RoboChallenge 是原力灵机Dexmal与Hugging Face联合推出的全球首个具身智能大规模真机评测平台,2025Q4-2026Q1发布了首份年度报告。期间已部署20台主流真机、开源Table30数据集(30个标准化任务),累计完成41964次真机测试,吸引中、美等多国开发者参与(中国开发者占比58.3%);榜单显示Top模型最高成功率仅51%,叠碗、移物入盒等基础任务已趋成熟,但整理纸杯、做三明治等复杂/柔性任务成功率极低,平台通过开源数据、标准化流程保障评测公平,未来将拓展机型、场景与多任务评测体系,推动具身智能技术落地。
下载链接:
https://robochallenge.ai/2025%20RoboChallenge%20%E5%B9%B4%E5%BA%A6%E6%8A%A5%E5%91%8A.pdf

RoboChallenge:全球首个规模化真机评测生态落地
RoboChallenge的诞生,填补了具身智能标准化真机评测的行业空白。其平台架构与数据表现,印证了具身智能行业对真实考场的迫切需求。
平台核心配置
硬件基础:部署UR5、Franka、ARX5、ALOHA 4种主流机型,共20台真机测试集群,覆盖单臂/双臂两种构型; 数据支撑:开源Table30数据集,包含9大类、30个标准化桌面任务,单个任务提供1000条完整真机轨迹,累计下载量达17K次; 生态协同:联合智源研究院、清华大学等20+产学研单位成立组委会,形成“指导委员会+4大工作组”的治理架构。
关键数据
高参与度:累计核发提测资格209个,提测转化率39.2%,单日真机测试峰值达834次,验证了平台高并发吞吐能力; 国际化布局:中国开发者占比58.3%(核心力量),美国(22.0%)、新加坡(10.1%)、日本(7.6%)等多国开发者参与,形成全球化竞技格局; 开源协作:GitHub与Hugging Face双平台同步开放代码、数据集与任务配置,社区持续贡献改进建议,构建“真实评测+开源协作”的生态闭环。
榜单揭秘:模型表现两极分化,最高51%成功率
报告通过“成功率+过程分”的双重评价体系(每任务执行10次,取平均值),呈现了当前具身智能模型的真实战力。榜单结果既暴露了行业短板,也揭示了技术突破点。
总榜TOP8
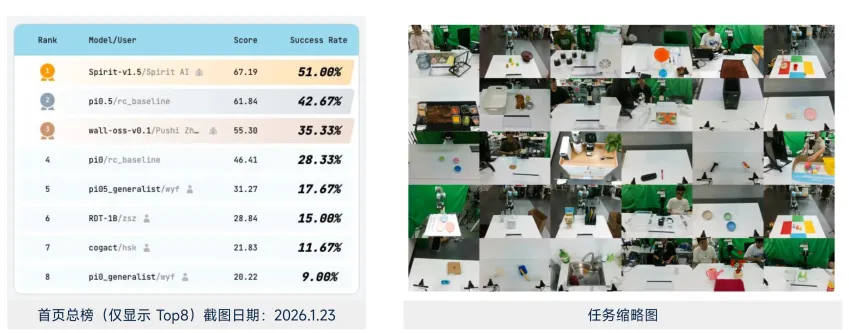
核心发现:榜首模型的平均成功率仅51%,意味着即便是当前最优模型,在面对30个标准化任务时,也有近一半的概率失败。过程分普遍高于成功率(如Rank2模型Score 61.84>SR 42.67%),说明模型在失败任务中仍能完成部分关键步骤,具备优化潜力。
任务梯队
报告将30个任务划分为三大梯队,清晰呈现模型能力边界:
第一梯队(Hello World级):堆碗(stack_bowls)、堆色块(stack_color_blocks),Top3模型成功率均达100%,成为模型评测的“入门必测”任务; 第二梯队(简单任务):放鞋上架(place_shoes_on_rack)、寻找绿盒子(search_green_boxes),Top1成功率90%+,Top3成功率≥70%,门槛较低; 第三梯队(叹息之墙):做素三明治(make_vegetarian_sandwich)、给盆栽浇水(water_potted_plant)等,所有参测模型成功率为0%,成为行业共同难题。
失败案例复盘
报告中5个典型失败任务,揭示了具身智能的核心痛点:
做素三明治:时序依赖强,“一步错全流程错”,初始步骤夹取失败直接导致任务终止; 给盆栽浇水:长程记忆缺失,机械臂在浇水后出现“幻觉”,无法执行放回水壶的动作; 叠抹布:柔性物体操作难,布料形变不可预测,机械臂常“拖着抹布走”; 排列纸杯:全流程控制要求高,最后一步夹爪微小抖动推倒杯塔,前80%努力白费。
评测体系
为解决真机评测的“人为偏差”“标准缺失”等问题,RoboChallenge设计了一套科学严谨的评测体系,成为行业标准化的核心参考。
架构创新:用户端推理+API交互
平台采用“用户端推理”模式,模型运行在参测方本地,通过标准化API接收RGB图像、深度图等观测数据,无需迁移复杂环境,既保障模型资产安全,又降低参与门槛。
去偏差机制:视觉输入匹配法
为消除操作员摆放物体的主观偏差,平台在测试前叠加“半透明参考图像”,要求操作员调整物体位置至与训练数据高度重合,确保所有模型在一致初始条件下公平竞技。
双重评分标准:结果与过程并重
成功率(Success Rate):衡量任务是否完成,取10次执行的平均成功率; 过程分(Progress Score):拆解任务阶段,完成即得分,重试每次扣0.5分,即便任务失败也能量化中间进展; 透明化机制:公开所有评测录像、机器日志,支持社区复盘失败案例。
产学研生态共建
RoboChallenge的核心价值,不仅在于提供评测平台,更在于凝聚行业共识,推动具身智能评测的标准化与规模化。
组委会架构
指导委员会:统筹全局,遵循“开放、协作、共识”原则; 四大工作组:基准与任务设计(核心大脑)、实验室维护(硬件管家)、平台开发(数字底座)、社区共建(放大器),形成“决策-执行”闭环。
社区核心建议
报告汇总了全球开发者与机构的反馈,明确了未来重点演进方向:
完善Zero-Shot能力评估,开发专门的基准测试集; 构建通用多任务评测体系,推出“跨任务组合任务”; 可视化仿真与真机评测差异,提供对比曲线模板; 扩展Benchmark规模,打造“Bench30+/Bench100”系列; 增加更多工业主流机型与适配接口,简化硬件接入; 拓展厨房、仓储等真实场景,引入动态障碍等复杂元素。
顶尖团队的调优经验分享
报告收录了千寻智能、自变量、极佳视界等顶尖团队的实战经验,为开发者提供了可直接复用的调优思路:
数据工程
对夹爪传感器的连续波形信号进行离散化处理,转化为“开/合”方波,增强模型对末端执行器的状态判断; 可视化分析原始数据,精准识别异常值边界,为训练提供高质量数据基础。
模型优化
Mask Z策略:屏蔽Z轴高度信息,强制模型依赖视觉引导,降低定位误差; 动作平滑机制:针对机械臂极限位置抖动问题,对输出动作进行时序平滑处理; 强时序状态转换模块:解决多步骤任务中的“状态混淆”,提升执行连贯性。
评测策略
关键路径法:优先突破高分值任务,建立基线后再拓展全任务; 开环-闭环映射:通过Loss曲线、动作轨迹预判真机成功率,减少无效提交。
结语:具身智能的“GPT-3时刻”,仍需跨越三重门槛
RoboChallenge的首份年度报告,既展现了具身智能的快速发展——指数级增长的评测需求、基础任务的成熟落地,也揭示了行业面临的核心挑战:精细操作成功率不足15%、多任务能力薄弱、柔性物体与长程任务难以突破。
这份报告的价值,不仅在于提供了一份“模型成绩单”,更在于构建了行业首个“公开错题集”与标准化基准。未来,随着场景拓展、机型丰富、评测体系完善,RoboChallenge有望成为具身智能领域的“ImageNet”,推动技术从“单点突破”走向“通用智能”。
具身智能的“GPT-3时刻”尚未到来,但标准化的真机评测,已为这一时刻的到来铺就了关键一步。对于开发者而言,读懂这份报告,既是把握技术趋势的窗口,更是找到优化方向的钥匙。
私信可获取报告原文~
感谢您的阅读,若有不实之处,可以关注微信公众号 “鼓捣 AI” 留言反馈,欢迎大家批评指正。
往期精选推荐
机器人技术入门圣经:详细拆解机器人定义、历史起源、核心组件、控制架构与应用场景
RAL最新 | 突破无人机户外视觉导航的零样本迁移与Sim2Real瓶颈!
赶快收藏!2026 年机器人国际热点活动会议时间表及议程看点
1米高「友好型机器人」火了!Fauna Sprout打破壁垒,让人形机器人走进日常!
清华&小米把导航世界模型跑到实时了:最新开源工作将一步生成+多模态目标全搞定