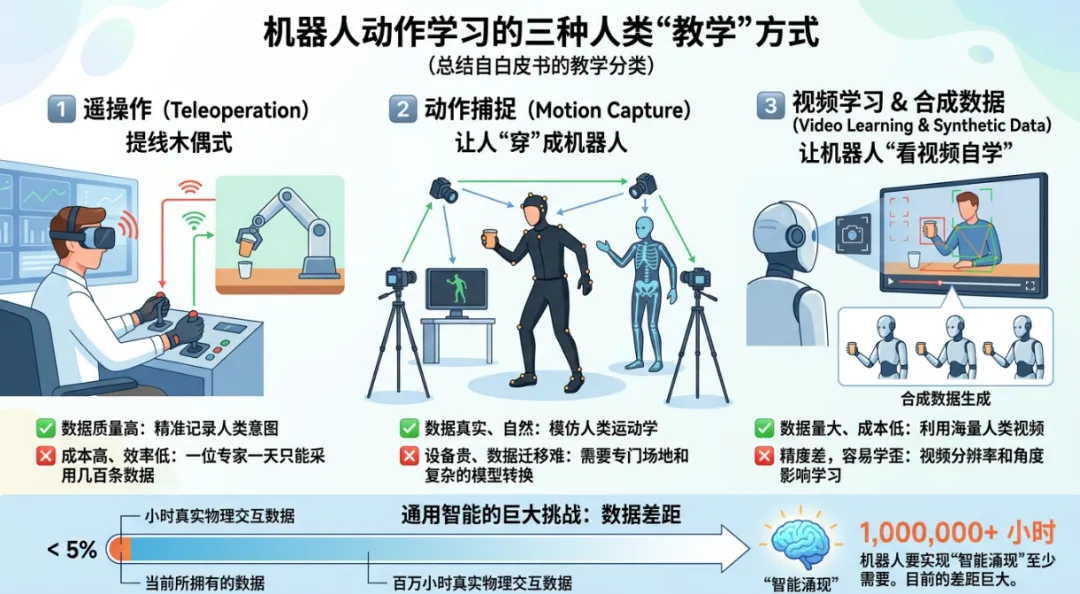
目前,行业公认:机器人要实现“智能涌现”,至少需要百万小时的真实物理交互数据,而现在我们连5%都不到。
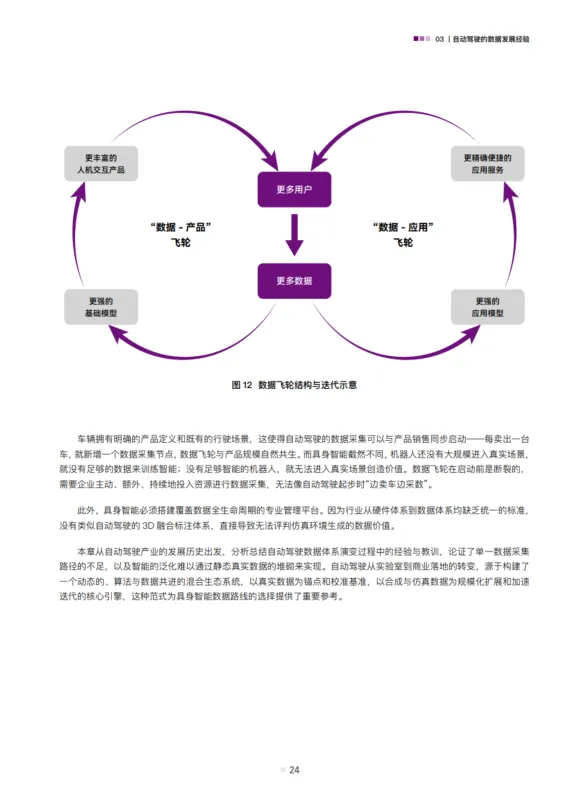
03 自动驾驶走过的路,机器人正在重走
白皮书指出,自动驾驶本质上就是一种“轮式具身智能”。
它曾经历过同样的痛苦:
? 早期依赖高精地图 → 成本高、泛化差
? 后来转向“仿真优先,真机验证” → 用虚拟世界训练,用真实世界校准
这条路,机器人正在复制:
先在仿真环境里摔一万次,再在真实世界里微调。
? 但机器人比车更难训练,因为它要面对的不是结构化道路,而是混乱的家庭、仓库、餐厅。
04 数据之争:谁才是未来的“黄金标准”?
目前,行业里出现了两条截然不同的路线:
✅ 路线A:真机遥操作
数据精度最高,但成本极高,难以规模化。
✅ 路线B:无本体数据采集
让人类带着轻量化设备在真实环境中操作,数据与机器人本体解耦。
? 规模大、成本低
? 精度差、工程难度高
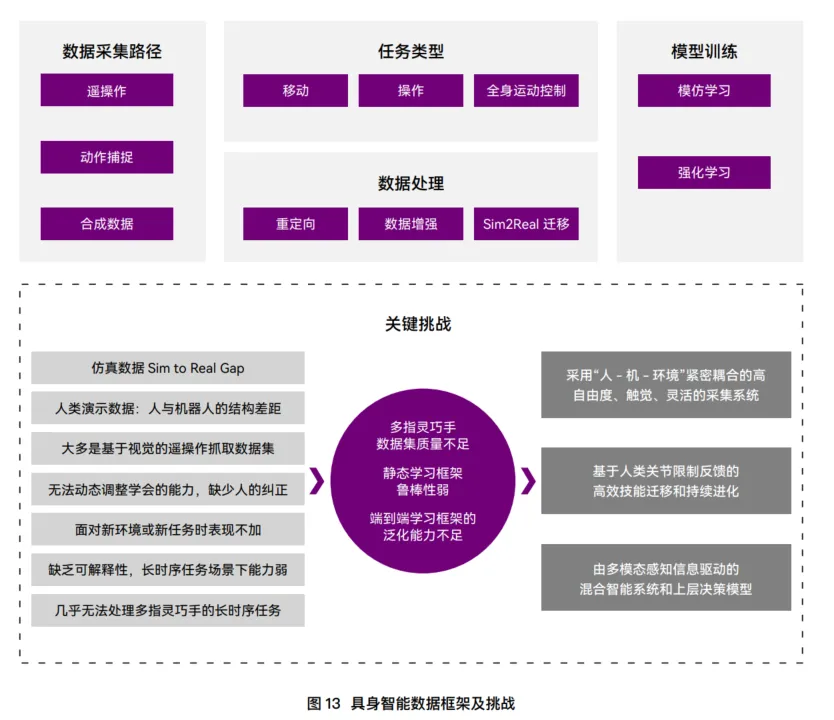
? 白皮书判断:未来不是二选一,而是混合使用。真机数据做“精调”,无本体数据做“预训练”。
05 商业化的三条路径
具身智能不会一夜爆发,而是分阶段演进:
✅ 阶段1:少量数据,做原型
用几十条演示数据,让机器人在固定场景里完成单一任务,比如3C产线上的螺丝锁付。
? 挑战:成本高、稳定性差,ROI难算。
✅ 阶段2:聚焦场景,大量数据迭代
在仓储、清洁、装配等垂直领域,建立数据工厂,规模化采集。
? 国内已建成20多个机器人训练场,总面积超4万平米。
