威斯康星大学新研究:让CT报告里的箭头和线条“活”过来,自动生成3D病灶分割
2026-02-05 00:32
威斯康星大学新研究:让CT报告里的箭头和线条“活”过来,自动生成3D病灶分割

? 龙哥读论文知识星球来了!还在为找不到高质量的AI医疗论文发愁?星球每日精准推送医学影像、AI医疗等前沿论文速递,核心方法、实验结论、开源代码一键直达!?扫码加入「龙哥读论文」知识星球,像挖掘PACS宝藏一样,挖掘AI学术宝藏!
龙哥推荐理由:
这篇论文的切入点非常巧妙且实用!它没有去卷更复杂的模型,而是把目光投向了医院里“沉睡”的海量数据——放射科医生在日常工作中留下的那些箭头、线条标注。通过一个精心设计的模型,将这些“废料”变废为宝,自动生成高质量的3D分割,这简直是构建大规模医学影像数据集的“捷径”。不仅技术上有创新(MCM机制),更在解决实际数据瓶颈问题上提供了极具价值的思路,强烈推荐给AI医疗和计算机视觉领域的研究者。
原论文信息如下:
论文标题:
Opportunistic Promptable Segmentation: Leveraging Routine Radiological Annotations to Guide 3D CT Lesion Segmentation
发表日期:
2026年02月
发表单位:
University of Wisconsin–Madison (威斯康星大学麦迪逊分校)
原文链接:
https://arxiv.org/pdf/2602.00309v1.pdf
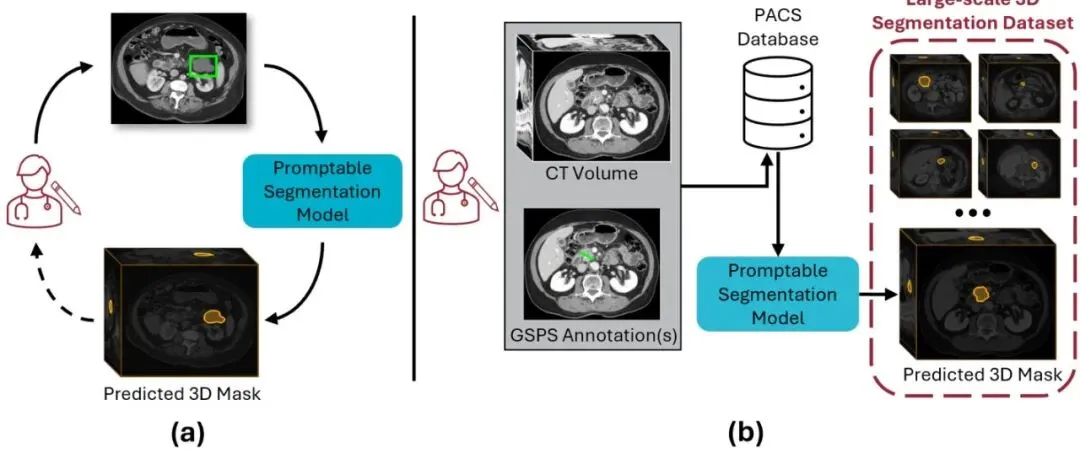
大家好,我是龙哥。今天我们来聊一篇特别“接地气”的论文。咱们都知道,训练一个牛X的医学影像AI模型,最缺的是什么?是数据!尤其是那种带精确3D轮廓标注的数据,让放射科医生一笔一笔画出来,费时费力还费钱。但是,医院里其实躺着海量的“半成品”数据,每天都在产生,却没人用。你想啊,医生看CT片子的时候,是不是经常用箭头标一下病灶,或者拉条线量一下大小?