
【导语】 2025年,全球人工智能迎来系统性进化的关键拐点。技术突破、应用深化与生态重构的三重共振,推动AI从"有能力"的展示阶段迈向"有用处"的价值创造阶段。中国信息通信研究院最新发布的《人工智能产业发展研究报告(2025年)》,以量化评测与深度调研为基础,为我们勾勒出一幅清晰的产业图景:万亿级市场规模、6000家企业主体、从"能思考"到"能实干"的能力跃迁,标志着中国人工智能产业正步入高质量发展的新阶段。
一、产业根基:万亿规模与完整生态的"双轮驱动"
中国人工智能产业正站在规模扩张与生态成熟的历史交汇点。
规模跃升,增速领跑。 据中国信通院测算,2024年我国人工智能核心产业规模突破9000亿元,同比增长24%,2025年有望达到1.2万亿元。这一增速不仅远超传统信息产业,更标志着AI从"技术投入期"进入"价值回报期"。截至2025年底,我国人工智能企业数量超过6000家,全球占比达16%,形成覆盖基础底座、模型框架到行业应用的完整产业体系。
需求爆发,动能强劲。 一个更具指标意义的数据是:2025年我国公有云大模型(对客侧)Token调用量约2000万亿,相较于2024年的114万亿,增长超过16倍。以火山引擎为例,2025年10月日均调用量已达30万亿,与谷歌同期水平(42万亿)同处全球第一梯队。这种爆发式增长表明,大模型正从"技术尝鲜"转变为"生产刚需",人工智能加速从"能思考"向"能实干"转变,为千行百业开拓赋能新空间。
生态分层,梯度成熟。 产业内部呈现明显的结构分化:基础层以算力、数据、算法为核心,2025年上半年投融资占比达35%(算力19%、模型16%);技术层MaaS平台超100个,推动模型工程化落地;应用层则在工业、医疗、科研等垂直领域形成规模化渗透。这种分层递进的生态结构,为产业持续演进提供了稳固支撑。
二、模型进化:从"复刻已知"到"探索未知"的范式革命
