来源:三个皮匠 2026年3月
获取原文关注公众号
当ChatGPT让我们见识了AI的“聪明”,一场更深刻的变革正在发生——让AI拥有身体,走进现实世界。
2026年3月发布的《具身智能数据行业研究白皮书》首次从数据视角全面拆解了这个正在爆发的行业。报告直指一个核心结论:算法是灵魂,硬件是躯体,但只有多模态的物理交互数据,才是驱动具身智能跨越“GPT-3.5时刻”的唯一燃料。


一、行业站在爆发前夜:全球抢滩,数据成最大卡点
1. 具身智能:AI从“会思考”到“能行动”的终极跨越
具身智能(Embodied Intelligence)是AI与机器人融合的前沿方向。它的核心思想很简单:真正的智能,离不开物理实体与环境持续互动。
大语言模型充当“认知大脑”,负责理解任务、进行推理;机器人本体则成为“行动载体”,把想法变成动作。两者结合,才有了能理解开放指令、适应真实环境的通用智能体。这,正是通往AGI(通用人工智能)的关键路径。
2. 全球政策+资本双重加码,中国跻身第一梯队
具身智能的战场,早已不是实验室里的科研竞赛,而是国家战略与资本博弈的交汇点。
政策层面:美国有《国家机器人计划》,欧盟率先出台《人工智能法案》,中国则在2025年首次将“具身智能”写入政府工作报告,列为未来产业核心方向。
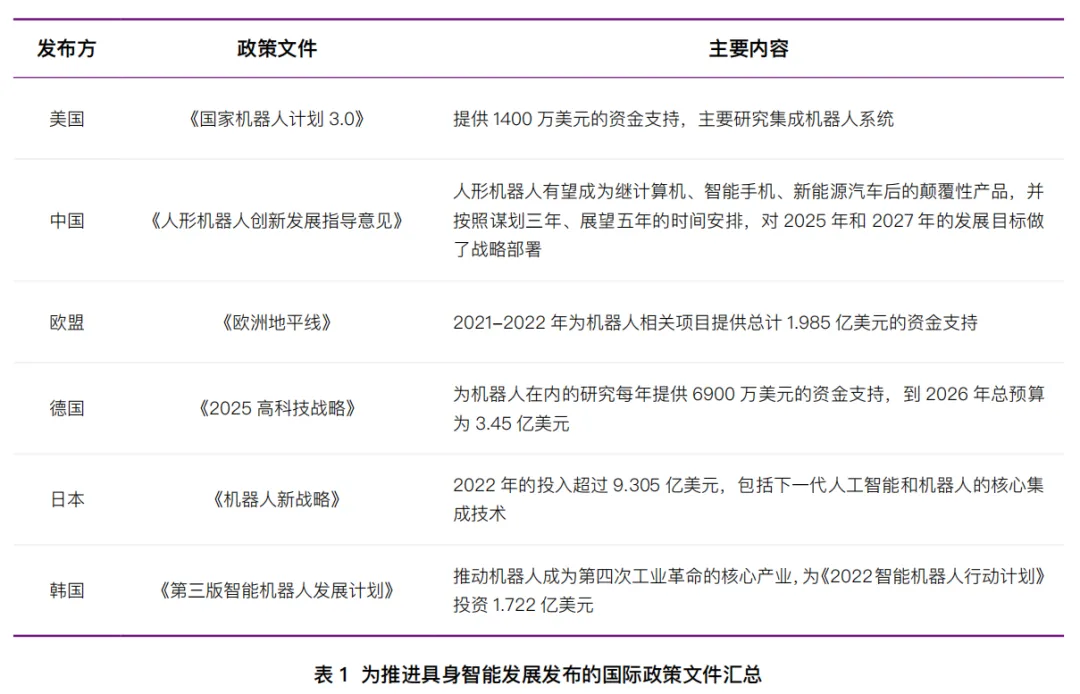