这些随手画的标记,就静静地躺在医院的PACS(影像归档和通信系统)里吃灰。威斯康星大学麦迪逊分校的团队就盯上了这块“宝藏”。他们想:能不能让AI看懂医生这些简单的箭头和线条,然后自动把整个病灶的3D形状给“脑补”出来? 这样一来,海量的历史标注不就能一键转化成高质量的3D分割数据集了吗?这个点子,他们称之为“机会性可提示分割”,并打造了一个专门的模型叫SAM2CT。咱们今天就来看看,他们是怎么把这盘“冷饭”炒香的。图1: (a) 传统的交互式分割流程,需要放射科医生提供提示。(b) 本文提出的机会性可提示分割流程,直接利用PACS中现存的GSPS标注作为提示,自动生成3D分割,可用于大规模构建数据集。从“废料”到“宝藏”:挖掘PACS中的隐藏标注金矿
首先,咱们得明白医生们在PACS里留下的“废料”到底是什么。它有个专业名字,叫GSPS(Grayscale Softcopy Presentation State,灰度软拷贝表示状态)。简单说,这就是一个DICOM格式的文件,里面记录了医生在查看图像时做的各种标记,比如箭头、测量线、文字注释等等。医生画箭头是为了突出显示病灶,拉线是为了测量其大小(遵循RECIST等标准)。这些操作对医生来说是举手之劳,是日常工作的一部分。但对于AI来说,这些稀疏的标注就像是寻宝地图上的“X”标记,指明了宝藏(病灶)的大致位置,但没告诉你宝藏具体有多大、是什么形状。现在的可提示分割模型(比如大名鼎鼎的SAM),你给它一个点或者一个框,它能给你抠出那个物体。但问题是,现有的模型不认识医生的箭头和线啊!这就形成了一个尴尬的局面:一边是海量现成的“箭头/线”提示库,另一边是嗷嗷待哺但“挑食”的AI模型。这篇论文的核心价值就在于此:它架起了一座桥。它让AI模型学会了理解医生的“语言”(箭头和线),从而能自动化地将历史积存的GSPS标注,批量转化成真正的3D分割掩码。这相当于不花医生一分钱额外时间,就获得了海量标注数据,思路实在是巧妙!SAM2CT:让箭头和线条“开口说话”