? 挑战:数据孤岛、标准缺失。
✅ 阶段3:海量数据,实现通用智能
未来,机器人能力将“云化”:
? 云端训练技能
? 边缘侧实时调度
? 本体标准化、低成本
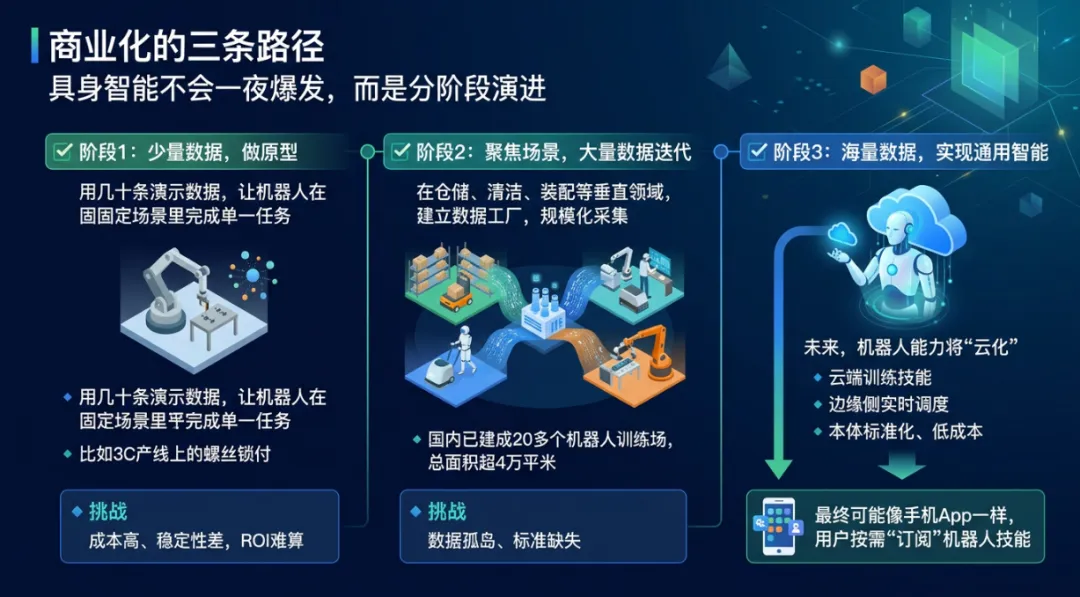
最终可能像手机App一样,用户按需“订阅”机器人技能。
06 机会与风险
✅ 机会点
? 感知技术:触觉、力觉、视觉融合,成为新入口
? 数据治理平台:采集、标注、清洗、存储,全生命周期管理
? 失败数据:负面样本比成功演示更有价值
? 世界模型:让机器人“想象”未来,提前规避错误
✅ 风险点
? 技术路线尚未收敛,可能被颠覆
? 数据“可用性”验证成本高,失败即沉没成本
? 安全、隐私、伦理监管趋严
? 商业化周期远超预期,资本耐心有限
总结
具身智能,不是ChatGPT式的“一夜奇迹”。它更像一场马拉松,数据是每一步的脚印。
我们正在见证的,不是一场技术革命的开端,而是人工智能从数字世界,真正走向物理世界的历史性跨越。
? 下一次,当你看到一个机器人稳稳地端起一杯水,请记住:它背后,是百万条数据、无数次失败、和一群为之努力的工程师。
(只截取部分报告,需要查看全文,见文末链接可免费下载资料)
2
报告原文




















报告来源:国际先进技术应用推进中心
篇幅有限,需要查看报告完整版可私信“2026具身智能数据行业研究白皮书",小z助手会自动回复链接,也可点击下方链接自行下载,资料均免费获取。
如果本篇文章对您有帮助或有价值,记得点赞分享给更多人,感谢您的支持~

往期回顾

AI 瞭望星球
站在未来最前沿,
探索智能时代的星辰大海!
联系邮箱丨biz@steoak.com