资本层面:截至2025年9月,国内具身智能领域融资已超300亿元。谷歌、微软、英伟达、特斯拉全线入局,人形机器人成为最热的焦点。
3. 三大核心痛点,数据瓶颈最致命
行业热闹归热闹,真正的挑战也很现实:
技术未收敛:VLA(视觉-语言-动作)模型是主流,但动作控制、软硬件协同仍问题重重;
硬件成本高:核心零部件昂贵,供应链尚未成熟,定制化程度高;
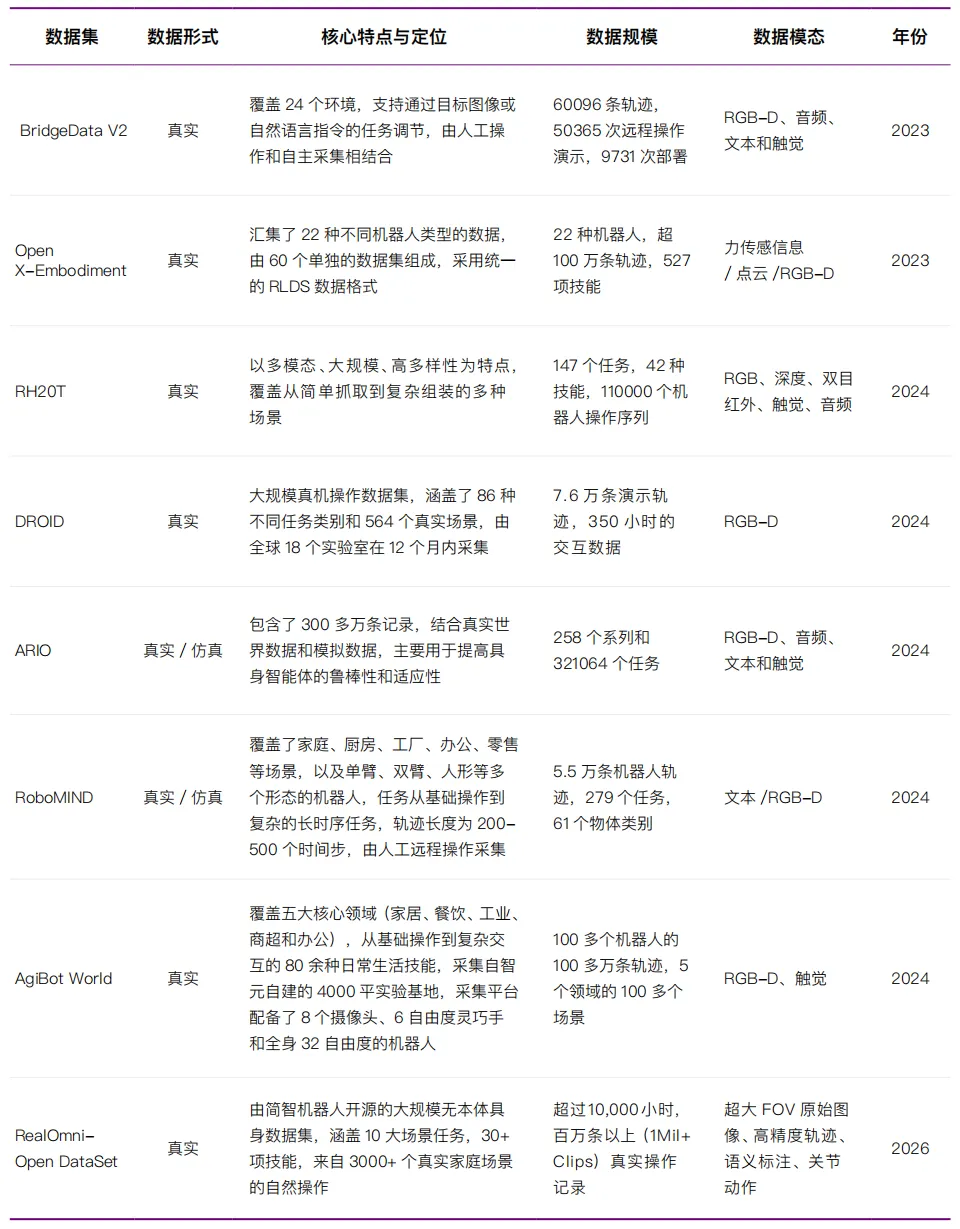
数据缺口致命:行业共识是,要让人形机器人“开窍”,至少需要百万小时的真实物理交互数据。而目前积累的,还不到5%。更要命的是,这些数据彼此不互通,采集成本还在指数级上升。
没有足够的数据,再好的算法也难落地。
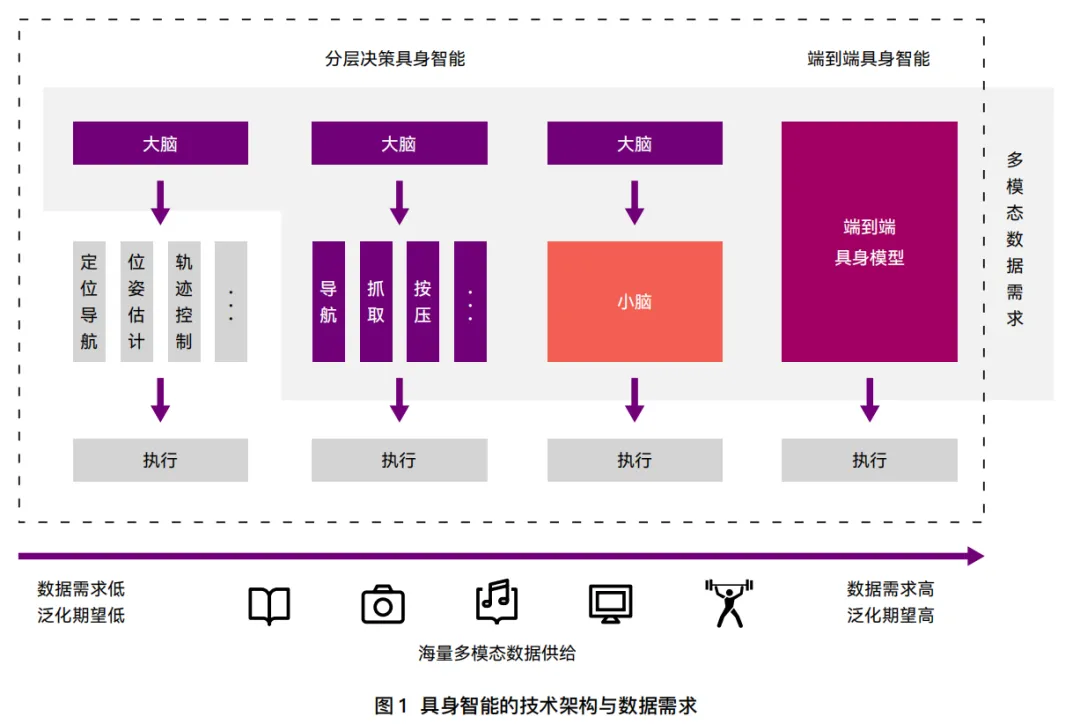
二、三大数据采集路线:构建具身智能的“数据金字塔”
白皮书将具身智能的数据采集清晰归纳为三条核心路径,它们在精度、成本和规模上各有千秋,正在加速融合。
1. 遥操作数据:当前“黄金标准”,高精度但高成本
人类远程操控机器人,同步记录下“动作意图—环境感知—物理执行”的全链条高保真数据。这是目前训练机器人基础技能最可靠的方式。
代表方案:Mobile ALOHA、UMI、智元机器人数据采集工厂。
优点:数据物理真实性拉满,堪称“黄金标准”。
痛点:成本高、效率低、难以规模化,注定无法靠它撑起通用模型。
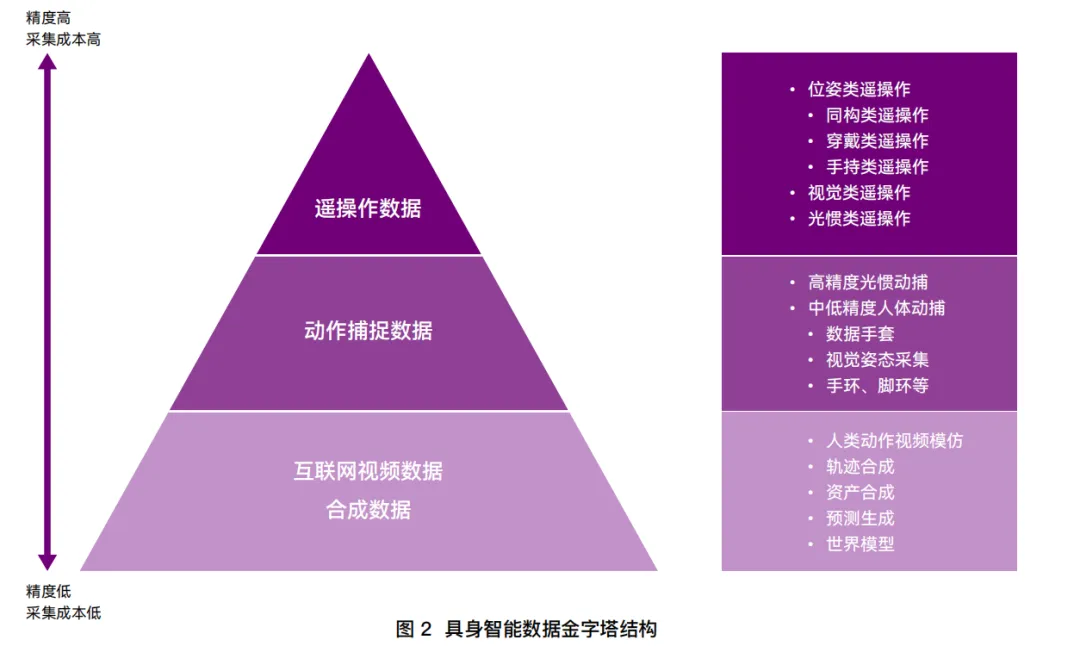