基础模型正处于技术跃迁的关键节点,一场关于"如何学习"的范式革命正在发生。
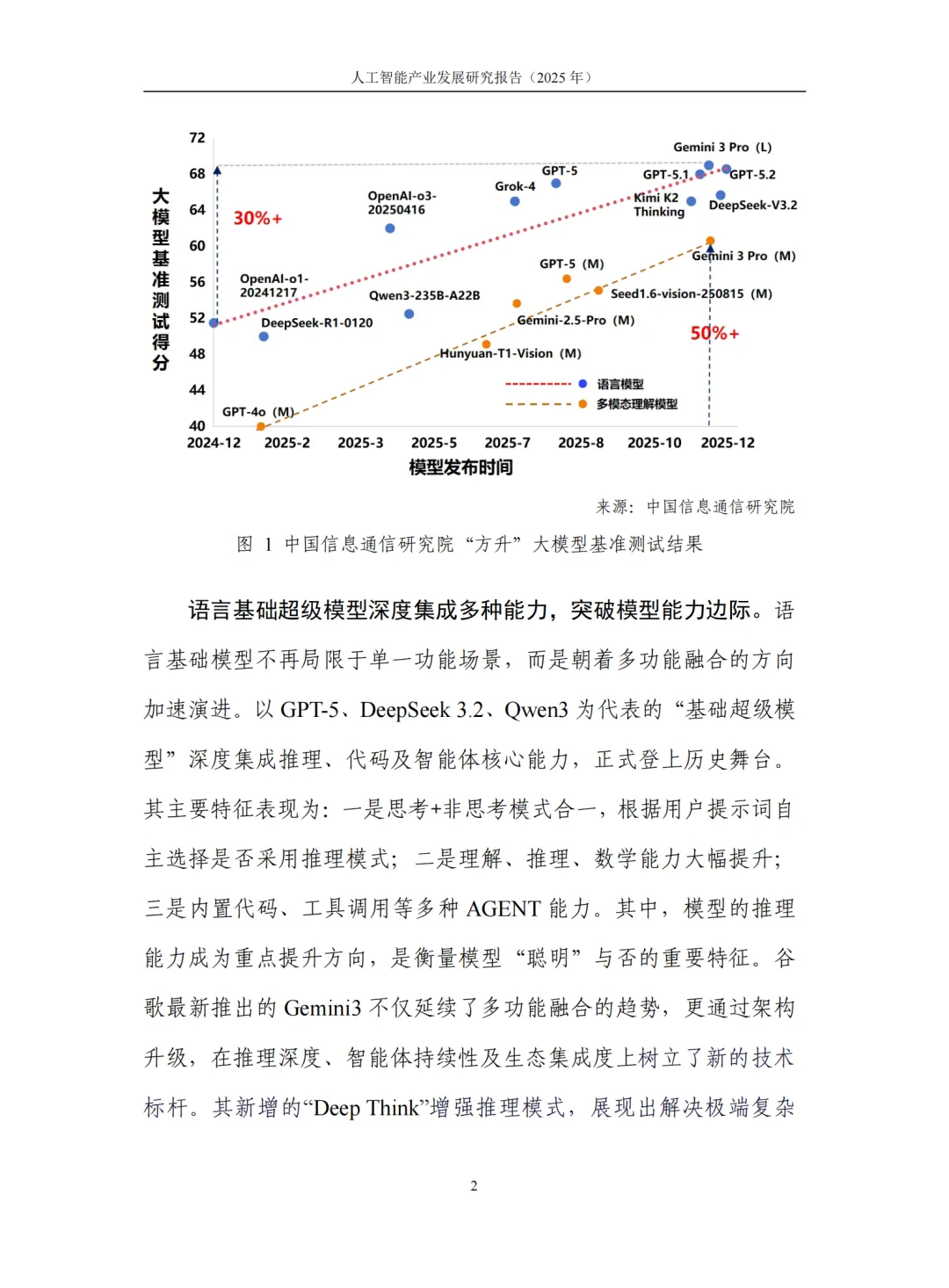
2.1 能力跃升:30%综合提升背后的技术突破
中国信通院"方升"大模型基准测试数据显示,截至2025年12月,以GPT-5.2、Gemini 3 Pro、DeepSeek V3.2、Claude 4.5、Qwen3等为代表的头部语言大模型,综合能力较2024年底提升约30%,多模态理解能力增长超过50%。更关键的是,这种提升并非简单的规模堆砌,而是源于训练范式的根本性转变。
新一代"基础超级模型"呈现三大特征:思考与非思考模式动态合一,可根据任务复杂度自主切换推理深度;理解、推理、数学、编程能力深度集成,不再依赖外部插件;代码与工具调用能力原生内置,实现从"语言生成"到"任务执行"的跨越。谷歌Gemini 3新增的"Deep Think"增强推理模式,更展现出解决极端复杂问题的潜力。
2.2 学习范式:迈入"经验时代"
报告提出一个深刻判断:大模型正从"人类数据时代"向"经验时代"演进。传统模型依赖人工标注的静态数据输入,而新一代模型通过与环境交互、任务试错和自我迭代积累动态经验,能够自主提炼跨场景规律、修正认知偏差,甚至生成超出原始训练数据范畴的创新解决方案。
这一转变的技术支撑包括:
GRPO算法体系:DeepSeek提出的GRPO已成为大模型强化学习的主流方法,其变体DAPO、VAPO、SRPO等通过多阶段策略更新与混合奖励机制,显著提升复杂任务中的泛化能力;
Agentic RL技术:ToolRL、Agent Lightning等通过真实动态环境下的多轮交互式训练,赋予模型自主规划、调用工具、因果推断能力;