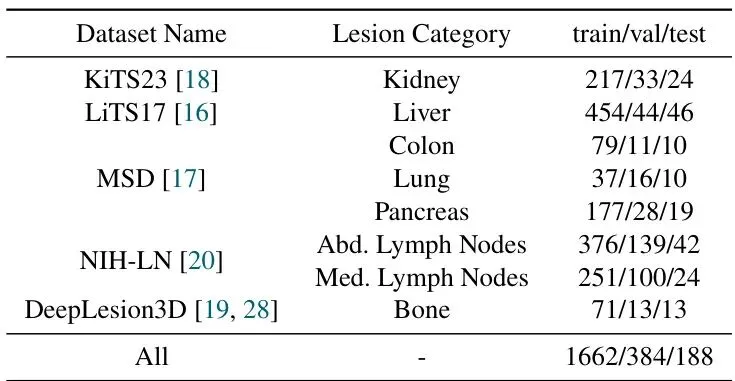
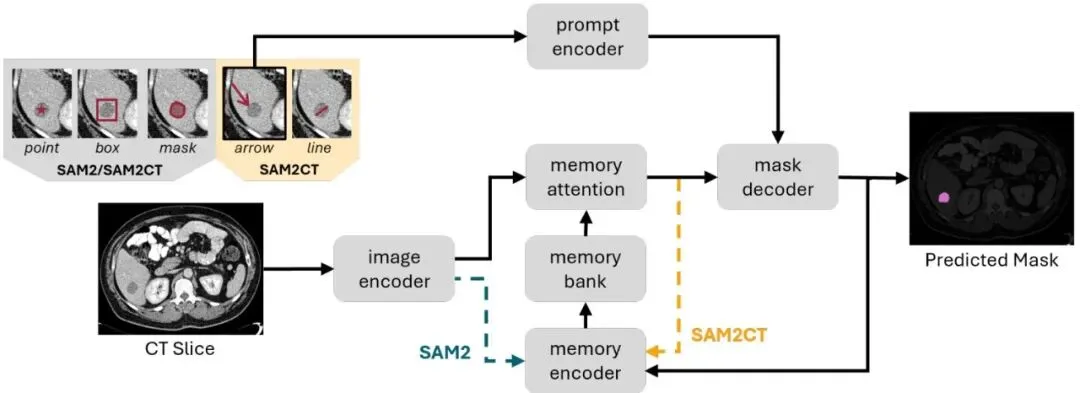
既然现有的模型不懂箭头和线,那就教它懂。团队选择了SAM2作为基础模型。为什么是SAM2?因为SAM2本身是为了分割视频设计的,它有一个记忆机制,可以跨帧传递信息。把CT的连续切片看成视频的连续帧,这个设定非常自然,SAM2几乎可以拿来直接处理3D体积数据。但原版SAM2只懂点、框和掩码提示。所以,SAM2CT做的第一个关键改动,就是升级了它的“提示编码器”。他们在提示编码器里增加了三个可学习的参数,分别对应“线的端点”、“箭头的起点”和“箭头的终点”。当你输入一条线时,模型就把这条线的两个端点坐标,分别加上“线的端点”这个参数所代表的学习到的特征。箭头也是类似的处理。这样,模型就能理解这两种新形式的提示了。为了训练这个新能力,他们从5个公开的CT病灶分割数据集中收集了数据,涵盖了肾、肝、肺、胰腺、结肠肿瘤以及淋巴结等多种类型。但公开数据集没有现成的箭头/线标注啊,怎么办?自己合成! 论文设计了一套算法,可以根据真实的病灶掩码(ground truth mask),自动生成看起来像医生手画的箭头和测量线。先找到病灶的中心和边界上的一个随机点,箭头头部落在这个两点连线的某个随机位置上(甚至可能超出边界一点,模仿医生点击时的小误差),箭头尾部则朝向中心点。枚举病灶边界上所有可能的点对连接线,训练时随机选一条较长的(模拟大致测量),评估时则选长度在前90%的线(模拟医生更可能测量最长径)。就这样,SAM2CT学会了“听说读写”医生的箭头和线条语言。但这还不够,为了让它在3D分割上做得更好,团队还给它动了个“脑部手术”,升级了它的记忆系统。记忆条件记忆(MCM):让模型记住病灶的“样子”