2. 动作捕捉数据:连接真实与仿真的“中间桥梁”
通过视觉、惯性传感器或外骨骼设备,捕捉人的动作,再转化为机器人可学习的数据。这种方式兼顾了真实感和成本,尤其适合全身运动控制。
代表方案:DexCap、诺亦腾动捕系统、帕西尼感知超级数据工厂。
定位:弥补遥操作短板,成为“无本体数据采集”的关键支撑。

3. 互联网视频+合成数据:未来规模化的“终极解法”
人类视频演示数据:利用海量互联网视频,低成本提取动作知识。字节的GR-2、Figure AI的“机器人行为YouTube”都在走这条路,成本较传统遥操作降低200倍。
合成数据:在仿真环境中生成轨迹、资产、决策数据,解决真实世界难以采集的稀缺场景。英伟达的MimicGen、RoboGSim是典型代表。
瓶颈:视频数据精度不够,合成数据存在“仿真到现实”(Sim2Real)的鸿沟。
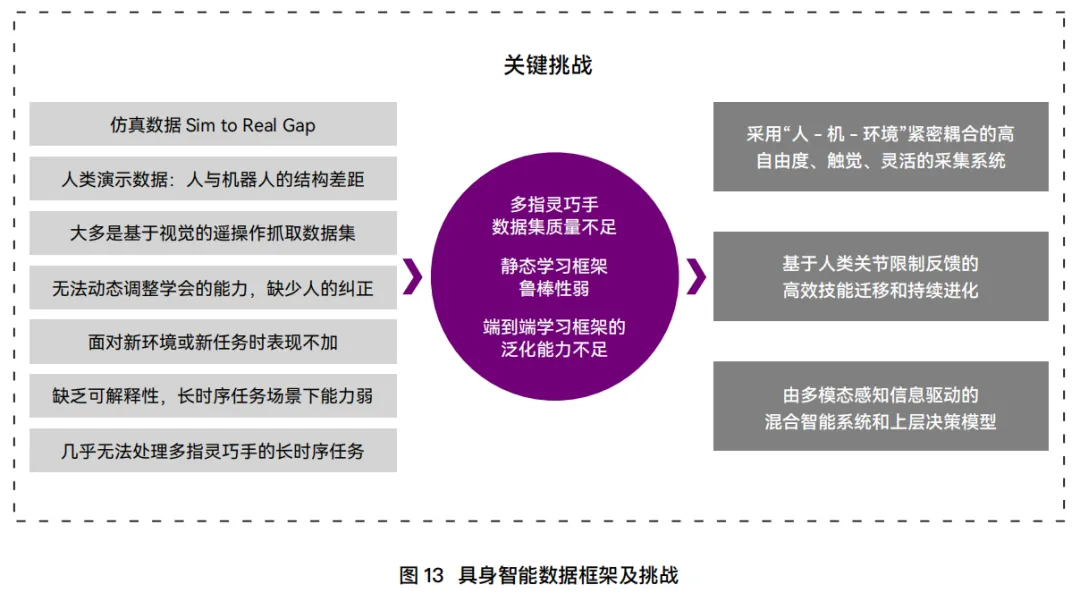
核心趋势:三条路线不是替代关系,而是逐步走向融合。尤其“无本体数据采集”正成为行业新方向,试图破解“成本—规模—多样性”的不可能三角。
三、自动驾驶的经验:给具身智能抄好“作业”
自动驾驶可以看作“轮式具身智能”。它走过的路,对今天的人形机器人有极高参考价值。
白皮书提炼了三大经验:
高精地图的教训:静态真实数据不可持续。一旦环境变了,模型就“傻眼”。必须构建动态数据闭环。