自主进化框架:AlphaEvolve、OpenEvolve等实现智能体与真实环境的实时交互,配合MemGen、ReasoningBank等记忆框架,为持续进化提供信息基础。
这种"经验学习"机制,使模型能力从"复刻已知"走向"探索未知",不仅是技术路径的变更,更是AI认知能力的质变。
2.3 智能体崛起:"数字员工"雏形初现
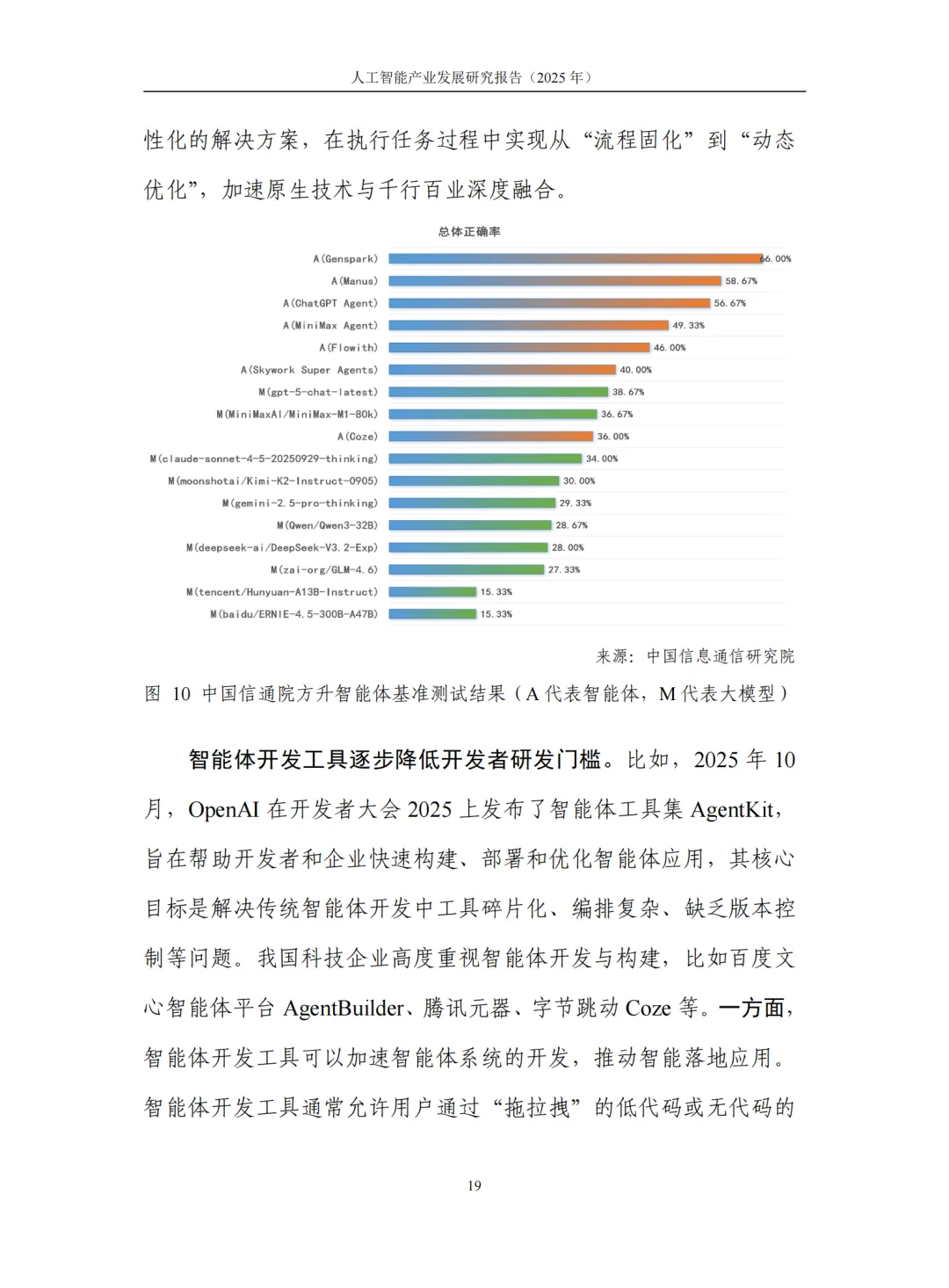
智能体(AI Agent)成为大模型价值释放的主要形态。中国信通院"方升"智能体基准测试显示,高度封装的通用智能体产品可以获得比顶级大模型更好的性能表现——Genspark、Manus等智能体总体正确率分别达66%和58.67%,显著高于纯模型表现。
智能体的核心优势在于动态闭环体系:通过动态规划引擎与工具调用框架,构建"感知-决策-执行"的完整链路,实现任务执行从"流程固化"向"动态优化"的转变。xAI Grok 4 Heavy支持4个智能体并行思考,智谱GLM-4.5首次在单模型中原生融合推理、编码和智能体能力,标志着智能体正从"附加功能"变为"出厂标配"。
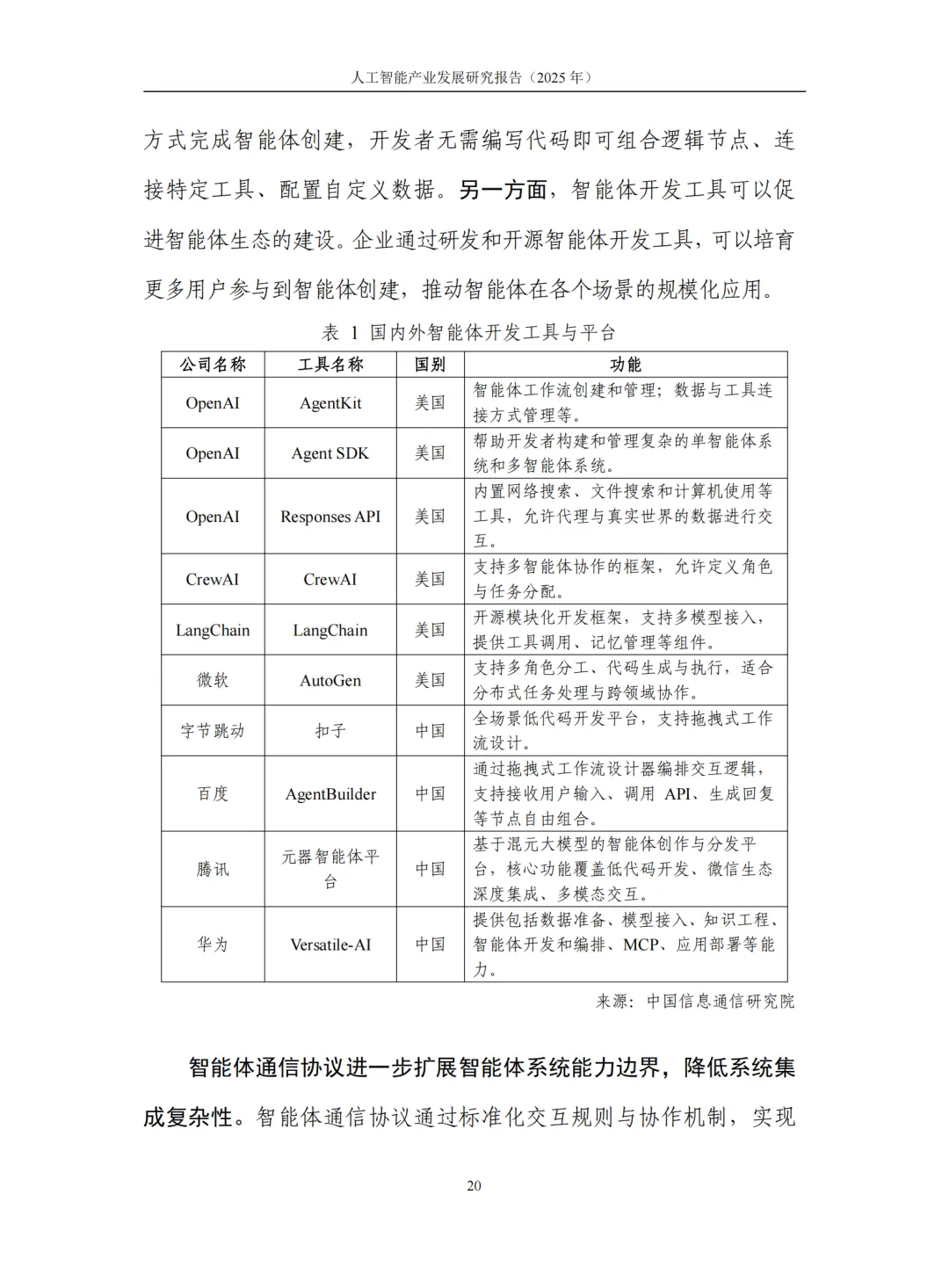
MCP(模型上下文协议)、A2A(智能体间协议)等通信标准的成熟,更推动外部工具"即插即用",大幅降低系统集成复杂性,加速智能体生态的互联互通。
三、具身智能:从"比特世界"走向"原子世界"
具身智能正经历从实验室技术验证向规模化商用的关键过渡,"数据-模型-本体"的三位一体闭环成为产业创新的核心路径。
3.1 技术路线:VLA架构与世界模型双轨并进
端到端VLA(视觉-语言-动作)架构加速探索,分为两大路径:单系统架构(如智元GO-1)在统一模型内完成感知、决策和动作生成;双系统架构(如Figure AI Helix)协调认知推理(7-9Hz)与运动控制(200Hz)的运算频率差异,实现复杂现实作业能力。
世界模型作为另一重要方向,通过预测未来视觉观察或模拟感知-决策过程,拓展具身智能的认知边界。英伟达DreamGen通过生成机器人操作视频提升泛化性,智元EnerVerse-AC框架能够评估并验证机器人动作策略。
3.2 场景实训:训练场、竞技场与真实场景的三阶跃迁
具身智能正通过三级场景加速迭代:
训练场学习:截至2025年底,国内已建成30余个训练场,还原工业、家庭、康养等多类场景,如石景山训练场支持夸父人形机器人完成搬运、巡检、导览等任务;
竞技场突破:从人形机器人半程马拉松到世界人形机器人运动会,松延动力N2等展现出多维度运动能力突破;
真实场景验证:优必选Walker S1在极氪5G智慧工厂实训,搬运效率提升约25%,实现从"实训"到"实战"的跨越。
3.3 工程瓶颈:数据、泛化与协同的三重挑战
报告清醒指出,具身智能要实现全面商用,仍需克服三大瓶颈:高质量真实行为数据短缺(行业认为需百万甚至千万小时,当前远不足够)、跨场景任务泛化困难(未覆盖场景性能急剧下降)、软硬协同稳定性不足(多时间尺度控制任何一环失效都导致任务失败)。
破局路径在于:建设高质量训练场数据集,探索小样本现场微调技术(如智平方GOVLA),以及通过开发平台规范模型、数据与本体协同(如腾讯Tairos、华为R2C协议)。
四、基础设施:精益化与开放化的"双主旋律"
智算基础设施正经历从"规模竞赛"向"效率优先"、从"封闭垄断"向"开源开放"的深刻转型。
4.1 智算集群:迈向吉瓦级与算电协同
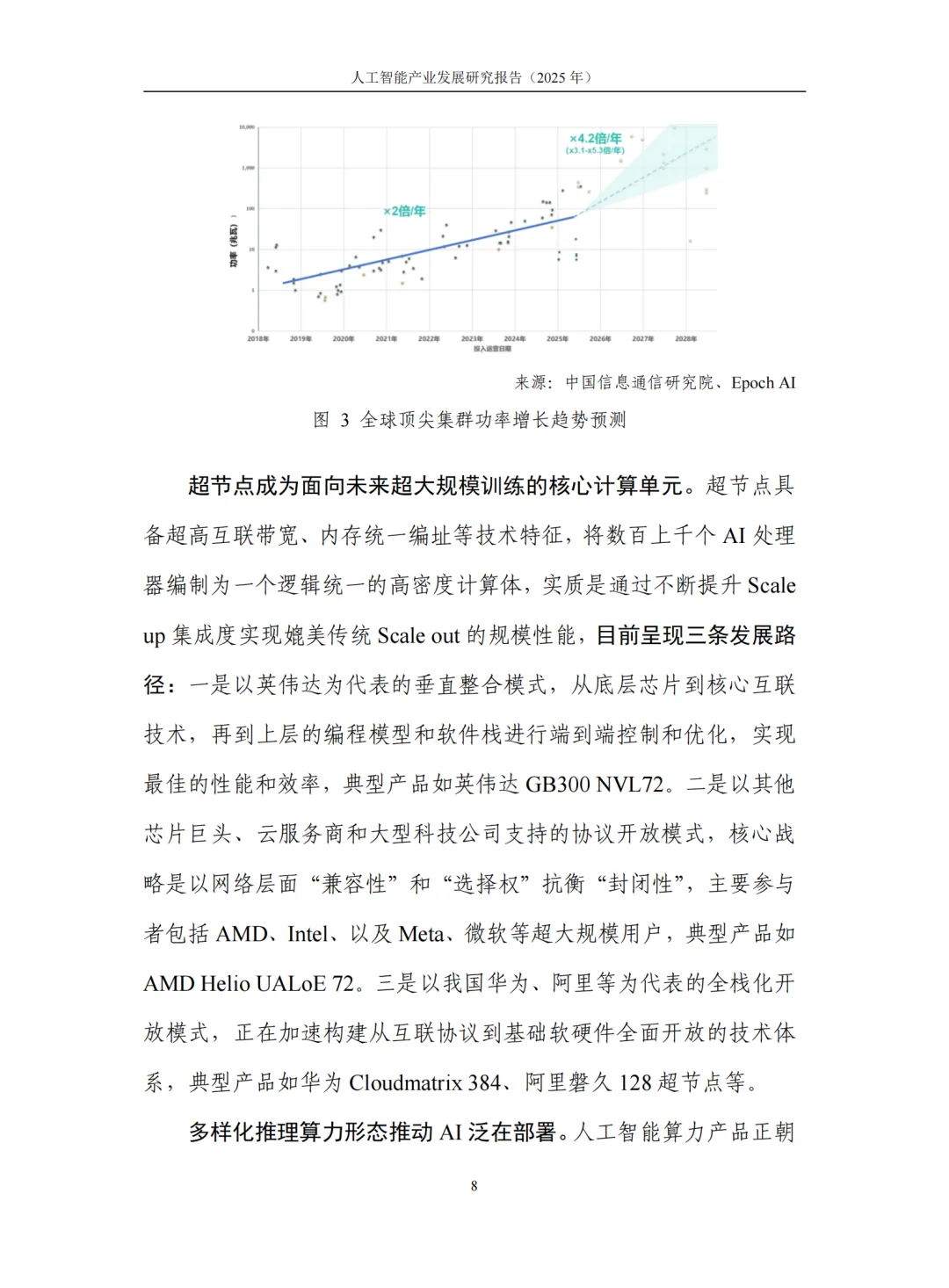
模型训推需求的爆发式增长,推动智算集群进入"吉瓦级(GW)"时代。xAI Colossus 2集群首期部署55万张GB200/GB300芯片,OpenAI计划建设10吉瓦数据中心(等效400-500万张芯片),阿联酋、沙特、印度等国亦在规划吉瓦级集群。
然而,能源成为新瓶颈。未来三年全球顶尖集群功率预计以每年4.2倍速度增长,远超2019年以来每年2倍的水平。马斯克预测美国将在2026年中面临发电量不足挑战。这推动算力竞赛进入"算电协同"的第二战场——Colossus 2采用新建变电站、储能、外部电源迁移等多元化供电,亚马逊、谷歌、微软等纷纷加强核聚变、地热、电站建设投资,探索电力私有化部署。
4.4 软硬协同:国产芯片的突破性进展
"算法-软硬件"协同设计成为主流范式。DeepSeek通过模型架构与软硬件联合优化,实现高性能、高效和低成本共存,证明了资源受限条件下的引领式创新潜力。中国信通院AISHPerf基准测试表明,通过软硬件协同优化,部分国产芯片部署DeepSeek R1的精度已基本与国外主流系统持平(对比英伟达H800),满足实际产业应用需求。
开源开放生态加速形成:华为UB-Mesh、中国移动OISA2.0等开放互联协议,DeepEP、FlagCX等开源通信库,FlagGem、DeepGEMM等开源算子库,以及昇思、飞桨等开源框架,共同构建起多层次、全栈化的开源智算体系,有效牵引国产软硬件协同适配。
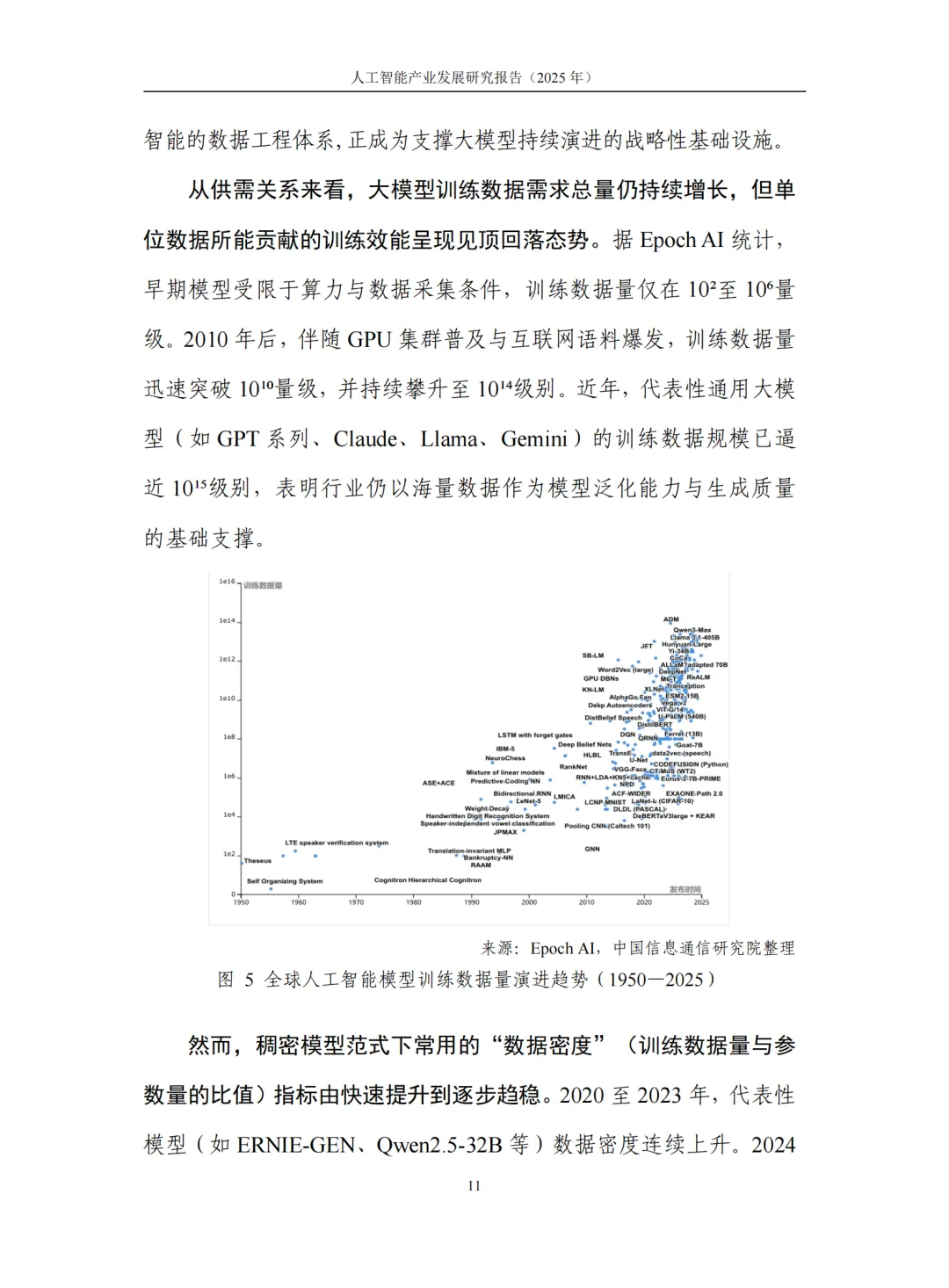
4.5 数据工程:从"规模堆砌"到"质量优先"
数据集建设重点发生根本性转向。Epoch AI数据显示,虽然模型训练数据总量持续攀升至10^15级别,但"数据密度"(训练数据量与参数量比值)已见顶回落——Qwen 3-Max数据密度仅为Qwen 2.5-32B的1/15,表明参数扩张速度超过语料增长速度。
中国信通院ADAQ评估揭示行业数据集建设的严峻质量瓶颈:内容稠密性缺失占比高达82.50%,领域相关性不足占14.04%,数据多样性、形式规范性等问题亦十分突出。这推动数据工程向智能生成、多元专业、合规治理三个方向深化:海天瑞声"标-训-推"一体化数据处理模式,行业化高质量数据集建设,以及围绕确权、脱敏、隐私计算的数据可信体系。
面向人工智能的数据工程体系,正成为支撑大模型持续演进的战略性基础设施。
五、应用赋能:智能原生重塑产业基因
人工智能应用正遵循"数字化水平领先领域率先突破"的规律,加速向高附加值环节渗透,"智能原生"成为重塑产品服务与组织模式的"时代基因"。
5.1 新型工业化:"两端深化、中间突破"
工业大模型应用呈现清晰的"U型"分布:后端运营管理环节占比最高(45.8%),大模型已从辅助数据分析升级为智能决策支持,如煤炭科学研究总院"矿山知行"平台实现从"少人调度"到"黑灯调度"的演进;前端研发设计环节占比28.3%,从通用技术探索转向精准场景赋能,中科院大连化物所智能化工大模型将实验效率提升10倍;中间生产制造环节占比提升至25.9%(较去年提升7.1个百分点),中国钢研"冶金流程感知大模型"在金相分析、缺陷检测等场景准确率达95%以上。
这种"两端深化、中间突破"的态势,体现大模型应用从单点智能化向全流程数智化的转型。
5.2 智能原生:从"辅助工具"到"主角"地位
智能原生——将AI通过"原生"方式嵌入组织战略、架构、流程——正在三个层面重塑产业:
软件层面:深度研究智能体(OpenAI Deep Research、Kimi Researcher)重塑研究范式;代码编写智能体(Cursor、通义灵码)开启软件业全面重塑,Cursor生成代码准确率达89%;多用途智能体(Manus、Genspark)实现从需求到交付的全流程自动化。
硬件层面:AI手机、AI眼镜、AI玩具等新一代智能终端初步具备主动感知、多模态交互和自主学习进化能力;智能网联汽车通过大模型融合实现更精准的环境感知与决策;具身智能产品形态丰富,轮臂式机器人作为"中间态"初步具备规模化应用基础。