这是本文在技术上的一个核心创新点,名字听起来有点绕:Memory-Conditioned Memories, 记忆条件记忆,简称MCM。咱们来拆解一下。SAM2处理3D CT时,是逐层(切片)处理的。假设我们在第k层给了一个提示(比如箭头),SAM2会先在这一层生成一个分割结果。然后,它要把这个信息“记住”,并传递给下一层(k+1)使用,以此类推,直到处理完整个病灶。图2:SAM2CT架构概述。蓝色箭头表示标准SAM2架构,图像特征直接从图像编码器送入记忆编码器。黄色箭头表示SAM2CT的记忆条件记忆(MCM),记忆编码器接收的是经过记忆注意力处理后的图像特征。那么“记忆”到底是怎么形成的呢?在原版SAM2中:1. 图像编码器提取当前切片的特征,得到无条件图像嵌入(E_unc)。
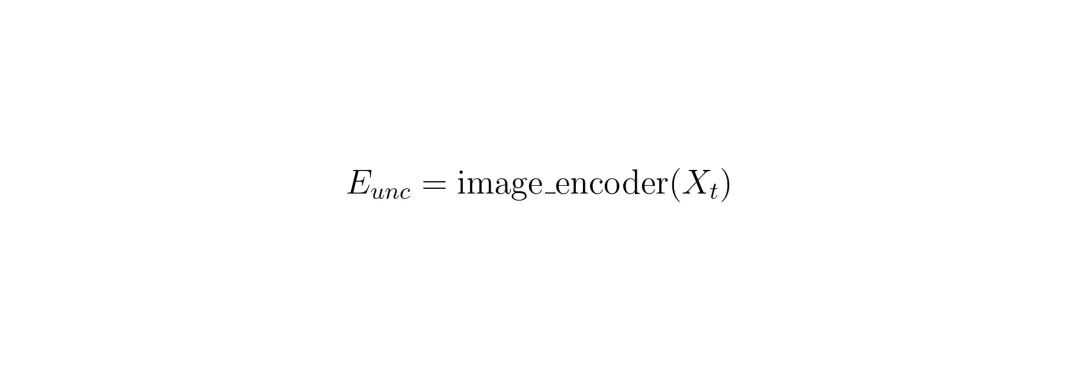 2. 这个E_unc会与之前层的记忆(mem)进行记忆注意力操作,得到一个条件图像嵌入(E_cond),它包含了关于目标病灶的信息。
2. 这个E_unc会与之前层的记忆(mem)进行记忆注意力操作,得到一个条件图像嵌入(E_cond),它包含了关于目标病灶的信息。
 3. 掩码解码器根据E_cond和提示,生成当前层的分割掩码(M_t)。
3. 掩码解码器根据E_cond和提示,生成当前层的分割掩码(M_t)。
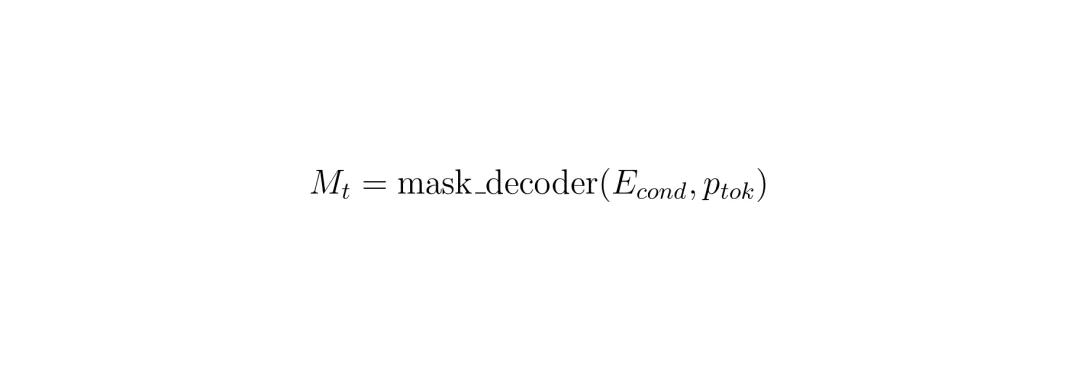 4. 为了记住当前层的信息给下一层用,记忆编码器会把当前层的分割掩码(M_t)和无条件图像嵌入(E_unc)融合,形成新的记忆(mem_t)存起来。
4. 为了记住当前层的信息给下一层用,记忆编码器会把当前层的分割掩码(M_t)和无条件图像嵌入(E_unc)融合,形成新的记忆(mem_t)存起来。
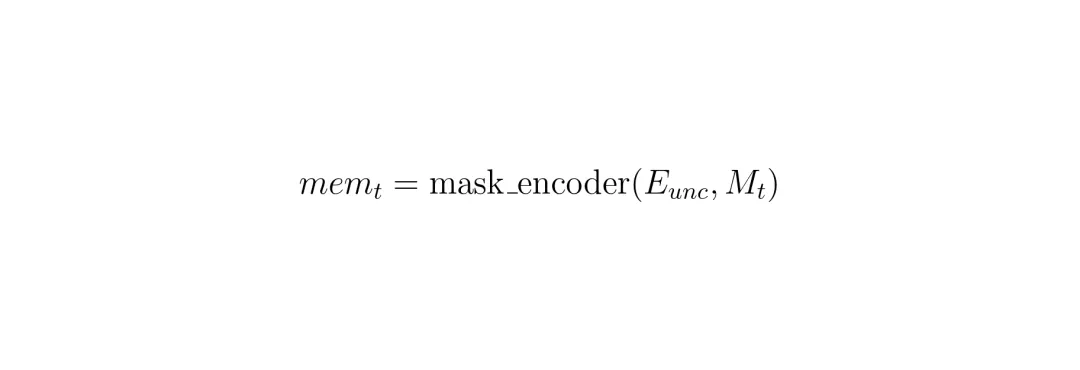 发现问题了吗?第4步,记忆是用“无条件”特征(E_unc)造的! E_unc只包含整张切片的全局信息,并没有特别强调病灶区域。这在视频分割里可能有用(需要关注整个场景变化),但在3D病灶分割里,我们只关心那个特定的病灶啊!于是,SAM2CT的MCM机制做了一个关键改动:不用E_unc,而用E_cond来构造记忆!