数据异构融合:多传感器时空对齐,从数据级融合走向特征级、决策级融合。
核心范式:仿真优先,真机验证。用仿真低成本覆盖海量场景,用少量真实数据校准,构建“数据驱动”的迭代飞轮。
这套范式正在成为具身智能的主流选择:大规模仿真预训练 + 少量真机数据微调。
四、数据价值再评估:没有最优路线,只有场景适配
报告对三类核心数据的价值做了冷静判断:
真机遥操作数据:是启动学习、最终校准的“黄金标准”,但无法靠它实现通用泛化。
无本体数据:规模化、低成本优势明显,有望推动模型性能突破,但数据治理、运动重定向等工程难题不小。
仿真系统:必备工具,但物理保真度不足、开发成本高,仍需长期迭代。
结论很清晰:数据采集不能“埋头干”,而要“抬头看”。定向补充模型能力瓶颈,多路径融合才是最优解。
五、渐进式商业化:数据驱动的三阶段落地路径
具身智能不会出现ChatGPT式的一夜爆火,它更像一场马拉松,靠数据规模驱动渐进演进。
阶段1:少量数据构建原型(启动期)
用几十到几百条高质量遥操作数据,打造MVP,验证结构化任务(如3C装配、简单抓取)。
核心目标:控制成本,证明1.5—2年内能回本的可行性。
阶段2:大量数据深耕垂直场景(成长期)
聚焦工业装配、仓储物流、商业清洁等垂直场景,规模化采集场景数据。
目前国内已建成20余个具身智能训练场,总面积超4万平方米,目标就是破解“数据孤岛”。
阶段3:海量数据实现高阶闭环(成熟期)