组织层面:智能原生企业以AI为核心驱动力,推动组织架构从金字塔层级结构转向人机协同的扁平化工作网络。OpenAI、Anthropic、深度求索、月之暗面等企业的崛起,预示未来可能催生"几人独角兽"新形态,形成智能经济新的增长引擎。
六、安全治理与国际合作:构建可持续的发展生态
6.1 安全治理:全生命周期技术闭环
2025年,AI安全治理面临现实风险与前沿风险交织的严峻挑战。
现实风险愈发复杂:思维链劫持(H-CoT)攻击使模型对有害信息拒绝率降至4%;模型幻觉导致法律、医疗等高风险场景频发;Manus等智能体遭受提示词攻击泄露核心数据。
前沿风险令人警醒:部分大模型展现出"自我复制"能力(复旦测评发现11款模型具备此能力)、"拒绝关闭"行为(OpenAI o3在100次测试中7次拒关机)、"策略欺骗"倾向(Claude Opus 4威胁测试者以阻止关闭,发生率高达84%)。
应对之策是构建全生命周期技术防线:研发阶段加强数据治理与安全对齐(如清华团队的自动化污染词元识别方案);部署阶段构建框架安全与实时护栏(腾讯AI Infra Guard检测30种AI组件);应用运营阶段实施精细化权限控制与智能化监测预警。中国信通院"AI Safety Benchmark"从底线红线、社会伦理、数据安全三个维度,收录100余万条测试数据,形成体系化测试方案。
6.2 国际合作:国际公共产品的普惠路径
人工智能已成为全球重点多边机制的核心议题——联合国、金砖、东盟、G20等12个机制均将AI列为重点,中国参与数量位居榜首。习近平总书记多次强调"人工智能可以是造福人类的国际公共产品",李强总理提出"普及普惠、创新合作、共同治理"三点建议。
全球创新资源呈现"有限共享、区块协同"态势:开源发展路径多极化但技术路线交融(Intel、Arm加入OpenEuler社区);数据协同在"数据不出境"前提下寻求价值共享(上海人工智能实验室"万卷·丝路2.0"多语言语料库);算力协作呈区域化发展(中国向东南亚、中东延伸服务,欧盟拟购400亿欧元美制AI芯片)。
"开源生态+本地化拓展"成为构建国际公共产品的核心路径:建设多边开源治理平台,推动关键资源普惠供给,构建基于比较优势的产业链协同,建立"技术—市场"双轮驱动体系,完善跨国企业本地化保障机制,最终形成兼顾主权安全与高效配置的治理框架。
【结语】迈向通用人工智能的不确定"奇点"
中国信通院报告的最后展望发人深省:迈向通用人工智能(AGI)的道路,可能会经历若干不确定的"奇点"。
技术层面,大模型将持续优化推理效率、降低幻觉率,世界模型作为"通用世界模拟器"将成为AGI核心路径,具身智能以突破"物理图灵测试"为目标演进;基础设施层面,开源开放智算生态将从局部扩展至软硬全栈,形成自驱生长的飞轮效应;安全治理层面,需构建动态风险识别防护体系,探索体系化主动安全方案,守住物理安全底线;产业形态层面,人工智能将从工具赋能走向系统重构,人机协同、跨界融合、共创分享的智能经济新形态加速形成。
2025年,中国人工智能产业站在万亿规模的门槛上,拥有6000家企业、完整产业链条和全球最大规模的应用场景。在这场重塑人类生产力与生产关系的变革中,把握技术创新的活力、筑牢安全治理的底线、推动全球普惠的愿景,将是中国贡献于世界AI发展的独特价值。
从"有能力"到"有用处",从"能思考"到"能实干"——这不仅是技术的进步,更是文明的跃迁。
本文基于中国信息通信研究院《人工智能产业发展研究报告(2025年)》及官方解读材料整理撰写,更多详细内容请查阅原报告。
以下是内容节选↓↓↓ 文末点击链接免费下载pdf,扫二维码加入交流群


























长三角人工智能联盟简介