发现问题了吗?第4步,记忆是用“无条件”特征(E_unc)造的! E_unc只包含整张切片的全局信息,并没有特别强调病灶区域。这在视频分割里可能有用(需要关注整个场景变化),但在3D病灶分割里,我们只关心那个特定的病灶啊!于是,SAM2CT的MCM机制做了一个关键改动:不用E_unc,而用E_cond来构造记忆!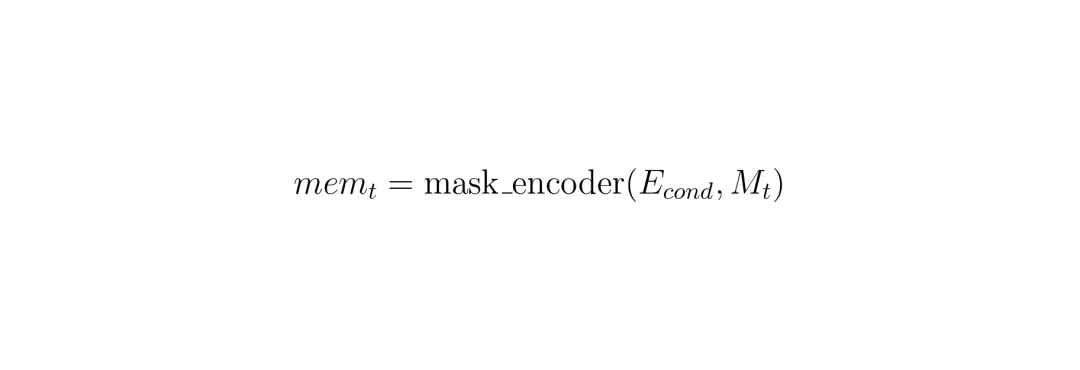 E_cond是已经和之前病灶记忆做过注意力的特征,它聚焦于病灶。用它来生成新的记忆,就等于告诉模型:“喂,重点记住病灶长什么样,别的杂七杂八的背景信息可以忽略一点。” 这样形成的记忆更具针对性,传递给后续切片时,自然能做出更准确的分割。
E_cond是已经和之前病灶记忆做过注意力的特征,它聚焦于病灶。用它来生成新的记忆,就等于告诉模型:“喂,重点记住病灶长什么样,别的杂七杂八的背景信息可以忽略一点。” 这样形成的记忆更具针对性,传递给后续切片时,自然能做出更准确的分割。实验结果:在标准测试和真实临床中均表现优异
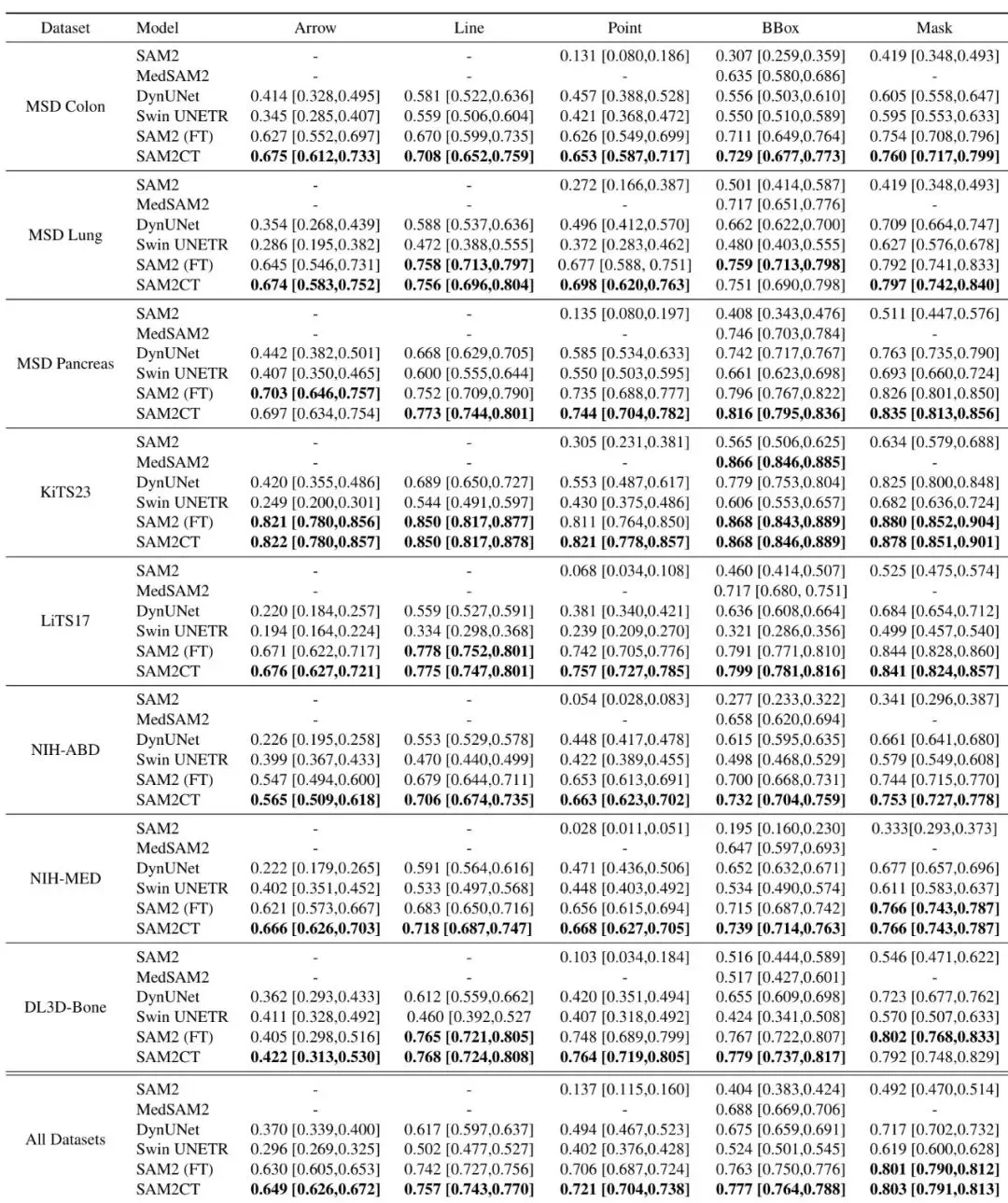
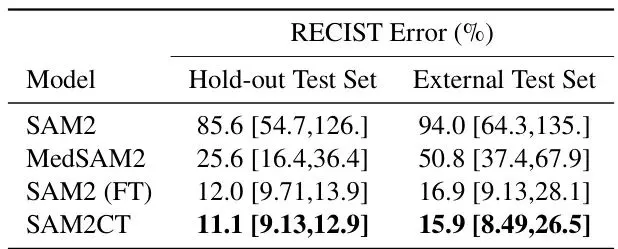
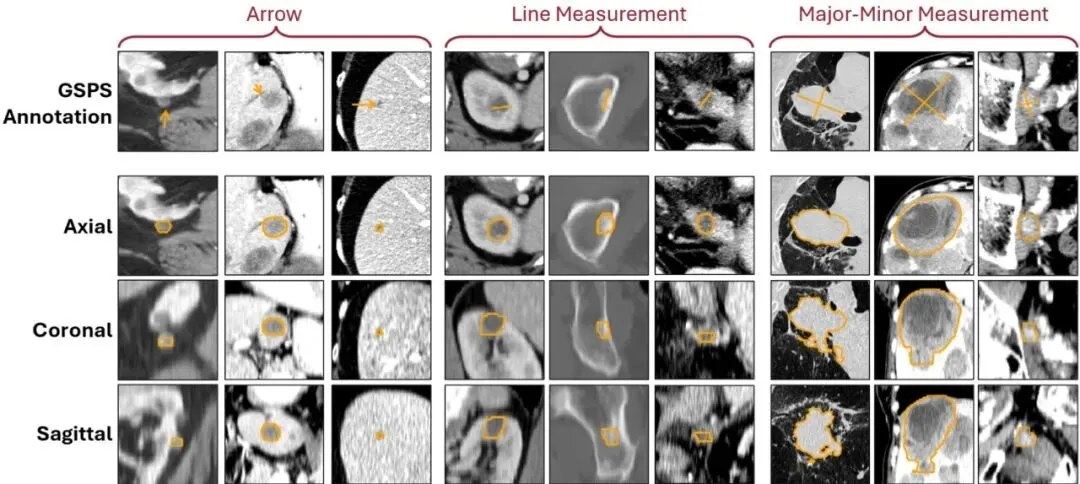
理论说得再好,也得看疗效。团队设计了全面的实验来验证SAM2CT。首先是在保留测试集(从训练数据集中划分)上的表现。他们对比了多个模型:原版SAM2、医学版SAM2(MedSAM2)、两个强大的医学分割基线模型(DynUNet和Swin UNETR)、以及一个仅做微调但不带MCM的SAM2版本(SAM2 (FT))。表2:所有模型的Dice分数(带95%置信区间)。结果按数据集和提示类型分层。结果非常清晰:SAM2CT在所有五种提示类型(箭头、线、点、框、掩码)上均取得了最高的Dice分数。对于本论文主打的箭头和线提示,Dice分别达到0.649和0.757。更重要的是,SAM2CT显著优于仅微调的SAM2 (FT),这证明了MCM机制的有效性。原版SAM2和医学基线模型的表现则差得多。另一个临床常用指标是RECIST测量误差(肿瘤最长径的测量准确性)。SAM2CT将平均误差控制在了11.1%,是所有模型里最低的,这对于临床评估来说意义重大。表4:在保留测试集和外部测试集(DeepLesion3D)上的RECIST测量误差百分比。这才是真正的“大考”!团队从医院PACS里随机抽取了60个带有真实GSPS标注的肿瘤病例(箭头、单线、长短轴测量各20个),让SAM2CT去分割,然后请两位资深放射科医生对结果进行盲审打分。评分标准很严格:3分=可直接用于临床测量;2分=仅需微调;1分=需要大改。结果令人振奋:高达87%的病例(62%+25%)被评为可直接使用或仅需微调! 这意味着,用这个模型批量处理历史数据,产出的大部分分割结果都是可用或接近可用的,能极大节省人工复核和修正的时间。图3:SAM2CT为肿瘤病例生成的分割轮廓可视化。原始的GSPS提示(箭头、线测量、长短轴测量)与SAM2CT在横断面、冠状面和矢状面上的分割结果并列显示。不止于肿瘤:在急诊科展现零样本泛化能力
SAM2CT是在肿瘤数据上训练的,那它能处理其他类型的病灶吗?为了验证其泛化能力,团队构建了一个“零样本”测试集——来自急诊科的常见阳性发现,如脓肿、胆结石、囊肿、肾结石、疝气等。这些病灶的形态、位置和外观与训练集中的肿瘤差异很大。结果如何?SAM2CT展现出了令人惊喜的泛化性能。使用原始的临床GSPS提示(箭头/线),它在脓肿、囊肿和胆结石上取得了不错的Dice分数(0.610-0.727)。当然,对于一些形态特别不规则或与训练数据差异极大的病灶(如憩室炎),性能有所下降。但整体来看,一个只在肿瘤数据上训练的模型,能一定程度上理解并分割其他类型的急诊病灶,这已经非常难能可贵了。未来展望:构建大规模多模态数据集的新途径
这篇论文的价值远不止于提出了一个更好的分割模型。它最重要的贡献是开辟了一条全新的、可扩展的医学影像数据集构建路径。全球医院的PACS中,存储着数以亿计带有GSPS标注的影像研究。通过SAM2CT这样的模型进行自动化处理,可以近乎零成本地将这些“沉睡的标注”激活,转化为可用于训练下一代AI的3D分割数据。这不仅可以用于CT,未来也很容易扩展到MRI、X光等其他模态。当然,这条路也面临挑战,比如不同医院、不同PACS系统的标注格式差异,生成结果的质量控制和标准化等。但无论如何,这篇论文为我们指出了一个充满希望的方向:利用临床工作中自然产生的、低成本的“弱监督”信号,来破解AI医疗的数据荒难题。龙迷三问
这篇论文解决的核心问题是什么? 它解决了构建大规模3D医学影像分割数据集成本高昂、依赖医生手动标注的瓶颈问题。通过利用医生在日常工作中已产生的、存储在PACS系统中的箭头和线条标注(GSPS)作为“弱提示”,训练一个专门的AI模型(SAM2CT)来自动生成高质量的全病灶3D分割,从而实现历史标注数据的“废料利用”和自动化标注。
文中的PACS和GSPS具体指什么? PACS是Picture Archiving and Communication System的缩写,即影像归档和通信系统,是医院里用于存储、管理、传输医学影像(如CT、MRI)的核心信息系统。GSPS是Grayscale Softcopy Presentation State的缩写,即灰度软拷贝表示状态,是一种DICOM标准格式,专门用于存储医生在审阅图像时添加的标注信息,如箭头、测量线、文本、窗宽窗位设置等。
MCM机制为什么有效? MCM(Memory-Conditioned Memories,记忆条件记忆)有效是因为它优化了模型在3D分割中“记忆”病灶信息的方式。原版SAM2使用全局的、无条件的图像特征来生成记忆,这些记忆包含了太多无关的背景信息。MCM改为使用经过“记忆注意力”聚焦后的、富含病灶信息的条件特征来生成记忆。这使得保存和传递到后续切片的记忆更加“纯粹”和“专注”于目标病灶本身,从而提升了跨切片分割的一致性和准确性。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
将“机会性”利用现有临床标注的思路与可提示分割模型结合,切入点新颖且极具实用价值。MCM机制是针对3D医学图像特性的一个巧妙改进。实验合理度:★★★★☆
实验设计全面,涵盖了标准数据集测试、真实临床标注的医师盲审、外部数据集泛化性测试以及零样本能力验证。对比基线模型选择合理。美中不足是真实临床评估的样本量(N=60)可以更大。学术研究价值:★★★★★
价值非常高。不仅提出了一个新模型,更重要的是开创了一种新的、可扩展的医学影像数据构建范式,对整个AI医疗社区解决数据瓶颈问题有重大启发意义。稳定性:★★★☆☆
在训练数据覆盖的肿瘤类型上表现稳定,但在形态差异大的急诊病灶上性能波动较大。生成的87%可用结果仍需部分人工复核,无法达到完全自动化生产临床级数据的稳定程度。适应性以及泛化能力:★★★☆☆
在同类CT病灶(不同器官肿瘤)上泛化性好,跨模态(如MRI)尚未验证。对训练分布外的急诊病灶展现出了一定的零样本能力,但性能有待提升,适应性受限于训练数据的多样性。硬件需求及成本:★★☆☆☆
基于SAM2架构,参数量相对不大(约3800万),但推理时需要逐切片处理整个3D体积,并涉及记忆注意力等操作,计算开销比常规单次前向传播的UNet类模型要高,实时性一般。复现难度:★★★☆☆
论文方法描述清晰,但依赖SAM2作为基础模型,其官方代码和权重已开源。合成GSPS提示的算法细节已给出。主要难度在于收集和预处理多中心的医学数据集及对应的GSPS标注。产品化成熟度:★★☆☆☆
目前更适合作为医院或科研机构内部的数据集构建工具,用于生成“预标注”以加速人工标注流程。直接作为临床诊断工具尚不成熟,需要严格的质量控制、监管审批和与医院PACS系统的深度集成。可能的问题:论文在概念验证上非常成功,但要将此范式推广到全院乃至多中心,面临GSPS标注格式标准化、不同病灶类型表现不均、生成数据的质量控制与标准化等实际工程挑战。这些是未来研究需要重点攻关的方向。
[1] Church, S., Warner, J. D., Maqbool, D., Tie, X., Hu, J., Lubner, M. G., & Bradshaw, T. J. (2026). Opportunistic Promptable Segmentation: Leveraging Routine Radiological Annotations to Guide 3D CT Lesion Segmentation. arXiv preprint arXiv:2602.00309v1.*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

想和更多AI医疗、图像处理领域的小伙伴交流SAM2CT这样的宝藏模型吗?欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 AI医疗+北京+协和+小医),根据格式备注,可更快被通过且邀请进群哦!