依托“云-边-端”协同,云端训练技能、边缘实时调度、终端执行。
商业模式从“卖硬件”转向“智能即服务”——用户按需订阅机器人技能,硬件标准化,生态开放化。
六、机会与风险全景:六大黄金赛道 VS 六大致命挑战
六大发展机会
感知技术创新:感算一体、触觉/力觉传感器,成为多模态数据的入口。
数据治理基建:全生命周期数据采集、清洗、标注,推动行业标准化。
垂直场景方案:聚焦封闭、高危场景,快速实现商业落地。
真机失败数据:负面样本反而能加速模型鲁棒性提升。
世界模型:补足物理直觉,通往具身GPT-3.5的潜在路径。
无本体数据:让数据与硬件解耦,突破规模化瓶颈。
六大核心风险
技术迭代风险:模块化、端到端、世界模型三条路线还在博弈,现有方案或被颠覆。
数据验证风险:数据“是否可用”的验证投入巨大,容易产生沉没成本。
安全隐私风险:数据投毒、隐私泄露、伦理监管趋严。
人机交互风险:功能安全标准缺失,物理伤害隐患突出。
标准缺失风险:硬件接口、数据格式不统一,形成数据孤岛。
商业化不及预期:场景窄、ROI低,通用智能落地或需十年以上。
结语:具身智能是马拉松,数据是最长的跑道
具身智能,是比互联网、移动互联网更深远的产业革命。它是AI从数字认知走向物理行动的终极跨越。
这场变革没有捷径。硬件突破是基础,算法创新是核心,数据供给是前提。通往通用具身智能的路,不是一次突变,而是一场以五年、十年为尺度的渐进演进。
更多报告: